一种工控OT网络多目标渗透测试方法及系统与流程
一种工控ot网络多目标渗透测试方法及系统
技术领域
1.本发明涉及大数据处理领域,尤其是涉及一种工控ot网络多目标渗透测试方法及系统。
背景技术:
2.工控ot(operation technology)网络用于管理工业基础设施,连接控制设备与被控制设备,如工业控制系统(ics)和数据采集与监视控制系统(scada)等。传统的工业控制系统是独立的与互联网隔离的系统,近年来,随着工业控制系统的联网,工业控制系统封闭性和专有性被打破,众多攻击案例表明网络攻击穿越了it网络向ot网络渗透。
3.渗透测试是一种典型分析技术,从攻击者的视角评估系统安全性,可以用于辅助漏洞修复、安全加固等,当前对网络的自动渗透测试通常输出一条最优攻击路径,用于辅助安全防护者优先修补最优路径上的漏洞,渗透测试需要大量的专业知识,传统的渗透测试需要由专家执行,渗透测试由于人力成本高昂,只能采取定期对系统进行测试评估,难以通过频繁测试实现对系统状态的掌握,当前业界投入大量资源研发自动渗透测试工具,用于辅助进行渗透测试,减少专家的工作量。
4.其中,基于强化学习进行自动渗透测试的方法由于具有在和环境交互过程中总结经验的特点,很适合渗透测试场景,得到了广泛使用。目前大部分采取it网络渗透测试,部分应用采用强化学习和真实环境进行交互,但其训练过程中往往需要大量的尝试攻击模块,训练过程并没有比遍历式的执行效率高,一些现有技术使了mulval工具获得攻击图,然后在攻击图上提取部分节点作为马尔可夫模型,进行强化学习训练,该方法结合了攻击图推理引擎的优点,具有训练简单的特点,在获得的模型上训练避免了直接和环境交互产生大量无意义攻击流量,然而该类方法仅仅应用于简单的单目标场景,针对当前工控网络使用大量缺少认证和加密机制的工业控制协议,如modbus、opcda等,在获取工业网络访问权限后可以对工业控制设备直接发送控制指令造成破坏,将穿越it网络连接ot网络的目标定义为获取可以访问工控网络的主机的权限。这代表着在一次渗透测试中存在多个可能的最终目标,评估每一步攻击的优劣需要考虑多个目标的影响。
5.因此,现有方法定义了过多的与目标无关的正奖励,导致其最优路径中目标性不强,倾向于沿路径收集多个正奖励,广泛的攻击网络中的漏洞,这类方法最终输出一条最优攻击路径而不是攻击策略,缺乏对攻击过程中干扰的考虑,辅助专家进行渗透测试时,要求专家严格按照系统找到的最优路径执行,不能够适应专家基于个人经验和偏好做出的调整。
技术实现要素:
6.本技术的目的在于提供一种工控ot网络多目标渗透测试方法及系统,旨在解决传统的渗透测试方法存在的测试目标单一和测试方法繁琐的技术问题。
7.本技术实施例的第一方面提供了一种工控ot网络多目标渗透测试方法,其包括:
8.收集被测网络信息,生成攻击图;
9.从所述攻击图中抽象出马尔可夫模型并赋予状态转换奖励;
10.采用强化学习算法与所述马尔可夫模型进行交互,获得最优攻击策略;
11.调用渗透测试工具,对所述最优攻击策略进行验证。
12.优选的,收集被测网络信息,具体通过以下方式实现:
13.对被测网络系统进行信息扫描;
14.工控网络渗透测试目标的设置;
15.收集并建立漏洞数据集进行数据存储。
16.优选的,生成攻击图,具体通过以下方式实现:
17.根据网络上各主机之间的连通性关系和漏洞前后条件关系推导出各个漏洞之间的关系,形成攻击图,利用收集到的主机配置信息,通过mulval工具获得攻击图。
18.优选的,从所述攻击图中抽象出马尔可夫模型并赋予状态转换奖励,具体通过以下方式实现:
19.将攻击图上的所有节点作为马尔可夫过程的状态,攻击图上的节点拥有不同的奖励,代表马尔可夫过程中,进入该状态会获得的奖励。
20.优选的,采用强化学习算法与所述马尔可夫模型进行交互,具体通过以下方式实现:
