一种基于互信息与灰狼提升算法的网络入侵检测方法与流程
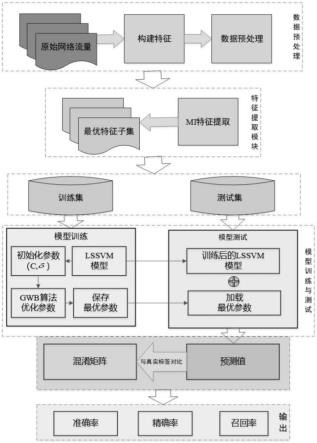
1.本发明涉及一种基于互信息与灰狼提升算法的网络入侵检测方法,属于网络安全领域。
背景技术:
2.目前人、物间相互连接示范出的便利性促生了不断膨化的互联网、物联网连接需求,这导致网络设施中尚未完备或难以根治的系统漏洞等面临严重的网络入侵和攻击风险。传统的根据攻击构建的入侵检测规则越来越难以应对日益复杂和不断变种的网络攻击,尤其是难以防范和检测未知攻击。近年来随着机器学习等技术的发展,基于异常检测的网络攻击检测虽然取得一定程度的进展,但仍然面临攻击特征提取人工依赖性强,未知攻击检测困难、检测模型复杂度高和网络攻击检测精度低等困难,这严重制约了网络入侵检测系统的发展和应用。
技术实现要素:
3.本发明为解决上述现有技术中存在的问题,提供了一种基于互信息与灰狼提升算法的网络入侵检测方法,本方法能够在模型训练阶段大大缩短模型训练的时间,降低模型训练消耗和时间成本,而且本方法能够更好的实现网络流量前相关特征的选择,提升网络入侵行为检测的精度和模型收敛的速度。
4.为实现上述目的,本发明提供的技术方案为:一种基于互信息与灰狼提升算法的网络入侵检测方法,按以下步骤进行处理:
5.1)构建原始流量数据集d
ys
:通过数据采集器采集目标网络的流量数据,并根据流量数据构建网络原始流量数据集d
ys
;
6.2)构建可分析数据集d
parse
:根据tcp/ip协议簇的标准对原始流量数据集d
ys
进行解码,从原始流量数据集d
ys
中提取并构成可分析数据集d
parse
;
7.3)构建网络流量特征数据集df:通过流量统计计算获取可分析数据集d
parse
中的特征集,构建用于网络入侵检测模型使用的网络流量特征数据集df;
8.4)构建标注数据集d
fl
:参照现有的黑名单和白名单特征库对df中的正常流量和攻击流量进行类别标注,构成可供网络入侵检测模型训练使用的标注数据集d
fl
;
9.5)对标注数据集d
fl
中数据进行预处理:首先对标注数据集d
fl
中的缺失值进行删除,对标注数据集d
fl
中的重复值进行剔除,以保证数据唯一性,保证模型识别准确性;通过使用二值转换完成字符型数据到数值型数据的转换,使用归一化进行数据处理,将标注数据集d
fl
进一步形成标准化数据集ds;
10.6)提取最优特征子集:计算标准化数据集ds中的每一列特征xi与标注标签集合y之间的互信息值,将得到的特征xi按照互信息值大小进行降序排序,剔除标准化数据集ds中互信息值《0.2的特征维,保留标准化数据集ds中互信息值≥0.2的特征维构建最优特征子集d
s’,然后从d
s’随机提取80%的样本作为用于训练入侵检测模型的训练集ds’-tr
,将剩余
20%的样本作为测试入侵检测模型的测试集ds’-ts
;
11.7)构建入侵检测模型:构造最小二乘支持向量机网络入侵检测模型,通过将训练集ds’-tr
输入至最小二乘支持向量机网络入侵检测模型中进行训练,并通过灰狼提升算法优化最小二乘支持向量机网络入侵检测模型的参数,提升模型检测率;
12.8)评估模型检测性能:将步骤7)中的模型训练得到的最优参数进行保存,训练完成后,设置最优参数,结合训练好的模型,将测试集ds’-ts
输入保存好的入侵检测模型框架,对模型检测性能进行评估验证;
13.9)检测结果可视化呈现:实时的网络流量采集、预处理和特征提取后,将提取的特征输入至训练好的入侵检测模型框架,输出结果作为对实时网络攻击检测识别与分类的结果,以文本和图形事件图库形式展示给用户,展示结果支持分类事件收藏和查询。
