一种基于半监督聚类学习的暗网站点会话识别方法及系统与流程
1.本发明涉及计算机网络技术领域,具体是一种基于半监督聚类学习的暗网站点会话识别方法及系统。
背景技术:
2.obfs4网桥是tor浏览器常用网桥之一,它作为一个模仿ssl协议进行加密的匿名混淆协议,继承了obfsproxy系列的加密方式,通过对负载部分的高度加密以及强大随机性来避免流量识别,同时在握手阶段引入了相互认证的机制,并设置了双方收发数据包的时间戳,从而很大程度上抑制了中间人攻击。通过分析obfs4网桥的tor浏览器客户端的流量数据,可以推断与确认双方通讯关系或任意一方的身份信息。
3.针对在网络流量层对obfs4网桥下用户访问的暗网站点进行识别的问题,现有的方法大多利用机器学习或深度学习方法对obfs4网桥的流量进行识别,例如论文《基于滑动窗口的混淆tor流量识别》(xu w, zou f. obfuscated tor traffic identification based on sliding window[j]. security and communication networks, 2021, 2021.)、论文《obfs4匿名网络流量识别研究》(高睿. obfs4 匿名网络流量识别研究[d]. 北京交通大学, 2018.)等研究通过提取时序特征、数据包特征、连接特征等多维流量特征,并使用机器学习算法来识别obfs4流量,但这些研究未对流量进行进一步分析,没有对obfs4流量下的访问的暗网站点进行识别,无法实现对暗网网络的精准监管。论文《基于匿名流量分析的网站识别》(赵晓娟. 基于匿名流量分析的网站识别[d]. 北京交通大学, 2019)提出的obfs4的网站指纹识别算法,可以对网站进行识别,但其高度依赖数据采集的多样性与人工经验提取特征的全面性,当网页结构发生变化时,需要重新训练模型,导致泛化性与实用性不足。
技术实现要素:
[0004]
为克服现有技术的不足,本发明提供了一种基于半监督聚类学习的暗网站点会话识别方法及系统,解决现有技术存在的泛化性不足、识别准确度较低、实用性不足等问题。
[0005]
本发明解决上述问题所采用的技术方案是:一种基于半监督聚类学习的暗网站点会话识别方法,利用深度学习cnn算法自动提取obfs4网桥下暗网站点会话的特征,并利半监督聚类算法对暗网站点的onion地址进行识别。
[0006]
作为一种优选的技术方案,包括以下步骤:s1,obfs4流量采集与暗网站点标注:利用配置有obfs4插件的tor浏览器访问不同的暗网站点,在客户端采集obfs4流量的数据,并在pcap文件的文件名中标出访问的onion地址,得到带暗网站点标记的流量样本数据;s2,obfs4流量预处理:对pcap格式的流量数据进行预处理,得到带暗网站点标记的会话样本数据;
s3,暗网站点特征生成:基于步骤s2中的带暗网站点标记的会话样本数据,利用深度学习cnn算法提取基于obfs4流量下的暗网站点特征向量;s4,半监督聚类:基于步骤s2得到的带暗网站点标记的会话样本数据以及s3中提取的基于obfs4流量下的暗网站点特征向量,利用半监督聚类算法对未知会话样本实现暗网站点onion地址的识别;s5,聚类结果反馈:对obfs4流量的聚类结果进行可视化展示,筛选出异常类簇,并结合人工经验,标注出异常类簇对应的暗网站点onion地址,并将标注后的暗网站点onion地址添加至步骤s1中的带暗网站点标记的流量样本数据中。
[0007]
作为一种优选的技术方案,步骤s1包括以下步骤:s11,判断是否为测试阶段;若是,则获取网关镜像流量,生成pcap流量数据,然后进入步骤s2;若否,则进入步骤s12;s12,在tor浏览器使用obfs4网桥,并进行网络连接;s13,获取.onion服务的列表;s14,获取第一条onion地址;s15,运行wireshark,访问步骤s14中获取的onion地址,保存pcap文件,并用步骤s14中获取的onion地址作为标注;s16,获取下一条onion地址;s17,判断onion地址是否为空;若是,则进入步骤s2;若否,则返回步骤s15。
[0008]
作为一种优选的技术方案,步骤s2包括以下步骤:s21,解析流量数据,过滤广播流量、icmp协议、udp流量,并对会话进行重组,提取会话五元组信息;s23,判断经步骤s21过滤后的会话协议类型是否为未知协议;若是,则保留会话;否则,过滤该会话;s24,对保留的会话信息进行存储,并提取会话中前100个交互报文的前1024个字节,若不足1024字节,则利用0xff进行填充至1024字节,利用填充后的交互报文构成会话字节矩阵,并将会话字节矩阵转为灰度图像。
