一种数据分发的实现方法、装置、电子设备及存储介质与流程
1.本公开涉及大数据技术领域,具体涉及数据处理领域,尤其涉及一种数据分发的实现方法、装置、电子设备及存储介质。
背景技术:
2.随着互联网中数据量的不断增大,人们对大数据的加工、处理以及转存需求也在不断的增多,这类需求统称为数据分发需求,即根据用户对特定类型数据的需要,从数据源中获取满足要求的数据进行格式转换后,写入到下游存储,以提供给用户订阅、查询或分析。
3.现有技术中通常采用全量数据分发的方式,将数据全量提供给用户,由用户自行订阅处理。但是,全量数据的数据量很大,致使数据处理难度大、资源消耗多,从而数据分发效率低,可靠性差。
技术实现要素:
4.本公开提供了一种数据分发的实现方法、装置、设备以及存储介质。
5.根据本公开的一方面,提供了一种数据分发的实现方法,包括:
6.获取目标数据分发任务;其中,所述目标数据分发任务包括:目标数据抽取子任务、目标数据转换子任务和目标数据存储子任务;
7.在所述目标数据抽取子任务配置的目标数据源未被任一数据分发任务订阅时,订阅所述目标数据源,并从所述目标数据源中抽取目标数据至消息总线;
8.从所述消息总线中深拷贝目标数据,并按照所述目标数据转换子任务配置的数据转换参数对所述目标数据进行格式转换;
9.将格式转换结果加载至所述目标数据存储子任务配置的数据存储中。
10.根据本公开的另一方面,提供了一种数据分发的实现装置,包括:
11.目标数据分发任务获取模块,用于获取目标数据分发任务;其中,所述目标数据分发任务包括:目标数据抽取子任务、目标数据转换子任务和目标数据存储子任务;
12.目标数据抽取模块,用于在所述目标数据抽取子任务配置的目标数据源未被任一数据分发任务订阅时,订阅所述目标数据源,并从所述目标数据源中抽取目标数据至消息总线;
13.目标数据格式转换模块,用于从所述消息总线中深拷贝目标数据,并按照所述目标数据转换子任务配置的数据转换参数对所述目标数据进行格式转换;
14.目标数据加载模块,用于将格式转换结果加载至所述目标数据存储子任务配置的数据存储中。
15.根据本公开的另一方面,提供了一种电子设备,包括:
16.至少一个处理器;以及
17.与所述至少一个处理器通信连接的存储器;其中,
18.所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本公开任一项所提供的数据分发的实现方法。
19.根据本公开的另一方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行本公开所提供的数据分发的实现方法。
20.根据本公开的另一方面,提供了一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行时实现本公开所提供的数据分发的实现方法。
21.根据本公开的技术解决了数据分发效率低的问题,提高了数据分发的效率和可靠性。
22.应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。
附图说明
23.附图用于更好地理解本方案,不构成对本公开的限定。其中:
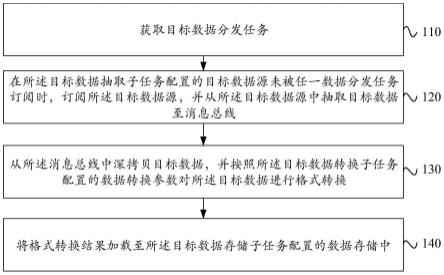
24.图1是根据本公开实施例的一种数据分发的实现方法的流程示意图;
25.图2a是根据本公开实施例的又一种数据分发的实现方法的流程示意图;
26.图2b是根据本公开实施例的一种数据流转的流程示意图;
27.图2c是本公开实施例提供的一种统一数据分发任务的组织简图;
28.图3是根据本公开实施例的一种数据分发的实现装置的结构示意图;
29.图4是用来实现本公开实施例的数据分发的实现方法的电子设备的框图。
具体实施方式
30.以下结合附图对本公开的示范性实施例做出说明,其中包括本公开实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本公开的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。