21.每一幕开始,选定任意初始状态s,由预测值网络计算出该s下所有动作对应的q值,选择最大的q值对应的动作a,施加到环境mdp模型中,在这里具体过程是查询马尔可夫模型图,如果状态之间有有向边连接,则成功返回下一状态s’,其编号与a相同,查询奖励矩阵获得奖励r;如果没有有向边相连,则返回下一状态s’,其编号与s相同,查询奖励矩阵获得奖励r,并将该经验(s,a,r,s’)放入回放换缓冲区中;
22.每一次和环境进行交互将经验放入回放缓冲区后,神经网络都会进行多次训练,回放缓冲区是一个固定大小的存放经验的存储区,在训练神经网络时,随机的从回放缓冲区中获取经验,将其中(s,a)传递给预测值网络,预测值网络由其当前的网络参数w,输出q(s,a,w),回放缓冲区将s’传递给目标值网络,目标值网络输入最大的q值maxq(s’,a’,w’),回放缓冲区再将r直接传递给损失值函数,maxq(s’,a’,w’)+r-q(s,a,w)是预测值网络训练需要的误差函数,其梯度可以指导预测值网络修改参数,多次交互后,复制预测值网络的参数到目标值网络,每一幕的交互直到进入马尔可夫模型目标节点或者超过最大步数终止,训练结束时得到神经网络参数。
23.优选的,获得最优攻击策略,具体通过以下方式实现:
24.向强化学习训练后获得的神经网络输入状态,输出的是这个状态下各个动作的价值,即q值,智能体查找最大的q值对应的动作,可以获得当前状态下最优的下一步动作;从起始状态出发,若一直按照最优策略进行,即可得到最优路径;若偏离了最优路径,攻击策略提供下一步攻击的指导。
25.优选的,调用渗透测试工具,对所述最优攻击策略进行验证,具体通过以下方式实现:
26.根据智能体获得的最佳路径,借由攻击图提供的信息,指导调用渗透测试工具进行实际渗透测试。
27.优选的,渗透测试工具采用metasploit、burpsuit或w3af。
28.本技术的第二方面提供了一种工控ot网络多目标渗透测试系统,包括:
29.攻击图生成模块:用于收集被测网络信息,生成攻击图;
30.攻击图转换模块:用于从所述攻击图中抽象出马尔可夫模型并赋予状态转换奖励;
31.交互模块:用于采用强化学习算法与所述马尔可夫模型进行交互,获得最优攻击策略;
32.验证模块:用于调用渗透测试工具,对所述最优攻击策略进行验证。
33.本发明通过收集信息,获取攻击图,从攻击图抽象出马尔可夫模型,然后使用强化学习方法获得马尔可夫模型的最优策略,最终指导调用攻击工具进行攻击验证,与现有适用于单目标渗透测试的方法相比,本发明的建模贴近工控ot网络中多目标的场景;且提出了攻击策略的应用方式,采用代价的设置方式,确保了最优路径的目标导向。本技术适用于工控网络多目标渗透测试,辅助渗透测试工程师穿越it网络到达ot网络,以目标为导向,寻找使得攻击代价最小的最优攻击策略,可以给出较为容易到达目标的路径;同时,本方法可以满足渗透测试工程师基于自身经验改动部分攻击步骤后重新给出指导,具有较大的灵活性。
附图说明
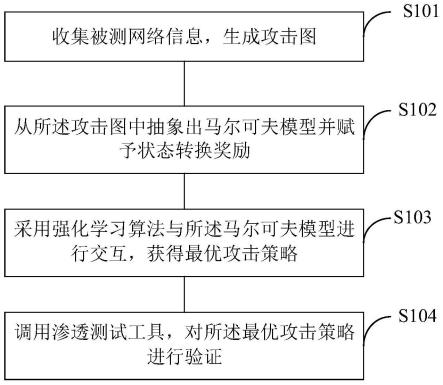
34.图1为本技术一实施例提供的一种工控ot网络多目标渗透测试方法的流程示意图;
35.图2为本技术一实施例提供的一种工控ot网络多目标渗透测试方法的拓扑图;
36.图3为本技术一实施例提供的被测网络系统示例图;
37.图4为本技术一实施例提供的攻击示例图;
38.图5为本技术一实施例提供的强化学习算法的流程框图;
39.图6为本技术一实施例提供的最优策略的状态转移图。
具体实施方式
40.为了使本技术所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
41.需要说明的是,术语“上”、“下”、“内”、“外”、“顶”、“底”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不能理解为指示或暗示所指的装置或元件必须具备特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