14.更进一步的,在步骤5)中数据预处理的步骤包括:二值转换,即利用字典的键值对实现字符型特征到数值型特征的转换;和归一化,即采用min-max方式实现归一化处理,保证所有数据范围为[0,1],并在规范化过程中进行空值与无穷大值的样本剔除处理,以达到解决数据样本的量纲不统一的问题,min-max归一化方法如公式(1)所示:
[0015][0016]
式中:xi为标准化数据集ds第i列特征归一化后的数值;xi为采集的标注数据集d
fl
第i列特征原始数值;x
i_max
为标注数据集d
fl
第i列特征所有样本中的最大值,x
i_min
为标注数据集d
fl
第i列特征所有样本中的最小值。
[0017]
更进一步的,在步骤6)中提取最优特征子集时,按照以下步骤计算每列特征与标志的互信息值:
[0018]
(1)利用式(2)、(3)分别计算特征xi、标注标签集合y的互信息熵;
[0019][0020]
式(2)中:xi为归一化后的第i列特征;x为第i列特征所有的样本构成的集合;p(xi)表示第i列特征xi的边缘分布;
[0021][0022]
式(3)中:y为所有标注标签值构成的集合;y表示标注标签;p(y)表示标注标签y的边缘分布;
[0023]
(2)利用式(4)计算各列特征xi与标注标签集合y之间的交叉熵;
[0024][0025]
式(4)中:p(xi,y)表示特征xi和标注标签y之间的联合分布;
[0026]
(3)在特征、标签的信息熵和各列特征与标签之间的交叉熵的基础上利用式(5)计算特征xi与标注标签集合y的互信息值;
[0027][0028]
式中:h(xi|y)表示特征xi与标注标签集合y之间的条件熵。
[0029]
更进一步的,在步骤7)中检测模型构建的步骤包括:构建学习模型,采用高斯径向基核函数替换原始最小二乘支持向量机中的核函数,高斯径向基核函数的计算如式(6)所示:
[0030][0031]
式中:δ为核宽度参数;x
l
为第l个样本,xi为当前样本输入点;即:高斯径向基核函数主要计算所有样本与每一个输入点的距离;
[0032]
最小二乘支持向量机模型为式(7):
[0033][0034]
式中:w为权重向量;b是偏移量;c为正则参数;ei表示输出的实际值和预测值之间的回归误差;yi表示实际标签值;
[0035]
利用拉格朗日乘子法将式(7)可以转换成无约束的拉格朗日目标函数l(w,b,e;a),表示为式(8);
[0036][0037]
式中:j(w,e)见式(7);n表示样本数量,即参与模型训练的样本数;ai表示拉格朗日乘数;
[0038]
令l(w,b,e;a)分别对w,b,ei,ai求导等于0,对(8)进行求解得到公式(9),k为核矩阵;
[0039][0040]
式中:e表示单位向量;k为原始核矩阵,本发明利用式(6)替换此处的k;c为正则参数;b是偏移量;a表示拉格朗日乘数;y表示实际标签值;
[0041]
采用高斯径向基核函数(6)替代(9)中的核函数k,对其求解之后可以得到最小二乘支持向量机分类表达式。
[0042]
更进一步的,在步骤7)中通过灰狼提升算法gwb对lssvm的参数进行优化,构建基
于灰狼提升算法优化的最小二乘支持向量机模型,即gwb-lssvm,模型,灰狼提升算法通过以下步骤进行设置:
[0043]
(1)设置各项初始参数,设置gwb-lssvm模型,即灰狼提升算法正则化参数c的范围和核函数参数δ的搜索范围为0.1-300,gwb算法的种群规模为12,最大迭代次数为100;种群可以表示成式(10):
[0044][0045]
式中:x
ij
表示第i个样本的第j个特征;
[0046]