31.图1是根据本公开实施例的一种数据分发的实现方法的流程示意图,本实施例适用于在实时场景下根据用户对数据的需求,将满足用户需求的数据提供至用户进行使用的情况,该方法可以通过数据分发的实现装置来执行,该装置可以通过软件和/或硬件的方式实现,并集成于电子设备如计算机、服务器或者手机中。具体的,参考图1,该方法具体包括如下步骤:
32.步骤110、获取目标数据分发任务。
33.其中,所述目标数据分发任务包括:目标数据抽取子任务、目标数据转换子任务和目标数据存储子任务。
34.在实际应用场景中数据分发任务可以是大批量数据的分发任务,可以通过服务器集群实现全部数据的数据分发。服务器集群中可以包括多个执行节点,其中,执行节点可以具有任务分发能力,和/或,执行目标数据分发的能力。具体的,目标数据分发任务可以是执行节点a从服务器集群中某个执行节点获取的任务。执行节点a可以执行数据分发的实现方法。
35.目标数据分发任务可以是实时场景下,用户需要特定类型的数据时,根据用户的数据需求,从数据源中获取满足需求的数据,进行数据转换,加载在下游存储,以使用户进行订阅、查询或者分析等数据处理。其中,目标数据抽取子任务可以是从数据源中获取满足需求的数据。目标数据转换子任务可以是对获取的数据进行数据转换。目标数据存储子任务可以是将转换后的数据加载在下游存储。
36.示例性的,满足需求的数据可以是某些统计指标的统计数据、某些域名的访问日志数据、或者某种类型的数据等。通常,用户所需的数据为数据源数据的子集。数据转换可以包括数据的解析、过滤以及格式等处理。下游存储的形式可以是一种或者多种。数据源可以是一个或者多个。
37.步骤120、在所述目标数据抽取子任务配置的目标数据源未被任一数据分发任务订阅时,订阅所述目标数据源,并从所述目标数据源中抽取目标数据至消息总线。
38.其中,目标数据源可以是根据预先配置,当前数据分发任务可以获取数据的数据源。目标数据源未被任一数据分发任务订阅可以理解为目标数据源未被下游用户使用。具体的,目标数据源未被订阅时,用户无法从消息总线中抽取到目标数据源的数据。当目标数据源被订阅时,可以在目标数据源中抽取目标数据至消息总线。
39.示例性的,数据源的数据可以以流式形式写入到消息总线。对于不同类型的数据可以写入至消息总线中的不同消息队列的主题。消息队列的主题的消费程序不具备动态订阅数据源的能力。即在程序运行的初始化阶段如目标数据抽取子任务执行阶段可以订阅数据源,而在程序运行时如目标数据转换子任务执行阶段不可以变更订阅的数据源。
40.具体的,数据抽取可以是根据配置信息,按照对数据的具体需求进行的。示例性的,数据抽取可以采用数据仓库技术(extract-transform-load,etl)程序中的抽取程序实现。在进行数据抽取时,可以对数据进行解析,例如对形如“关键词-数值”(key-value)格式的数据进行解析,生成指定格式的数据,完成数据抽取。在数据抽取时,还可以根据数据内容生成唯一的数据标识信息(id)。其中,数据标识信息可以便于对数据进行追踪处理,例如数据处理失败后对数据进行重新处理。
41.步骤130、从所述消息总线中深拷贝目标数据,并按照所述目标数据转换子任务配置的数据转换参数对所述目标数据进行格式转换。
42.其中,深拷贝可以是指源对象与拷贝对象互相独立,其中任何一个对象的改动都不会对另外一个对象造成影响。在消息总线中深拷贝的目标数据可以是任一被订阅目标数据源中的数据。采用深拷贝的方式可以防止消息总线中的原始数据被修改或者丢失等情况。在一个示例性实施方式中,当目标数据源被订阅时,如果该目标数据源中的数据被多个用户需要时,可以直接从消息总线中获取该被需要的数据。即多个用户无需均从数据源抽取数据,这在实时数据场景中,可以达到数据复用的效果,并且在复用数据时采用深拷贝的方式可以保证数据对于各个用户而言是完全一样的,且某个用户对数据的修改不会影响另一用户。
43.具体的,数据转换可以是根据配置信息,按照对数据的具体需求进行的。示例性的,数据转换可以采用etl程序中的转换程序实现。在进行数据转换时,可以通过配置的转换参数对数据进行格式转换。其中,格式转换可以包括:数据去重、数据过滤、字段转换以及字段增删等。进一步的,数据去重可以是根据数据的id采用布隆过滤器进行的。数据过滤可