42.请参阅图1,为本技术一实施例提供的一种工控ot网络多目标渗透测试方法的流程示意图,为了便于说明,仅示出了与本实施例相关的部分,详述如下:
43.在其中一实施例中,一种工控ot网络多目标渗透测试方法,如图2所示为本实施例测试方法的拓扑图,针对被测网络收集信息,通过mulval生成攻击图,然后将攻击图转换为马尔可夫过程(mdp)并赋予状态转换奖励,智能体采用强化学习算法与mdp进行交互,训练
获得最优攻击策略,最后智能体调用攻击工具进行渗透测试,验证最优攻击策略。其具体步骤包括:
44.s101、收集被测网络信息,生成攻击图。
45.具体地,对被测网络系统进行信息扫描;被测网络系统为图3所示的it+ot网络,其中it网络包括企业服务器和办公电脑,工程师站等,其外联以太网,内联ot网络;ot网络连接控制器,监视器和被控设置,传感器等,渗透测试方法用于穿越it网络连接ot网络。
46.本技术实施例适用于安全专家在对系统有权限进行充分的信息收集时使用,通过在各个子网内进行扫描,以及查看各主机、防火墙的配置信息获取到各个主机的连通性信息,并匹配为mulval所需的hacl语法,如hacl(1,2,tcp,80)代表主机1可以通过tcp访问主机2的80端口。
47.使用nmap、nessus等开源工具进行主机系统信息、服务信息和漏洞信息收集,使用主机上漏洞查找工具进行漏洞信息验证,如windows exploit suggester,linux exploit suggester等工具,本实施例中图3所示系统的服务器1的网络信息如表1所示。
48.表1主机信息收集示例
[0049][0050][0051]
工控网络渗透测试目标的设置:工控ot网络下大量使用缺乏认证和加密机制的工控协议,当工控设备可以被访问到时,即可伪造工控协议对工控设备进行操控,当前大量的工控网络采用基于边界的防护,其在边界连接it网络的地方设置有防火墙用于限制访问,任何可以直接访问工控设备的主机都可以作为工控网络渗透测试的目标,在通过在主机上运行扫描软件、查看网络配置信息等基础上,可以确定这类目标主机。
[0052]
收集并建立漏洞数据集进行数据存储:为了后续生成攻击图以及给攻击步骤确定代价,需要收集并建立漏洞数据集,目前有多个公开的漏洞数据库,如nvd漏洞库,获取漏洞的cve编号和cvss3评分数据,包括基础分数base score和可利用性评分exploitability,本实施例中收集的漏洞信息如表2所示。
[0053]
表2漏洞信息示例
[0054]
cve编号base scoreexploitability利用方式效果cve-2020-148829.8lowremotepriescalation
[0055]
本实施例采用mulval工具生成攻击图,mulval是一款开源的基于xsb逻辑引擎的攻击图生成工具,可以根据网络上各主机之间的连通性关系和漏洞前后条件关系推导出各个漏洞之间的关系,形成攻击图,利用收集到的主机配置信息,包括主机的服务、连通性和漏洞信息,输入到mulval获得攻击图,输出的攻击图为图4所示的有向图形式。
[0056]
如图4所示,攻击图中的方框是叶子节点,代表初始条件,椭圆形是推理规则,棱形是推理结果,输入信息会先转化为叶子节点,然后通过推理规则生成推理结果,再经过多次推理将多个节点连接起来,推导出最终结果,攻击图从逻辑上展示了多步攻击的可能性,其中推理规则由一系列rule组成,rule1为本地漏洞利用规则,rule2为远程漏洞利用规则,rule5为多跳网络访问规则,本实施例中攻击图节点说明如表3所示。
[0057]
表3攻击图示例节点说明
[0058][0059][0060]
s102、从攻击图中抽象出马尔可夫模型并赋予状态转换奖励。
[0061]