(2)初始化种群,通过选取对网络流量检测的准确率为优化算法的自适应度,计算种群个体自适应度值,并按照大小确定值最高的三个个体为狼王a,左护法b和右护法c;初始化种群的公式见(11);
[0047]
x
i*
={x
ij*
}=x
ijl
+rand(0,1)
×
(x
iju-x
ijl
)
ꢀꢀ
(11)
[0048]
式中:x
iju
为第i个样本的第j个特征的上界;x
ijl
为第i个样本的第j个特征的下界;
[0049]
(3)利用式(12)确定种群前进的步长和方向,利用公式(13)和公式(14)更新父代种群位置;
[0050]
a=rand(-a,a)
ꢀꢀ
(12)
[0051][0052][0053]
式中:a为取值范围为-a到a的均匀随机数,a为常数,初始值为2,并随着迭代次数由2线性降至0;c为正则参数,一般用2r1进行计算,r1=rand(0,1);xa(t)、xa(t)、xa(t)分别表示第t次迭代后狼群中狼王、左右护法的位置,x
di
(t)表示第t次迭代后猎物的位置;
[0054]
(4)利用差分机制进行变异、交叉产生新子代个体,变异、交叉具体计算见式(15),(16),式(16)通过每个个体与其变异个体进行交叉操作,生成试验个体;
[0055]
vi(g)=xa(g)+f
×
(xb(g)-xc(g))
ꢀꢀ
(15)
[0056]
式中:xa(g)表示当前群体第a个个体;xb(g),表示当前群体第b个个体;xc(g)表示当前群体第c个个体;vi(g)为第i个个体对应的变异个体;f为缩放因子;
[0057][0058]
式中:cr表示交叉概率因子;x
t*
为初始种群,计算方式见式(11);vi(g)为第i个个体对应的变异个体,计算方式见式(15);u
t
(g)表示试验个体;
[0059]
(5)利用差分机制的选择步骤更新父代种群;选择步骤的计算方式见式(17);
[0060][0061]
式中:f(u
t
(g))表示试验个体的适应度值;f(x
t*
)表示初始个体的适应度值;
[0062]
(6)计算新种群所有个体的自适应度值,更新狼王和左右护法的位置;
[0063]
(7)判断迭代次数是否满足终止条件,满足输出最小二乘支持向量机网络入侵检测模型的最优参数核函数宽度δ和正则参数c。
[0064]
更进一步的,在步骤8)中对模型评估与优化包括以下步骤:
[0065]
(1)性能测试:设置最优参数核函数宽度δ和正则参数c,测试集ds’-ts
输入到lssvm模型中进行预测;
[0066]
(2)性能评估:统计预测结果和真实结果构成的混淆矩阵,利用式18、公式19和公式20计算准确率、精度和检测率等指标;
[0067][0068][0069][0070]
式中:acc为准确度,precision为精度,recall为检测率;tp表示真阳率,fn表示假阴率,fp表示假阳率,tn表示真阴率。
[0071]
根据上述技术方案可知,本方法提供的基于互信息与灰狼提升算法的网络入侵检测方法在训练阶段通过互信息理论选取训练集中关键特征,并通过互信息大小对选取的特征进行降序排序。然后将这些特征作为输入加载到gwb-lssvm模型中来训练,并采用gwb算法优化整个模型的权重参数。gwb-lssvm模型通过对关键特征的学习,获取最优的核函数宽度和正则化参数c。测试阶段提取测试数据的特征输入到训练好的gwb-lssvm分类模型中,根据模型输出的类别概率分布判断分类结果正确与否,进而进行模型评估。本方法相对于现有的技术方案具有以下优点:
[0072]
1)因为本发明采用基于互信息理论的特征提取模型,根据互信息值的大小对所采集的数据集进行提取,所以本方法相对于传统模型的特征降维方法大大缩短了模型训练的时间,降低了模型训练消耗和时间成本,同时针对网络流量强相关特征提取方面具有更好的优势,从模型训练阶段结果可以看出相同条件下该方法提取的特征集具有更好的分类精度。