以是根据规则进行数据过滤,例如根据metric列表或者host列表等进行数据过滤。字段转换可以支持公式解析。
44.步骤140、将格式转换结果加载至所述目标数据存储子任务配置的数据存储中。
45.其中,数据存储可以是根据配置信息,按照对数据的具体需求进行的。数据存储可以是将目标数据的格式转换结果写入到不同的存储下游。例如,可以写入到kafka(一种分布式发布订阅消息系统)、doris(一种分析型数据库产品)、以及elasticsearch(一种分布式全文搜索引擎)等。示例性的,数据存储可以采用etl程序中的加载程序实现。
46.本公开实施例的技术方案,通过获取目标数据分发任务;其中,所述目标数据分发任务包括:目标数据抽取子任务、目标数据转换子任务和目标数据存储子任务;在所述目标数据抽取子任务配置的目标数据源未被任一数据分发任务订阅时,订阅所述目标数据源,并从所述目标数据源中抽取目标数据至消息总线;从所述消息总线中深拷贝目标数据,并按照所述目标数据转换子任务配置的数据转换参数对所述目标数据进行格式转换;将格式转换结果加载至所述目标数据存储子任务配置的数据存储中,解决了数据分发效率低的问题,通过订阅数据源并将其数据抽取至消息总线实现了数据的复用,提高了数据分发的效率以及可靠性;通过深拷贝目标数据,可以提高数据分发的可靠性;通过配置化的目标数据分发任务即配置抽取、转换以及存储,可以实现不同数据源与数据存储之间的互通,使数据分发具有通用性,节省开发及运维成本。
47.图2a是根据本公开实施例的又一种数据分发的实现方法的流程示意图。本实施例是对上述技术方案的进一步细化,本实施例中的技术方案可以与上述一个或者多个实施方式结合。
48.具体的,为了提高数据分发的通用性,节省开发及运维成本,在本公开实施例的一个可选实施方式中,获取目标数据分发任务,包括:
49.获取所述目标数据分发任务的任务配置信息;其中,所述任务配置信息包括:数据源配置信息、数据转换参数配置信息、以及数据存储配置信息;
50.根据所述任务配置信息,调用预先构建的至少一个抽象函数进行配置,得到目标数据分发任务。
51.为了实现数据的复用,提高数据分发的效率以及可靠性,在本公开实施例的一个可选实施方式中,在所述目标数据抽取子任务配置的目标数据源未被任一数据分发任务订阅时,订阅所述目标数据源,包括:
52.在检测到所述目标数据抽取子任务配置的所述目标数据源未被消费者容器中的任一消费者订阅时,通过所述消费者容器创建目标消费者;
53.触发所述目标消费者订阅所述目标数据源。
54.参考图2a,本公开提供的数据分发的实现方法包括如下步骤:
55.步骤210、获取所述目标数据分发任务的任务配置信息。
56.其中,所述任务配置信息包括:数据源配置信息、数据转换参数配置信息、以及数据存储配置信息。
57.在本步骤中,数据源配置信息可以包括数据源标识、所需数据类型、数据解析信息、数据格式信息、以及数据话题等信息。其中,数据源标识可以包括kafka、doris或者elasticsearch等的标识信息。数据类型可以包括枚举的统计指标数据或者日志数据等。数
据解析信息可以包括数据的纲要(schema)信息,如字段列表、字段顺序、以及分割符等。数据格式信息可以包括内部数据流转的格式定义信息。例如,根据kafka topic中存储的数据格式进行解析,按照key-value的格式信息解析为内部格式。具体可以通过数据序列化和反序列化对常见格式进行支持,当新增格式时,可以通过序列化和反序列化接口实现。数据话题可以包括kafka主题(topic)以及kafka topic组信息。
58.数据转换参数配置信息可以包括数据转换功能的启用信息,以及启用的数据转换功能的功能参数信息。功能参数信息可以包括数据去重信息、数据过滤信息、字段转换信息以及字段增删信息等。其中,数据去重可以是根据数据id实现的,例如根据数据生成的id使用布隆过滤器进行去重。数据过滤可以是通过过滤规则实现的,例如按照metric列表或者host列表等规则进行数据过滤。字段转换可以是通过配置的字段转换规则实现的,例如按照配置进行将“xx-yy-zz”格式的日期字段信息转换为“xx/yy/zz”格式。在字段转换时,可以进行公式的格式转换。字段增删可以是根据配置的字段的增加或者删除实现的。
