云端数据分布式存储的分配方法与流程
1.本发明属于资源分配技术领域,具体涉及为云端数据分布式存储的分配方法。
背景技术:
2.如果将档案资料储存于本地端,有需要时再将相应的资料上传至云端服务器进行计算,则当档案资料过多时,会导致本地端的储存空间的不足,从而需要增加硬件成本。因此,传统的本地端装置储存方式渐渐被云端储存方式所取代,以降低成本及提升存储效能。云端储存方式,是将档案资料储存于云端,有需要时再通过网络进行下载及存储。
3.云端存储,多采用分散式架构。该架构中,通常系统都会进行档案复本的复制,以减少延迟回应使用者请求的时间,并减少频宽的消耗。因此,在分散式架构中复制策略中,通常有静态复本复制与动态复本复制二种。对于静态复本复制,其将复本放置在固定节点上,并不会因应环境变化来改变复本位置及复本数量。对于动态复本复制,其会依照环境变化与使用者需求来动态配置档案位置及复本数量,以解决单一服务节点负载过重的问题,进而达到服务节点间的负载平衡。
4.针对动态复本复制,不仅能改善资料可用性,还可改善系统的存取效能。但是过度的复本将造成资源浪费、占用空间以及增加管理上成本的负担。
5.因此,有必要在动态复本复制的过程中,引入负载平衡机制,从而减少系统负担并提升系统的效能。
技术实现要素:
6.鉴于上述现有技术的不足之处,本发明的目的在于提供云端数据分布式存储的分配方法。
7.为了达到上述目的,本发明采取了以下的技术方案。
8.云端数据分布式存储的分配方法,包括以下步骤:步骤s1,建立云端平台;所述云端平台,包括使用者端、管理节点、主节点、子节点;使用者通过使用者端登录云端平台并发送存储服务的请求;管理节点接收来自使用者端的请求,并将该请求传送给主节点;所述主节点,将档案进行分类并设定档案复本数量;主节点将档案复本分配到子节点中,并记录档案复本状态;步骤s2,阻塞预筛选机制:主节点筛选出阻塞机率bpi小于阻塞机率阈值t
bp
的子节点,组成合格节点集合;步骤s3,引用队列负载平衡机制:在合格节点集合中,主节点筛选出具有最大的引用队列剩余空间数rq的子节点,作为最佳的档案复本存储的子节点,进行档案复本的存储;如果该筛选出的子节点未拥有此请求的档案复本时,则将该子节点作为备援节点,并将档案复本新增至此子节点。
9.所述管理节点信号连接有使用者端和主节点,是负责接收和回应使用者端的任务请求的中继站,并管理使用者端和主节点之间的沟通;
所述主节点内设有记录档案复本状态的元数据记录模块;所述子节点,是档案复本放置位置的服务节点;所述主节点和子节点信号连接形成分布式存储结构。
10.进一步,步骤s1中,所述主节点,将预存储时间超过储存时间阈值的档案归为长期存储档案,否则归为短期存储档案;将长期储存档案的档案复本数量设定为5份;将短期储存档案的档案复本数量设定为3份。
11.进一步,步骤s2中,首先,计算每个子节点的请求到达率λi,即;其中,pj表示档案复本被存储的热门度,为子节点中的档案复本被存取次数与档案复本在所有子节点中的被存取次数总数的比值;rj表示档案复本数;λ表示达到率,为总请求中到达由所有子节点的请求数量占比;然后,计算每个子节点的阻塞机率bpi,即;其中,τi表示延迟时间,请求从使用者端发出后,主节点针对不同请求进行档案的分类和档案复本的分配,档案复本存储于子节点的总时间;ci表示子节点的存储区块;接着,计算阻塞机率阈值t
bp
,阻塞机率阈值t
bp
为所有子节点的阻塞机率的平均值。
12.云端数据分布式存储的分配方法,还包括步骤s4,档案复本更新机制:判断轮询的时间周期是否到达;计算当前请求的档案的复本数比率request
nr