[0073]
2)本发明利用差分算法对灰狼算法进行改进以获取更快的寻优速度,在此基础
上,以改进后的灰狼提升算法针对最小二乘支持向量机入侵检测模型的正则参数和核函数宽度进行优化,所以使得该入侵检测模型获得了更好的针对网络流量的分类精度和更快的收敛速度。
[0074]
3)本发明采用图形可视化的形式展示分类结果,可以更好地以时间序列的形式线性的展示网络流量随时间变化状况和定位网络入侵与攻击流量发现、检测、变化和处置的过程,能够帮助用户更好的理解和处置网络攻击,并为模型的迭代维护提供快速反馈。
附图说明
[0075]
图1本发明提供的检测识别模型结构示意图;
[0076]
图2灰狼提升算法(gwb)的流程图;
[0077]
图3特征集;
[0078]
图4各列特征与标签的互信息值。
[0079]
具体实施方法
[0080]
下面结合附图和具体实施例对本发明作详细具体的说明,但本发明的保护范围不限于下述的实施例。
[0081]
在本发明所提供的技术方案中的基于互信息与灰狼提升算法的网络入侵检测方法,如图1所示,按以下步骤进行处理:
[0082]
1)构建原始流量数据集d
ys
:通过数据采集器采集目标网络的流量数据,并根据流量数据构建网络原始流量数据集d
ys
;
[0083]
2)构建可分析数据集d
parse
:根据tcp/ip协议簇的标准对原始流量数据集d
ys
进行解码,从原始流量数据集d
ys
中提取并构成可分析数据集d
parse
;
[0084]
3)构建网络流量特征数据集df:通过流量统计计算获取可分析数据集d
parse
中的特征集,构建用于网络入侵检测模型使用的网络流量特征数据集df;
[0085]
4)构建标注数据集d
fl
:参照现有的黑名单和白名单特征库对df中的正常流量和攻击流量进行类别标注,如图3所示,构成可供网络入侵检测模型训练使用的标注数据集d
fl
;
[0086]
5)对标注数据集d
fl
中数据进行预处理:首先对标注数据集d
fl
中的缺失值进行删除,对标注数据集d
fl
中的重复值进行剔除,以保证数据唯一性,保证模型识别准确性;通过使用二值转换完成字符型数据到数值型数据的转换,使用归一化进行数据处理,将标注数据集d
fl
进一步形成标准化数据集ds;
[0087]
在步骤5)中数据预处理的步骤包括:二值转换,即利用字典的键值对实现字符型特征到数值型特征的转换;在本实施例中,将“protocol”的tcp、udp、icmp分别转换成0、1、2;将“service”的aol、auth、bgp、...、z39-50的70种类型转换成0、1、2、...、69;将label的normal类型转换成0,将数据集的其它类型转换成1,具体如表1所示。
[0088]
表1
[0089][0090]
由于数据样本的量纲不统一,采用归一化对数据样本量纲进行处理,即采用min-max方式实现归一化处理,保证所有数据范围为[0,1],并在规范化过程中进行空值与无穷大值的样本剔除处理,以达到解决数据样本的量纲不统一的问题,min-max归一化方法如公式(1)所示:
[0091][0092]
式中:xi为标准化数据集ds第i列特征归一化后的数值;xi为采集的标注数据集d
fl
第i列特征原始数值;x
i_max
为标注数据集d
fl
第i列特征所有样本中的最大值,x
i_min
为标注数据集d
fl
第i列特征所有样本中的最小值;
[0093]
6)提取最优特征子集:计算标准化数据集ds中的每一列特征xi与标注标签y之间的互信息值,如图4所示,将得到的特征xi按照互信息值大小降序排序,剔除标准化数据集ds中互信息值《0.2的特征维,保留标准化数据集ds中互信息值≥0.2的特征维构建最优特征子集d