[0009]
作为一种优选的技术方案,步骤s3包括以下步骤:s31,构建并训练暗网站点特征生成模型;s32,将会话灰度数据输入至训练后的暗网站点特征生成模型,利用深度学习提取obfs4流量中的暗网站点特征,将提取的暗网站点特征输出。
[0010]
作为一种优选的技术方案,步骤s31包括以下步骤:s311,构建暗网站点特征生成模型:利用cnn网络提取obfs4流量下的暗网站点特征;s312,利用有暗网站点标注的obfs4流量训练暗网站点特征生成模型:将会话灰度图像依次通过3*3的卷积层、2*2池化层、3*3的卷积层、全连接层、输出层进行处理,得到暗网站点特征生成模型识别的结果及其置信度,识别结果包括暗网站点的onion地址、暗网站点的onion地址的置信度,其中,全连接层中使用sigmod函数;通过不断调整暗网站点特征生成模型参数,重复进行训练,直至置信度达到设定的阈值,输出暗网站点特征生成模型识别的结果及其置信度;
s313,删除已训练的暗网站点特征生成模型的全连接层、输出层以及置信度,并将其保存为训练后的暗网站点特征生成模型。
[0011]
作为一种优选的技术方案,步骤s4包括以下步骤:s41,输入未知会话的灰度数据;s42,利用暗网站点特征生成模型,提取未知会话的特征向量;s43,将已有暗网站点标签的流量会话数据作为种子集,采用最大期望算法将样本划分为k个簇,计算步骤s41输入的未知会话与每个类簇的距离;其中,k为已知暗网站点的onion地址数,初始化的集群中心是每个簇类的均值;s44,得到聚类结果:若该会话与距离最近的类中心距离小于设定阈值,则认为该会话为最近的暗网站点类簇的暗网站点,并对会话进行标注;否则,认为该会话为非已知的暗网站点会话。
[0012]
作为一种优选的技术方案,步骤s5包括以下步骤:s51,将聚类结果以图形化结果展示,形成散点类簇图;s52,通过界面查看是否存在异常类簇,确认异常类簇是否为新的暗网站点;其中,异常类簇指不含有暗网站点标注的类簇;s53,若确认异常类簇为新的暗网站点,则结合人工经验,标注出异常类簇对应的暗网站点onion地址,并将标注后的暗网站点onion地址添加至步骤s1中的带暗网站点标记的流量样本数据中。
[0013]
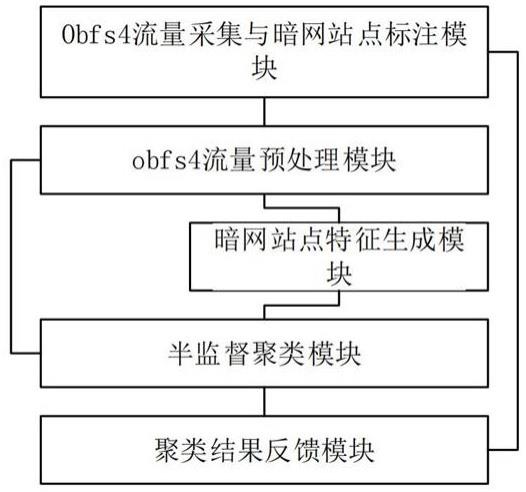
一种基于半监督聚类学习的暗网站点会话识别系统,基于所述的一种基于半监督聚类学习的暗网站点会话识别方法,包括依次电相连的以下模块:obfs4流量采集与暗网站点标注模块:用以,利用配置有obfs4插件的tor浏览器访问不同的暗网站点,在客户端采集obfs4流量的数据,并在pcap文件的文件名中标出访问的onion地址,得到带暗网站点标记的流量样本数据;obfs4流量预处理模块:用以,对pcap格式的流量数据进行预处理,得到带暗网站点标记的会话样本数据;暗网站点特征生成模块:用以,基于步骤s2中的带暗网站点标记的会话样本数据,利用深度学习cnn算法提取基于obfs4流量下的暗网站点特征向量;半监督聚类模块:用以,基于步骤s2得到的带暗网站点标记的会话样本数据以及s3中提取的基于obfs4流量下的暗网站点特征向量,利用半监督聚类算法对未知会话样本实现暗网站点onion地址的识别;聚类结果反馈模块:用以,对obfs4流量的聚类结果进行可视化展示,筛选出异常类簇,并结合人工经验,标注出异常类簇对应的暗网站点onion地址,并将标注后的暗网站点onion地址添加至步骤s1中的带暗网站点标记的流量样本数据中;obfs4流量预处理模块还与半监督聚类模块电相连。
[0014]
本发明相比于现有技术,具有以下有益效果:(1)本发明基于obfs4流量利用深度学习自动提取暗网站点会话特征,提升特征的表征性,降低对人工提取暗网网页的特征的依赖度,从而提升识别方法的泛化性;(2)本发明基于少量的暗网站点标注样本,将半监督聚类学习运用到暗网站点识别中,使其不需要大量标注样本,提升识别方法的实用性,有利于工程实现。
附图说明
[0015]
图1为本发明所述的一种基于半监督聚类学习的暗网站点会话识别系统的部署图;图2为本发明所述的一种基于半监督聚类学习的暗网站点会话识别方法的流程图;图3为本发明所述的一种基于半监督聚类学习的暗网站点会话识别系统的结构示意图;图4为实施例2记载的本发明的步骤s1的流程图;图5为实施例2记载的本发明的步骤s4的流程图;图6为实施例2记载的本发明的暗网站点特征生成模块的结构示意图。