;预先设定复本数比率阈值rr;判断当前档案的热门程度;然后执行档案复本的新增、删除或者搬移的动作;其中,计算当前请求的档案的复本数比率request
nr
,即;nri表示当前请求档案的复本数量,tnri表示所有档案复本的数量。
13.进一步,判断当前档案的热门程度,方式如下:计算复本数比率阈值tp;如果本轮询的时间周期中,若一个档案的复本存取次数大于复本数比率阈值tp,则该档案为热门档案;否则该档案为冷门档案;复本数比率阈值tp是历史记录的存取次数平均值,即;其中,i表示轮询的时间周期序号;af
n-i
表示档案的历史存取次数,tfi表示档案种类数。
14.档案复本更新机制,具有6种情况:情况1:轮询的时间周期未到达;当前请求的档案的复本数比率request
nr
大于复本数比率阈值rr;档案的复本存取次数大于复本数比率阈值tp;此时,将档案复本搬移到新的子节点,且新的子节点阻塞机率低于旧的子节点的阻塞机率;情况2:轮询的时间周期未到达;当前请求的档案的复本数比率request
nr
大于复本数比率阈值rr;档案的复本存取次数不大于复本数比率阈值tp;此时,计算出各个子节点阻塞机率,再从拥有此档案复本且阻塞机率最高的子节点中,将档案复本删除至三份;情况3:轮询的时间周期已经到达;当前请求的档案的复本数比率request
nr
不大于复本数比率阈值rr;档案的复本存取次数大于复本数比率阈值tp;此时,新增一个新的复本
至bp值最低的子节点;情况4:轮询的时间周期已经到达;当前请求的档案的复本数比率request
nr
不大于复本数比率阈值rr;档案的复本存取次数不大于复本数比率阈值tp;此时,将该档案复本删除至三份;但若档案复本不足三份,则维持原有档案复本数;情况5:轮询的时间周期已经到达;当前请求的档案的复本数比率request
nr
大于复本数比率阈值rr;档案的复本存取次数大于复本数比率阈值tp;此时,将档案复本搬移到新的子节点,且新的子节点阻塞机率低于旧的子节点的阻塞机率;情况6:轮询的时间周期已经到达;当前请求的档案的复本数比率request
nr
大于复本数比率阈值rr;档案的复本存取次数不大于复本数比率阈值tp;此时,计算出各个子节点阻塞机率,再从拥有此档案复本且阻塞机率最高的节点中,将档案复本删除至三份。
15.云端数据分布式存储的分配方法,还包括步骤s5,主节点,在元数据记录模块记录档案复本状态,并将档案复本状态通过管理节点传送给使用者端。
16.传统的更新方法大都采用周期时间进行更新,这将会因为需求过多而卡在队列当中等待存储,导致阻塞机率的提高及回应时间的延迟。
17.本方案,在云端平台提出了具有递进关系的三个档案存储配置机制。前二机制为阻塞预筛选机制、引用队列负载平衡机制,主要根据子节点的负载来为使用者提供合适服务节点,在子节点阻塞发生前快速地回应请求来减少请求等待的时间并达到初步的负载平衡。然后,通过第三个的档案复本更新机制,进行动态复本配置,根据档案复本热门程度来控制复本的数量与位置,及时分散档案热度,以维持节点间负载平衡,进而减少系统负担并提升系统的效能。
附图说明
18.图1是本发明的结构示意图;图2是步骤s2和步骤s3的流程图;图3是步骤s4的流程图。
具体实施方式
19.下面结合附图,对本发明作进一步详细说明。
20.云端储存方式,主要有大块存储和档案存储两种方式。
21.对于大块存储,是指一份大档案划分成多个64mb为单位的大块,并将大块分散储存至不同的节点中,当使用者储存文件时,会分散存储各处的大块以增加读取的性能,进而降低单一节点因档案太大导致存储延迟;这种方式,需要建立动态管理与配置机制,以避免单一大块热门程度过高导致节点阻塞机率的提升。另外,由于大块存储将档案分割且分散至不同节点中,可能会因为其中一个大块损毁造成整份文件不可使用。