具体地,将攻击图上的所有节点作为马尔可夫过程的状态,当攻击图节点1有一条有向边指向节点2时,马尔可夫过程也有状态1指向状态2的状态转移,试图往某个状态迁移的动作为动作集合,并以目标状态编号为动作命名,如在状态1采用动作2试图向状态2转移,由于攻击图上1到2为有向边,当采取动作2时,可以成功转移到状态2,在状态1采用动作3试图向状态3转移,由于攻击图上1到3没有边,无法转移到状态3,则仍然回到状态1。
[0062]
攻击图上的节点拥有不同的奖励,代表马尔可夫过程中,进入该状态会获得的奖励,最终目标节点为目标主机的任意代码执行,能直接访问工业控制网络的主机都被设置为目标主机,目标节点是在攻击图上所有含有“execcode”和目标主机名的节点,成功进入这些节点获得奖励100。
[0063]
对于rule1(local exploit)和rule2(remote exploit)节点,与“vulexist”直接相连,代表漏洞利用,根据“vulexist”节点提供的漏洞信息,查询cvss和metasploit中漏洞利用模块评级,计算奖励值,其值为负数,代表到该节点需要付出的代价。其公式为:r=-cost_complexity*cost_exploit,其中cost_complexity来自cvss评分中的attack complexity分级,当分级为low时,cost_complexity为1,当分级为high时,cost_complexity为2,cost_exploit代表漏洞利用脚本的质量,根据metasploit搜索相应漏洞获得的exploits模块中最高等级来计算,根据表4给出计算因子。
[0064]
表4 cost_exploit计算表
[0065][0066]
rule5(multi-hop access)节点设置奖励值为-0.5,代表建立代理访问需要的代价,其他节点奖励设置为0,代表没有代价,对于状态跳转失败回到原状态的情况,则给与奖励值-0.1,代表无效动作的代价。
[0067]
需要说明的是,上述奖励代价的具体设置为一个实施例,可以有更多的奖励设置方式,对值进行微调应视为本发明的保护范围。
[0068]
s103、采用强化学习算法与马尔可夫模型进行交互,获得最优攻击策略。
[0069]
具体地,智能体采用强化学习算法进行训练,获得状态到状态动作值(q值)的映射神经网络,使用该神经网络进行决策。
[0070]
强化学习是与环境进行交互,将环境状态映射到动作选择的一种学习方法,强化
学习可以尝试确定给定环境状态下动作的策略,使得最终累计的奖励值最大,dqn算法是基于状态动作值的强化学习算法,使用了神经网络对状态动作值进行拟合和存储。
[0071]
算法分多幕进行训练,幕是从初始状态到结束状态的一次训练。如图5所示,每一幕开始,选定任意初始状态s,由预测值网络计算出该s下所有动作对应的q值,选择最大的q值对应的动作a,施加到环境mdp模型中,在这里具体过程是查询马尔可夫模型图,如果状态之间有有向边连接,则成功返回下一状态s’,其编号与a相同,查询奖励矩阵获得奖励r;如果没有有向边相连,则返回下一状态s’,其编号与s相同,查询奖励矩阵获得奖励r,并将该经验(s,a,r,s’)放入回放换缓冲区中;
[0072]
每一次和环境进行交互将经验放入回放缓冲区后,神经网络都会进行多次训练,回放缓冲区是一个固定大小的存放经验的存储区,在训练神经网络时,随机的从回放缓冲区中获取经验,将其中(s,a)传递给预测值网络,预测值网络由其当前的网络参数w,输出q(s,a,w),回放缓冲区将s’传递给目标值网络,目标值网络输入最大的q值maxq(s’,a’,w’),回放缓冲区再将r直接传递给损失值函数,maxq(s’,a’,w’)+r-q(s,a,w)是预测值网络训练需要的误差函数,其梯度可以指导预测值网络修改参数,多次交互后,复制预测值网络的参数到目标值网络,每一幕的交互直到进入马尔可夫模型目标节点或者超过最大步数终止,训练结束时得到神经网络参数。
[0073]