59.数据存储配置信息可以包括目标存储标识。其中,目标存储标识可以包括kafka、doris或者elasticsearch等的标识信息。
60.步骤220、根据所述任务配置信息,调用预先构建的至少一个抽象函数进行配置,得到目标数据分发任务。
61.其中,抽象函数可以是实现数据分发中数据抽取、数据转换以及数据存储功能的通用函数。将任务配置信息与抽象函数进行组装后,可以通过运行包含任务配置信息的抽象函数,得到目标数据分发任务。
62.在本公开的一个可选实施方式中,根据所述任务配置信息,调用预先构建的至少一个抽象函数进行配置,得到目标数据分发任务,包括:根据所述数据源配置信息,调用抽取抽象函数进行配置,生成抽取函数;根据所述数据转换参数配置信息,调用数据转换抽象函数进行配置,生成转换函数;根据所述数据存储配置信息,调用加载抽象函数,生成加载函数;将所述抽取函数、所述转换函数、以及所述加载函数进行组装,得到目标数据分发任务。
63.其中,本公开提供的数据分发的实现方法可以支持数据分发配置化,从而可以打通数据平台多种数据源和数据存储。具体的,从数据源到数据存储可以定制开发抽象函数如etl程序,实现数据从源至目的地的流转。图2b是根据本公开实施例的一种数据流转的流程示意图。如图2b所示,根据本公开提供的配置化的数据分发的实现方法,可以抽样出统一的抽象函数构成数据分发层,为不同的数据源实现数据抽取程序(抽取层中的抽取抽象函数)、为不同的数据格式提供数据转换程序(转换层中的数据转换抽象函数)、为不同的存储提供数据加载程序(加载层中的加载抽象函数),即通过实现通用的抽取层、转换层和加载层来打通不同数据源和数据存储,可以降低数据分发的实现难度,减少重复性的开发工作,降低程序开发、部署以及运维成本。
64.具体的,抽取抽象函数可以是实现在多个数据源中按照一定的抽取规则抽取数据的函数。例如,抽取抽象函数可以是通用性地在数据源中对指定数据类型的数据进行解析,并按照数据话题抽取至topic组中。即该抽取抽象函数可以对接不同的数据源,在数据源存在更新时无需再次进行程序开发,仅需更新抽取抽象函数所对应的数据源配置信息,无需再次开发数据抽取程序。其中,数据抽取可以是周期性的也可以是持续性的,具体的抽取方
式可以通过抽取抽象函数进行限制。
65.数据转换抽象函数可以是通用性地对数据进行格式转换的函数。其中某项数据转换功能是否启用,仅需通过更改数据转换功能的启用信息即可,无需在数据格式转换不同时,开发新的数据转换程序。
66.加载抽象函数可以是通用性地对数据进行加载存储的函数。其中,对于不同目标存储可以采用同一加载抽象函数,实现数据的加载存储。在更新目标存储时,仅需更新目标存储标识,无需开发新的加载程序。
67.本公开提供的数据分发的实现方法,可以支持配置动态加载,并按照配置信息进行数据分发。具体的,通过数据源配置信息与抽取抽象函数的组装,可以生成抽取函数,执行抽取函数,可以从配置的数据源中抽取数据,并按照配置的数据格式对抽取的数据进行解析,得到目标抽取数据。通过数据转换参数配置信息与数据转换抽象函数的组装,可以生成转换函数,执行转换函数可以对目标抽取数据进行一种或多种的数据转换功能,得到目标转换数据。通过数据存储配置信息与加载抽象函数的组装,可以生成加载函数,执行加载函数,可以简化目标转换数据加载在目标数据存储。
68.在本公开中,可以通过配置页面进行数据分发任务的信息配置。在进行数据分发时,只需在配置页面更新配置信息如数据源配置信息、数据转换参数配置信息以及数据存储配置信息即可,无需对etl程序再进行开发和上线。具体的,在数据分发的配置化中,可以定义表结构、接口规范、提供统一的配置管理与查询接口。
69.进一步的,用户在配置页面发起数据分发任务配置请求时,可以在配置页面进行数据分发任务配置的信息反馈。在配置页面可以获取配置信息,进行数据源配置信息、数据转换参数配置信息、以及数据存储配置信息,分别与抽取抽象函数、数据转换抽象函数、以及加载抽象函数的组装配置,生成目标数据分发任务。