22.对于档案存储,是指一份完整档案或复制多份档案分散储存至不同节点中。
23.由于云端计算环境中,储存需求大多是以小档案为主。对10000份档案进行统计,得到平均的档案大小为35.6mb,小于64mb。若采用大块存储的方式,将造成存储空间的浪费。因此,有必要针对档案存储,研究其档案存储配置方法。
24.云端数据分布式存储的分配方法,包括以下步骤:
步骤s1,建立云端平台。
25.图1是本发明的结构示意图;如图1所示,所述云端平台,包括使用者端、管理节点、主节点、子节点;所述管理节点信号连接有使用者端和主节点,是负责接收和回应使用者端的任务请求的中继站,并管理使用者端和主节点之间的沟通。
26.所述主节点信号连接有子节点,内设有元数据记录模块,进行档案的分析和分类,并分配档案复本到子节点中。
27.所述子节点,是档案复本放置位置的服务节点。所述主节点和子节点信号连接形成分布式存储结构。
28.使用者通过使用者端登录云端平台并发送存储服务的请求;管理节点接收来自使用者端的请求,并将该请求传送给主节点;所述主节点,根据储存时间将档案分为长期存储档案和短期存储档案:设定储存时间阈值,将预存储时间超过储存时间阈值的档案归为长期存储档案,否则归为短期存储档案。
29.长期储存档案,为重复使用率较高及重要程度较高的档案,例如:天灾资料、天文学资料等。为了预防较热门档案产生节点阻塞,则分配档案复本数量,来分散档案的热度程度,以提高档案可用性。将长期储存档案的档案复本数量设定为5份,以保证达到较高可用性。
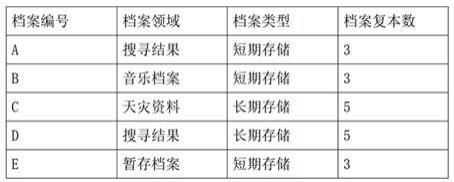
30.短期储存档案,为重要程度较低与重复使用率较低的档案,需要较少的档案来避免过多的复本造成资源上浪费,例如:图片、音乐、网页资料等。将短期储存档案的档案复本数量设定为3份,以维持基本的可用性。
31.主节点将档案复本分配到子节点中,并在元数据记录模块记录档案复本状态;档案复本状态包括档案复本名称、档案复本数量、档案复本存取次数、档案复本所在的子节点位置;当轮询的时间周期更新抵达后,汇总每个档案在各子节点的被存取次数并存入元数据记录模块中。
32.步骤s2,阻塞预筛选机制:主节点筛选出阻塞机率bpi小于阻塞机率阈值t
bp
的子节点,组成合格节点集合。
33.首先,计算每个子节点的请求到达率λi,即;其中,pj表示档案复本被存储的热门度,为子节点中的档案复本被存取次数与档案复本在所有子节点中的被存取次数总数的比值;rj表示档案复本数;λ表示达到率,为总请求中到达由所有子节点的请求数量占比。
34.然后,计算每个子节点的阻塞机率bpi,即;其中,τi表示延迟时间,请求从使用者端发出后,主节点针对不同请求进行档案的分类和档案复本的分配,档案复本存储于子节点的总时间;ci表示子节点的存储区块。当子节点的存储区块ci已经没有空间存放其它档案时,则新进的档案就必须等待,此现象为阻塞。
35.接着,计算阻塞机率阈值t
bp
,阻塞机率阈值t
bp
为所有子节点的阻塞机率的平均值;
主节点选出阻塞机率bpi小于阻塞机率阈值t
bp
的子节点。
36.图2是步骤s2和步骤s3的流程图;如图2所示,阻塞预筛选机制,选出具有较低阻塞的子节点进行服务,以避免子节点的阻塞而导致的封包遗失。如果子节点负载太高,则会造成子节点工作效能降低。若子节点所负担的工作量太少,则会浪费节点的能力。因此,通过本阶段的调整,让整个系统得到初步的负载平衡,同时降低系统延迟所造成的请求遗失,以提高整体系统的效能。
37.步骤s3,引用队列负载平衡机制:在合格节点集合中,主节点筛选出具有最大的引用队列剩余空间数rq的子节点,作为最佳的档案复本存储的子节点,进行档案复本的存储;如果该筛选出的子节点未拥有此请求的档案复本时,则将该子节点作为备援节点,并将档案复本新增至此子节点以提供服务。