s’,然后从d
s’随机提取80%的样本作为用于训练入侵检测模型的训练集ds’-tr
,将剩余20%的样本作为测试入侵检测模型的测试集ds’-ts
;
[0094]
在本实施例中,步骤6)中提取最优特征子集时,按照以下步骤计算每列特征与标志的互信息值:
[0095]
(1)利用式(2)、(3)分别计算特征xi、标注标签y的互信息熵;
[0096][0097]
式(2)中:xi为归一化后的第i列特征;x为第i列特征所有的样本构成的集合;p(xi)表示第i列特征xi的边缘分布。
[0098][0099]
式(3)中:y为所有标注标签值构成的集合;y表示标注标签;p(y)表示标注标签y的边缘分布。
[0100]
(2)利用式(4)计算各列特征xi与标注标签集合y之间的交叉熵;
[0101]
[0102]
式(4)中:p(xi,y)表示特征xi和标注标签y之间的联合分布。
[0103]
(3)在特征、标签的信息熵和各列特征与标签之间的交叉熵的基础上利用式(5)计算特征xi与标注标签集合y的互信息值;
[0104][0105]
式中:h(xi|y)表示特征xi与标签y之间的条件熵。
[0106]
(4)将步骤(3)中互信息值计算结果按照互信息值降序排列,剔除其中互信息值《0.2的特征维,保留互信息值≥0.2的特征维作为下一步网络入侵检测模型训练的输入数据集。
[0107]
7)构建入侵检测模型:如图2所示,构造最小二乘支持向量机网络入侵检测模型(简称lssvm),通过将训练集ds’-tr
输入至最小二乘支持向量机网络入侵检测模型中进行训练,并通过灰狼提升算法优化最小二乘支持向量机网络入侵检测模型的参数,提升模型检测率;
[0108]
在本实施例中,步骤7)中检测模型构建的步骤包括:构建学习模型,采用高斯径向基核函数替换原始最小二乘支持向量机中的核函数,高斯径向基核函数的计算如式(6)所示:构建最小二乘支持向量机模型的关键在于核宽度参数δ和正则参数c。
[0109][0110]
式中:δ为核宽度参数;x
l
为第l个样本,xi为当前样本输入点;即:高斯径向基核函数主要计算所有样本与每一个输入点的距离。
[0111]
最小二乘支持向量机模型为式(7):
[0112][0113]
式中:w为权重向量;b是偏移量;c为正则参数;ei表示输出的实际值和预测值之间的回归误差;yi表示实际标签值。
[0114]
利用拉格朗日乘子法将式(7)可以转换成无约束的拉格朗日目标函数l(w,b,e;a),表示为式(8)。
[0115][0116]
式中:j(w,e)见式(7);n表示样本数量,即参与模型训练的样本数;ai表示拉格朗日乘数。
[0117]
令l(w,b,e;a)分别对w,b,ei,ai求导等于0,对(8)进行求解得到公式(9),k为核矩
阵。
[0118][0119]
式中:e表示单位向量;k为原始核矩阵,本发明利用式(6)替换此处的k;c为正则参数;b是偏移量;a表示拉格朗日乘数;y表示实际标签值。
[0120]
采用高斯径向基核函数(6)替代(9)中的核函数k,对其求解之后可以得到最小二乘支持向量机分类表达式。显然k和c严重影响到最终的分类结果。
[0121]
同时在本实施例中,步骤7)中通过灰狼提升算法gwb对lssvm的参数进行优化,构建基于灰狼提升算法优化的最小二乘支持向量机模型,即简称为gwb-lssvm模型,灰狼提升算法通过以下步骤进行设置:
[0122]
设置各项初始参数,即设置gwb-lssvm模型正则化参数c的范围和核函数参数δ的搜索范围为0.1-300,gwb算法的种群规模为12,最大迭代次数为100;种群可以表示成式(10)。