最优策略是根据输入的当前状态输出下一步最优动作,最优路径是指从初始状态出发到目标节点的动作序列,相比其他方法获取最优路径,获取最优策略是基于状态-动作值的强化学习方法的优势。
[0074]
向强化学习训练后获得的神经网络输入状态,输出的是这个状态下各个动作的价值,即q值,智能体查找最大的q值对应的动作,可以获得当前状态下最优的下一步动作,从起始状态出发,若一直按照最优策略进行,可以得到最优路径,如果偏离了最优路径,攻击策略依然可以提供下一步攻击的指导。
[0075]
在实际渗透测试中,测试员根据自己的经验偏好,并不会完全按照系统给出的最优路径进行渗透测试,可能会做出调整,从而出现偏离最优路径的行为,基于最优策略的分析方法可以在观察到实际状态下,按照最优策略推荐下一步位置,以便继续帮助渗透测试员进行下一步测试。
[0076]
如图6所示的状态转移图中,双圆圈代表目标节点,假设s1-》s2-》s3-》s4为系统给出的最优路径,但在s1状态下,测试员基于自己较为熟悉s5步的攻击放弃s2而选择了s5,其选择离开了最优路径,但系统仍然可以提供辅助,按照s5状态输出最优下一步s7。
[0077]
s104、调用渗透测试工具,对最优攻击策略进行验证。
[0078]
为了验证攻击策略以及进行渗透测试自动化,本实施例利用多款渗透测试工具进行自动渗透测试攻击,渗透测试工具采用metasploit、burpsuit或w3af等,本实施例以metasploit为例说明本技术如何将规划的状态动作匹配到攻击工具的调用。
[0079]
metasploit(msf)是一款免费可下载的专业级渗透测试框架,附带数千个已知软件漏洞的利用脚本,攻击图的rule节点代表了攻击图的推理规则,也可以用于调用渗透测试工具时动作的指导。根据智能体获得的最佳路径,借由攻击图提供的信息,可以指导调用msf进行实际渗透测试,本实施例中rule节点与动作的映射关系如表5所示。
[0080]
表5节点与动作的映射关系
[0081][0082][0083]
本技术的第二方面提供了一种工控ot网络多目标渗透测试系统,包括攻击图生成模块、攻击图转换模块、交互模块及验证模块。
[0084]
攻击图生成模块:用于收集被测网络信息,生成攻击图;
[0085]
攻击图转换模块:用于从攻击图中抽象出马尔可夫模型并赋予状态转换奖励;
[0086]
交互模块:用于采用强化学习算法与马尔可夫模型进行交互,获得最优攻击策略;
[0087]
验证模块:用于调用渗透测试工具,对最优攻击策略进行验证。
[0088]
需要说明的是,本实施例中的一种工控ot网络多目标渗透测试系统,是上述一种工控ot网络多目标渗透测试方法对应的系统的实施例,因此关于流量异常检测系统的各模块中软件方法的具体实现,可参照图1-图6的实施例,此处不再详细赘述。
[0089]
本发明实施例中上述的一种工控ot网络多目标渗透测试方法及系统,通过收集信息,获取攻击图,从攻击图抽象出马尔可夫模型,然后使用强化学习方法获得马尔可夫模型的最优策略,最终指导调用攻击工具进行攻击验证,与现有适用于单目标渗透测试的方法相比,本发明的建模贴近工控ot网络中多目标的场景;且提出了攻击策略的应用方式,采用代价的设置方式,确保了最优路径的目标导向。本技术适用于工控网络多目标渗透测试,辅助渗透测试工程师穿越it网络到达ot网络,以目标为导向,寻找使得攻击代价最小的最优攻击策略,可以给出较为容易到达目标的路径;同时,本方法可以满足渗透测试工程师基于自身经验改动部分攻击步骤后重新给出指导,具有较大的灵活性。
[0090]
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0091]
以上所述实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改
或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1