70.步骤230、在检测到所述目标数据抽取子任务配置的所述目标数据源未被消费者容器中的任一消费者订阅时,通过所述消费者容器创建目标消费者。
71.在本公开提供的数据分发的实现方法中,可以通过消费者容器管理消费者的生命周期。其中,消费者可以动态订阅数据源。消费者容器可以根据数据分发任务的标识信息扫描与其相关的所有数据源。消费者容器还可以根据其管理的消费者的订阅情况,确定已经被订阅的数据源。可以根据消费者容器扫描到的数据源与已经被订阅的数据源进行比对,检测目标数据源是否被订阅。可以通过消费者容器创建、更新或者销毁消费者。例如,当检测到目标数据源未被订阅时,消费者容器可以创建消费者,以使目标数据源被消费者订阅。又如,消费者容器可以更新消费者,以使消费者订阅新的数据源。再如,消费者容器可以销毁消费者,以在被订阅数据源失效时,去除对应的多余消费者。
72.步骤240、触发所述目标消费者订阅所述目标数据源。
73.具体的,消费者可以动态订阅数据源中一个主题(topic)的一个分区。消费者可以以异步的方式上报自己的状态至消费者容器。其中,分区可以是数据存储时的最小单元。数据可以包含多个topic,一个topic可以包括多个分区。即分区是topic的一个子集。分区可以是一个日志文件。消息可以采用追加的方式写入分区中。通过对数据源进行无重复性的订阅,可以减轻数据源的压力,实现数据的复用,提高数据分发的效率以及可靠性。
74.步骤250、所述目标数据源中抽取目标数据至消息总线。
75.其中,通过将目标数据源中的数据抽取至消息总线,可以实现数据归集,便于数据复用。
76.步骤260、从所述消息总线中深拷贝目标数据,并按照所述目标数据转换子任务配置的数据转换参数对所述目标数据进行格式转换。
77.步骤270、将格式转换结果加载至所述目标数据存储子任务配置的数据存储中。
78.在本公开实施例的一个可选实施方式中,在将格式转换结果加载至所述目标数据存储子任务配置的数据存储中之后,还包括:当检测到与所述目标数据对应的格式转换结果加载至匹配的数据存储操作失败时,将所述目标数据存储在失败队列中,生成重发数据;响应于数据重发请求,在所述失败队列中获取所述重发数据,进行数据重发。
79.其中,为了提高数据分发的高可靠性,可以对数据的加载情况进行追踪,当数据存储失败时,可以将敌营的数据存储在失败队列中,等待重发。具体的,可以在数据分发系统重启时,检测失败队列中是否有重发数据,如果存在重发数据,可以进行重发数据的重放处理,保证数据分发的高可靠性。或者,可以响应于用户发起的数据重发请求,判断失败队列中是否有重发数据,进行重发数据的重放处理。
80.在本公开实施例的一个可选实施方式中,在将格式转换结果加载至所述目标数据存储子任务配置的数据存储中之前,还包括:获取与所述目标数据分发任务匹配的配置字段;按照所述配置字段,对所述格式转换结果进行数据过滤。
81.具体的,对于不同类型的数据,可以通过某个配置字段来进行分拣,并根据用户需求选择是否进行转发,可以提高数据的精细化处理,可以为不同用户提供定制数据流,还可以提高数据的可定制能力,降低下游系统数据预处理的压力。
82.在上述实施方式的基础上,可选的,在获取目标数据分发任务之前,还包括:获取多个数据类型的原始数据;将所述原始数据以主题的方式存储在kafka topic组中,作为数据源;其中,所述kafka topic组通过异地设置的kafka集群创建得到。
83.其中,kafka topic组可以理解为在异地的两个消费队列集群创建的两个主题,共同组成一个主题组,可以保证写kafka的可用性超过99.99%。在实际的数据分发任务中需要集中处理多个数据分发子任务,子任务之间的依赖性可能会影响服务整体的稳定性。通常,机房的网络连通性受到多种因素的影响,例如机房内网络设备故障、运营商网络设备故障等。因此,单机房部署服务在机房故障时容易受到严重影响,而跨机房的网络交互又导致数据传输容易受到网络环境的影响。为了保证服务的可用性,多机房之间服务的切换能力是非常重要的。综上,本公开采用异地部署的消息队列双集群来实现容灾,保证数据流的可用性。