38.图2是步骤s2和步骤s3的流程图;如图2所示,步骤s3考察各个子节点的引用队列剩余空间数rq,进而选出最佳的子节点来存放复本以平衡所有子节点中的工作负载,以避免任务分配不均的问题。若最佳的子节点中并没有发现请求的档案复本,则立即新增该档案复本至最佳的子节点,以提供使用者存储。本机制调整任务的分派以确保任务的平均分配。
39.步骤s4,档案复本更新机制:判断轮询的时间周期是否到达;计算当前请求的档案的复本数比率request
nr
;预先设定复本数比率阈值rr;判断当前档案的热门程度;然后执行档案复本的新增、删除或者搬移的动作。
40.其中,计算当前请求的档案的复本数比率request
nr
即;其中,nri表示当前请求档案的复本数量,tnri表示所有档案复本的数量。
41.其中,预先设定复本数比率阈值rr。在低度工作量环境时,rr值若在20%以下,则档案复本数量将会不足3份,将造成档案复本可用性不足的问题,而若rr值设置在40%以上时,则会产生档案复本数量过多,而造成成本上的花费。因此,将预设的复本数比率rr可以订定为20%、30%及40%。
42.其中,预测档案的热门程度,方式如下:计算复本数比率阈值tp;如果本轮询的时间周期中,若一个档案的复本存取次数大于复本数比率阈值tp,则该档案为热门档案;否则该档案为冷门档案。复本数比率阈值tp是历史记录的存取次数平均值,即;其中,i表示轮询的时间周期序号;af
n-i
表示档案的历史存取次数,tfi表示档案种类数。
43.图3是步骤s4的流程图;如图3所示,档案复本更新机制,具有6种情况:情况1:轮询的时间周期未到达;当前请求的档案的复本数比率request
nr
大于复本数比率阈值rr;档案的复本存取次数大于复本数比率阈值tp。
44.此时表示,目前档案复本热门程度较高,而且档案复本数量也到达设定的rr值。因此,将档案复本搬移到新的子节点,且新的子节点阻塞机率低于旧的子节点的阻塞机率。档案复本从高bp值的子节点,搬移至低bp值较的子节点,以降低阻塞机率。
45.情况2:轮询的时间周期未到达;当前请求的档案的复本数比率request
nr
大于复本数比率阈值rr;档案的复本存取次数不大于复本数比率阈值tp。
46.此时表示,档案复本热门程度较低,则档案复本可能已经存放一段时间。因此,计
算出各个子节点阻塞机率,再从拥有此档案复本且阻塞机率最高的子节点中,将档案复本删除至三份,来维持其基本的可用性。
47.情况3:轮询的时间周期已经到达;当前请求的档案的复本数比率request
nr
不大于复本数比率阈值rr;档案的复本存取次数大于复本数比率阈值tp。
48.此时表示,档案复本热门程度较高,但是目前的复本数量不够支持整体环境的可用性。因此,新增一个新的复本至bp值最低的子节点,以降低阻塞发生的机率。
49.情况4:轮询的时间周期已经到达;当前请求的档案的复本数比率request
nr
不大于复本数比率阈值rr;档案的复本存取次数不大于复本数比率阈值tp。
50.此时,轮询的时间周期到达时,将该档案复本删除至三份,以减少冗余的档案复的占用空间;但若档案复本不足三份,则维持原有档案复本数,以减少任何成本上的花费。
51.情况5:轮询的时间周期已经到达;当前请求的档案的复本数比率request
nr
大于复本数比率阈值rr;档案的复本存取次数大于复本数比率阈值tp。
52.此时表示,目前档案复本热门程度较高且档案复本数量也达到一定比率。因此,将档案复本搬移到新的子节点,且新的子节点阻塞机率低于旧的子节点的阻塞机率。档案复本从高bp值的子节点,搬移至低bp值较的子节点,以降低阻塞机率。