[0123][0124]
式中:x
ij
表示第i个样本的第j个特征。
[0125]
初始化种群,通过选取对网络流量检测的准确率为优化算法的自适应度,计算种群个体自适应度值,并按照大小确定值最高的三个个体为狼王a,左护法b和右护法c;初始化种群的公式见(11);
[0126]
x
i*
={x
ij*
}=x
ijl
+rand(0,1)
×
(x
iju-x
ijl
)
ꢀꢀ
(11)
[0127]
式中:x
iju
为第i个样本的第j个特征的上界;x
ijl
为第i个样本的第j个特征的下界。
[0128]
利用式(12)确定种群前进的步长和方向,利用公式(13)和公式(14)更新父代种群位置;
[0129]
a=rand(-a,a)
ꢀꢀ
(12)
[0130]
[0131][0132]
式中:a为取值范围为-a到a的均匀随机数,a为常数,初始值为2,并随着迭代次数由2线性降至0;c为正则参数,一般用2r1进行计算,r1=rand(0,1);xa(t)、xa(t)、xa(t)分别表示第t次迭代后狼群中狼王、左右护法的位置,x
di
(t)表示第t次迭代后猎物的位置。
[0133]
利用差分机制进行变异、交叉产生新子代个体,变异、交叉具体计算见式(15),(16),式(16)通过每个个体与其变异个体进行交叉操作,生成试验个体;
[0134]
vi(g)=xa(g)+f
×
(xb(g)-xc(g))
ꢀꢀ
(15)
[0135]
式中:xa(g)表示当前群体第a个个体;xb(g),表示当前群体第b个个体;xc(g)表示当前群体第c个个体;vi(g)为第i个个体对应的变异个体;f为缩放因子;
[0136][0137]
式中:cr表示交叉概率因子;x
t*
为初始种群,计算方式见式(11);vi(g)为第i个个体对应的变异个体,计算方式见式(15);u
t
(g)表示试验个体。
[0138]
利用差分机制的选择步骤更新父代种群;选择步骤的计算方式见式(17)。
[0139][0140]
式中:f(u
t
(g))表示试验个体的适应度值;f(x
t*
)表示初始个体的适应度值。
[0141]
计算新种群所有个体的自适应度值,更新狼王和左右护法的位置。
[0142]
判断迭代次数是否满足终止条件,满足输出最小二乘支持向量机网络入侵检测模型的最优参数核函数宽度δ和正则参数c。
[0143]
8)评估模型检测性能:将步骤7)中的模型训练得到的最优参数进行保存,训练完成后,设置最优参数,结合训练好的模型,将测试集ds’-ts
输入保存好的入侵检测模型框架,对模型检测性能进行评估验证;
[0144]
在本实施例中的步骤8)中对模型评估与优化包括以下步骤:
[0145]
(1)性能测试:设置最优参数核函数宽度δ和正则参数c,测试集ds’-ts
输入到lssvm模型中进行预测。
[0146]
(2)性能评估:统计预测结果和真实结果构成的混淆矩阵,利用式18、公式19和公式20计算准确率、精度和检测率等指标;
[0147][0148][0149][0150]
式中:acc为准确度,precision为精度,recall为检测率;tp表示真阳率,fn表示假
阴率,fp表示假阳率,tn表示真阴率。
[0151]
9)检测结果可视化呈现:实时的网络流量采集、预处理和特征提取后,将提取的特征输入至训练好的入侵检测模型框架,输出结果作为对实时网络攻击检测识别与分类的结果,以文本和图形事件图库形式展示给用户,展示结果支持分类事件收藏和查询。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1