84.具体的,图2c是本公开实施例提供的一种统一数据分发任务的组织简图。如图2c所示,在kafka topic组中存在一个主kafka topic和一个备kafka topic。多个kafka topic组可以作为数据源中的数据,分发至kafka、doris或者elasticsearch(es)等。当doris或者es发生异常时,数据分发任务会因为通路阻塞而停止消费上游的消息队列主题,这样故障期间的数据会暂存在消息队列中,待故障恢复后重新开始消费数据,可以实现doris或者es的容灾。
85.相应的,在本公开实施例的一个可选实施方式中,数据分发的实现方法,还包括:在根据当前配置的主备切换策略确定满足主备切换条件时,对所述异地设置的kafka集群
进行主备切换操作。
86.其中,主备切换条件可以是根据当前异地容灾的两个消息队列集群的数据分发情况,确定其中一个消息队列集群出现故障。主备切换策略可以是自动策略、概率策略、选主策略或者可干预策略。通过主备切换策略进行异地设置的kafka集群的主备切换操作,可以实现容灾,提高数据分发的可靠性,保证数据流的高可用性。
87.具体的,自动策略可以是根据获取的数据分发反馈信息,计算数据分发的成功数、失败数、以及成功率,可以根据对应的阈值确定是否进行主备切换操作。例如,当成功率低于对应的成功率阈值时,可以对异地设置的kafka集群进行主备切换操作。
88.概率策略可以是根据一定的概率选择某一kafka集群进行数据分发,数据分发任务能够正常执行,保证数据按照既定的规律分布至不同的集群即可。当选择的kafka集群存在异常时,可以将其拉黑,停用一段时间后,再重新尝试使用。
89.选主策略可以是优先选择主(master)角色的kafka集群进行数据分发,保证数据可以优先发送至指定的集群。当选择的master角色的kafka集群存在异常时,可以将其拉黑,停用一段时间后,再重新尝试使用。
90.可干预策略可以是定期获取切换配置信息,按照获取的切换配置信息更新主备kafka集群。当上述的主备切换策略不满足需求时,可以根据用户的自定义设置,进行主备切换操作。
91.本公开实施例的技术方案,通过获取所述目标数据分发任务的任务配置信息;根据所述任务配置信息,调用预先构建的至少一个抽象函数进行配置,得到目标数据分发任务;在检测到所述目标数据抽取子任务配置的所述目标数据源未被消费者容器中的任一消费者订阅时,通过所述消费者容器创建目标消费者;触发所述目标消费者订阅所述目标数据源;所述目标数据源中抽取目标数据至消息总线;从所述消息总线中深拷贝目标数据,并按照所述目标数据转换子任务配置的数据转换参数对所述目标数据进行格式转换;将格式转换结果加载至所述目标数据存储子任务配置的数据存储中,解决了数据分发效率低的问题,通过任务配置信息以及抽象函数得到目标数据分发任务,提供了数据分发的可定制能力,减少了系统运维的压力;通过消费者订阅数据源并将其数据抽取至消息总线实现了数据的复用,降低了数据源的压力,提高了数据分发的效率以及可靠性;通过深拷贝目标数据,并且在数据分发失败时进行重发,可以提高数据分发的可靠性;通过配置化的目标数据分发任务即配置抽取、转换以及存储,可以实现不同数据源与数据存储之间的互通,使数据分发具有通用性,节省开发及运维成本;通过异地设置的kafka topic组可以实现容灾;通过主备切换策略可以提高数据分发的高可用性;通过配置字段进行数据过滤,可以提高数据的可定制能力,降低下游系统数据预处理的压力。
92.图3是根据本公开实施例的一种数据分发的实现装置的结构示意图。如图3所示,该数据分发的实现装置300,包括:目标数据分发任务获取模块310,目标数据抽取模块320,目标数据格式转换模块330,和目标数据加载模块340。其中:
93.目标数据分发任务获取模块310,用于获取目标数据分发任务;其中,所述目标数据分发任务包括:目标数据抽取子任务、目标数据转换子任务和目标数据存储子任务;
94.目标数据抽取模块320,用于在所述目标数据抽取子任务配置的目标数据源未被任一数据分发任务订阅时,订阅所述目标数据源,并从所述目标数据源中抽取目标数据至