53.情况6:轮询的时间周期已经到达;当前请求的档案的复本数比率request
nr
大于复本数比率阈值rr;档案的复本存取次数不大于复本数比率阈值tp。
54.此时表示,请求队列里并没有太多的请求任务,且各节点中存在冗余的档案复本。因此,计算出各个子节点阻塞机率,再从拥有此档案复本且阻塞机率最高的子节点中,将档案复本删除至三份,维持可用度并降低储存空间。
55.档案复本更新机制,对档案复本数量及热门程度进行评估,进而配置档案复本的位置及档案复本的数量的更新,来保持各子节点间持续的负载平衡及提升整体的存储效率。
56.档案复本更新机制中计算的阻塞机率,与阻塞预筛选机制中计算的阻塞机率,作用不同:阻塞预筛选机制中,阻塞机率bpi是只针对计算的子节点,随后进行挑选bpi值小于阻塞机率阈值t
bp
的子节点。
57.档案复本更新机制中,根据所计算的bpi值不同,再通过复本数比率阈值rr及复本数比率阈值tp的评估来进行档案复本的动态配置,经过档案复本重新再配置过的子节点,将可有效降低阻塞机率,进而达到工作负载的平衡。
58.步骤s5,主节点,在元数据记录模块记录档案复本状态,并将档案复本状态通过管理节点传送给使用者端,方便使用者进行档案复本的存取。
59.模拟本方案的运行环境,具体如下:假设每5ms为一个时间周期间隔;子节点编号为n1~n
10
;存储的档案编号为a~e。
60.步骤s1,建立云端平台;使用者通过使用者端登录云端平台并发送存储服务的请求;管理节点接收来自使用者端的请求,并将该请求传送给主节点;所述主节点,根据储存时间将档案分为长期存储档案和短期存储档案。
61.若档案类型属于长期存储档案,则需要分配较多的档案复本数,反之,短期存储档案,则应分配较少的档案复本数。分别结果如表1所示。
62.表1为档案类型产生的档案复本数统计表。
63.随后,通过阻塞预筛选机制和引用队列负载平衡机制,筛选出较佳的子节点来提供档案的存储。而档案复本状态记录在元数据记录模块中,如表2所示。
64.表2为时间点t1下的档案复本在各节点的被存取次数统计表。
65.当轮询的时间周期更新抵达后,汇总每个档案在各子节点的被存取次数并存入元数据记录模块中,如表3所示。例如,对于档案编号为a的档案,汇总其在子节点n2、n7、n9进行被存取次数为30。
66.表3为在时间点t1档案被存取次数的汇总表。
67.步骤s2,根据每个档案在各子节点的被存取次数的汇总信息,计算每个子节点的请求到达率λi及每个子节点的阻塞机率bpi。
68.λ表示达到率,为总请求中到达由所有子节点的请求数量占比。假设总请求的数量有300个,真正到达子节点的只有235个,其他的请求可能在传送时,因为封包遗失或等待时间过长等原因,而导致传送失败。本模拟案例中,将达到率λ设定为0.2。
69.表4为每个子节点的请求到达率λi的汇总表。
70.τi表示延迟时间,请求从使用者端发出后,主节点针对不同请求进行档案的分类和档案复本的分配,档案复本存储于子节点的总时间。为了比较存储效能,需要统一环境。假设,首先存储服务的请求通过主节点进行分类时所花费时间间隔为1s,随后主节点针对不同请求进行档案复本数分配的时间间隔为1s,最后分配档案复本至不同的子节点的队列中的时间间隔为1s。因此,假设请求到所有子节点的延迟时间为3s。
71.ci表示子节点的存储区块;假设ci为3。
72.表5为每个子节点的阻塞机率bpi的汇总表。
73.计算阻塞机率阈值t
bp
,阻塞机率阈值t
bp
为所有子节点的阻塞机率的平均值;t
bp