消息总线;
95.目标数据格式转换模块330,用于从所述消息总线中深拷贝目标数据,并按照所述目标数据转换子任务配置的数据转换参数对所述目标数据进行格式转换;
96.目标数据加载模块340,用于将格式转换结果加载至所述目标数据存储子任务配置的数据存储中。
97.可选的,所述目标数据分发任务获取模块,包括:
98.任务配置信息获取单元,用于获取所述目标数据分发任务的任务配置信息;其中,所述任务配置信息包括:数据源配置信息、数据转换参数配置信息、以及数据存储配置信息;
99.目标数据分发任务获取单元,用于根据所述任务配置信息,调用预先构建的至少一个抽象函数进行配置,得到目标数据分发任务。
100.可选的,所述目标数据分发任务获取单元,包括:
101.抽取函数生成子单元,用于根据所述数据源配置信息,调用抽取抽象函数进行配置,生成抽取函数;
102.转换函数生成子单元,用于根据所述数据转换参数配置信息,调用数据转换抽象函数进行配置,生成转换函数;
103.加载函数生成子单元,用于根据所述数据存储配置信息,调用加载抽象函数,生成加载函数;
104.目标数据分发任务获取子单元,用于将所述抽取函数、所述转换函数、以及所述加载函数进行组装,得到目标数据分发任务。
105.可选的,所述目标数据抽取模块,包括:
106.目标消费者创建单元,用于在检测到所述目标数据抽取子任务配置的所述目标数据源未被消费者容器中的任一消费者订阅时,通过所述消费者容器创建目标消费者;
107.目标数据源订阅触发单元,用于触发所述目标消费者订阅所述目标数据源。
108.可选的,该装置,还包括:
109.重发数据生成模块,用于在将格式转换结果加载至所述目标数据存储子任务配置的数据存储中之后,当检测到与所述目标数据对应的格式转换结果加载至匹配的数据存储操作失败时,将所述目标数据存储在失败队列中,生成重发数据;
110.数据重发模块,用于响应于数据重发请求,在所述失败队列中获取所述重发数据,进行数据重发。
111.可选的,该装置,还包括:
112.原始数据获取模块,用于在获取目标数据分发任务之前,获取多个数据类型的原始数据;
113.数据源生成模块,用于将所述原始数据以主题的方式存储在kafka topic组中,作为数据源;
114.其中,所述kafka topic组通过异地设置的kafka集群创建得到。
115.可选的,该装置,还包括:
116.主备切换模块,用于在根据当前配置的主备切换策略确定满足主备切换条件时,对所述异地设置的kafka集群进行主备切换操作。
117.可选的,该装置,还包括:
118.配置字段获取模块,用于在将格式转换结果加载至所述目标数据存储子任务配置的数据存储中之前,获取与所述目标数据分发任务匹配的配置字段;
119.数据过滤模块,用于按照所述配置字段,对所述格式转换结果进行数据过滤。
120.上述数据分发的实现装置可执行本公开任意实施例所提供的数据分发的实现方法,具备执行方法相应的功能模块和有益效果。
121.根据本公开的实施例,本公开还提供了一种电子设备、一种可读存储介质和一种计算机程序产品。
122.图4示出了可以用来实施本公开的实施例的示例电子设备400的示意性框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本公开的实现。
123.如图4所示,设备400包括计算单元401,其可以根据存储在只读存储器(rom)402中的计算机程序或者从存储单元408加载到随机访问存储器(ram)403中的计算机程序,来执行各种适当的动作和处理。在ram 403中,还可存储设备400操作所需的各种程序和数据。计算单元401、rom 402以及ram 403通过总线404彼此相连。输入/输出(i/o)接口405也连接至总线404。
124.设备400中的多个部件连接至i/o接口405,包括:输入单元406,例如键盘、鼠标等;输出单元407,例如各种类型的显示器、扬声器等;存储单元408,例如磁盘、光盘等;以及通信单元409,例如网卡、调制解调器、无线通信收发机等。通信单元409允许设备400通过诸如因特网的计算机网络和/或各种电信网络与其他设备交换信息/数据。
125.计算单元401可以是各种具有处理和计算能力的通用和/或专用处理组件。计算单元401的一些示例包括但不限于中央处理单元(cpu)、图形处理单元(gpu)、各种专用的人工智能(ai)计算芯片、各种运行机器学习模型算法的计算单元、数字信号处理器(dsp)、以及任何适当的处理器、控制器、微控制器等。计算单元401执行上文所描述的各个方法和处理,例如数据分发的实现方法。例如,在一些实施例中,数据分发的实现方法可被实现为计算机软件程序,其被有形地包含于机器可读介质,例如存储单元408。在一些实施例中,计算机程序的部分或者全部可以经由rom 402和/或通信单元409而被载入和/或安装到设备400上。当计算机程序加载到ram 403并由计算单元401执行时,可以执行上文描述的数据分发的实现方法的一个或多个步骤。备选地,在其他实施例中,计算单元401可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行数据分发的实现方法。
126.本文中以上描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、场可编程门阵列(fpga)、专用集成电路(asic)、专用标准产品(assp)、芯片上系统的系统(soc)、负载可编程逻辑设备(cpld)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出
装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。
127.用于实施本公开的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。
128.在本公开的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom或快闪存储器)、光纤、便捷式紧凑盘只读存储器(cd-rom)、光学储存设备、磁储存设备、或上述内容的任何合适组合。
129.为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,crt(阴极射线管)或者lcd(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。
130.可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(lan)、广域网(wan)、区块链网络和互联网。
131.计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,又称为云计算服务器或云主机,是云计算服务体系中的一项主机产品,以解决了传统物理主机与vps服务中,存在的管理难度大,业务扩展性弱的缺陷。服务器也可以为分布式系统的服务器,或者是结合了区块链的服务器。
132.人工智能是研究使计算机来模拟人的某些思维过程和智能行为(如学习、推理、思考、规划等)的学科,既有硬件层面的技术也有软件层面的技术。人工智能硬件技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理等技术;人工智能软件技术主要包括计算机视觉技术、语音识别技术、自然语言处理技术及机器学习/深度学习技术、大数据处理技术、知识图谱技术等几大方向。
133.云计算(cloud computing),指的是通过网络接入弹性可扩展的共享物理或虚拟资源池,资源可以包括服务器、操作系统、网络、软件、应用和存储设备等,并可以按需、自服务的方式对资源进行部署和管理的技术体系。通过云计算技术,可以为人工智能、区块链等技术应用、模型训练提供高效强大的数据处理能力。
134.应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本公开公开的技术方案所期望的结果,本文在此不进行限制。
135.上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1