=(0.0001835+0.000412+0.000685+0.0000006+0.000069+0.000057+0.000565+0.000434+0.000052+0.000007)/10=0.000246。
74.主节点选出阻塞机率bpi小于阻塞机率阈值t
bp
的子节点(n1、n4、n5、n6、n9和n
10
),进行档案复本的存储。
75.步骤s3,引用队列负载平衡机制:在阻塞机率bpi小于阻塞机率阈值t
bp
的子节点中,筛选出具有最大的引用队列剩余空间数rq的子节点,作为最佳的档案复本存储的子节点;如果该筛选出的子节点未拥有此请求的档案复本时,则将该子节点作为备援节点,将档案a复本新增至此子节点以提供服务。
76.假设目前有档案a有请求进来,则会先找寻拥有档案a复本子节点n2、n7、n9。若假设目前子节点n2、n7、n9的阻塞机率bp值大于阻塞机率阈值t
bp
,则表示子节点n2、n7、n9目前为繁忙状态,若再次选择可能导致阻塞发生,因此,选择阻塞机率bp最小且剩余空间最多的子节点n4作为备援节点,进而将档案a复本新增至此以提供服务,如表6所示。
77.表6为每个子节点的阻塞机率bpi和引用队列剩余空间数rq汇总表。
78.步骤s4,档案复本更新机制。
79.对档案复本的热度重新评估,计算当前请求的档案的复本数比率,即;其中,nri表示当前请求档案的复本数量,tnri表示所有档案复本的数量。
80.表7为每个档案的复本数比率复本数比率。
81.预设的复本数比率阈值rr=20%。
82.如果当前请求的档案的复本数比率request
nr
大于复本数比率阈值rr,则触发更新,确认当前档案的热门程度,并进行档案复本的调配工作。
83.否则,在下一个轮询的时间周期,重新进行本步骤。
84.表8为当前各档案复本存取次数与历史的存取次数平均值的对比表。
85.参考表7和表8,若假设rr值定为20%,而目前请求为档案c,但发现目前档案c计算
出的复本数比率request
nr
大于复本数比率阈值rr,则触发更新来确认目前档案复本热门程度,而由于档案c目前存取次数为10,相较于历史纪录的复本数比率阈值12.6低,则表示目前档案复本数较高,但是复本的热门程度较低,则表示太多冗余的档案复本占用空间。因此,进行档案复本的更新,将复本数量删除至三份来维持基本的可用性。
86.而若假设目前请求为档案a,然而目前周期抵达后,发现目前复本数比率request
nr
计算后小于订定的复本数比率阈值rr,则进一步确认目前档案复本热门程度,档案a为存取次数为13,较表9中历史纪录的复本数比率阈值12.6还高,则表示目前档案a为较热门档案,而复本数量较少,可能会导致阻塞发生。因此,通过档案复本的新增来分散档案的热门程度,达到实时降低档案的热门程度以避免节点阻塞发生。
87.如果本轮询的时间周期中,若一个档案的复本存取次数大于复本数比率阈值tp,则该档案为热门档案;否则该档案为冷门档案。表8中,档案a存取次数为13,大于复本数比率阈值tp,则表示档案a为热门档案,反之档案b、档案c、档案d及档案e小于复本数比率阈值tp,则会被归类为冷门档案。
88.步骤s5,主节点,在元数据记录模块记录档案复本状态,并将档案复本状态通过管理节点传送给使用者端,方便使用者进行档案复本的存取。
89.本方案能有效分散节点阻塞机率,并通过阻塞机率选择服务节点,且考虑空间剩余量,避免发生阻塞的情况。本方案不管是在松散或是密集环境中都能够有效配置复本数量及复本位置。
90.可以理解的是,对本领域普通技术人员来说,可以根据本发明的技术方案及其发明构思加以等同替换或改变,而所有这些改变或替换都应属于本发明所附的权利要求的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1