具体实施方式
[0016]
下面结合实施例及附图,对本发明作进一步的详细说明,但本发明的实施方式不限于此。
[0017]
实施例1如图1至图6所示,一种基于半监督聚类学习的暗网站点会话识别方法,利用深度学习cnn算法自动提取obfs4网桥下暗网站点会话的特征,并利半监督聚类算法对暗网站点的onion地址进行识别(可优选利用seeded-kmeans半监督算法对暗网站点的onion地址的识别)。
[0018]
作为一种优选的技术方案,包括以下步骤:s1,obfs4流量采集与暗网站点标注:利用配置有obfs4插件的tor浏览器访问不同的暗网站点,在客户端采集obfs4流量的数据,并在pcap文件的文件名中标出访问的onion地址,得到带暗网站点标记的流量样本数据;s2,obfs4流量预处理:对pcap格式的流量数据进行预处理,得到带暗网站点标记的会话样本数据;s3,暗网站点特征生成:基于步骤s2中的带暗网站点标记的会话样本数据,利用深度学习cnn算法提取基于obfs4流量下的暗网站点特征向量;s4,半监督聚类:基于步骤s2得到的带暗网站点标记的会话样本数据以及s3中提取的基于obfs4流量下的暗网站点特征向量(利用cnn提取与生成obfs4流量下的暗网站点特征向量),利用半监督聚类算法对未知会话样本实现暗网站点onion地址的识别;s5,聚类结果反馈:对obfs4流量的聚类结果进行可视化展示,筛选出异常类簇(异常类簇即非已知暗网站点标记的类簇),并结合人工经验,标注出异常类簇对应的暗网站点onion地址,并将标注后的暗网站点onion地址添加至步骤s1中的带暗网站点标记的流量样本数据中。
[0019]
本发明针对现有从网络流量层面识别暗网站点会话的方法泛化性不足,且由于暗网站点流量数据采集难、标注成本高,现有识别方法实用性较低的问题,本发明提出了一种基于半监督聚类学习的暗网站点会话识别方法及装置。基于配置obfs4网桥的tor 浏览器客户端的流量数据(即obfs4流量),利用深度学习自动提取obfs4流量下暗网站点会话的特征,降低对专家知识的依赖性;并通过半监督聚类学习,在标注样本数量少的条件下,有效
识别暗网站点会话,提升识别方法的泛化性与实用性。
[0020]
作为一种优选的技术方案,步骤s1包括以下步骤:s11,判断是否为测试阶段;若是,则获取网关镜像流量,生成pcap流量数据,然后进入步骤s2;若否,则进入步骤s12;s12,在tor浏览器使用obfs4网桥,并进行网络连接;s13,获取.onion服务的列表;s14,获取第一条onion地址;s15,运行wireshark,访问步骤s14中获取的onion地址,保存pcap文件,并用步骤s14中获取的onion地址作为标注;s16,获取下一条onion地址;s17,判断onion地址是否为空;若是,则进入步骤s2;若否,则返回步骤s15。
[0021]
通过以上步骤,较好地实现了obfs4流量采集与暗网站点标注。
[0022]
作为一种优选的技术方案,步骤s2包括以下步骤:s21,解析流量数据,过滤广播流量、icmp协议、udp流量,并对会话进行重组,提取会话五元组信息;s23,判断经步骤s21过滤后的会话协议类型是否为未知协议;若是,则保留会话;否则,过滤该会话;s24,对保留的会话信息进行存储,并提取会话中前100个交互报文的前1024个字节,若不足1024字节,则利用0xff进行填充至1024字节,利用填充后的交互报文构成会话字节矩阵,并将会话字节矩阵转为灰度图像。
[0023]
通过以上步骤,较好地实现了obfs4流量预处理。
[0024]
作为一种优选的技术方案,步骤s3包括以下步骤:s31,构建并训练暗网站点特征生成模型;s32,将会话灰度数据输入至训练后的暗网站点特征生成模型,利用深度学习提取obfs4流量中的暗网站点特征,将提取的暗网站点特征输出。
[0025]
作为一种优选的技术方案,步骤s31包括以下步骤:s311,构建暗网站点特征生成模型:利用cnn网络提取obfs4流量下的暗网站点特征;s312,利用有暗网站点标注的obfs4流量训练暗网站点特征生成模型:将会话灰度图像依次通过3*3的卷积层、2*2池化层、3*3的卷积层、全连接层、输出层进行处理,得到暗网站点特征生成模型识别的结果及其置信度,识别结果包括暗网站点的onion地址、暗网站点的onion地址的置信度,其中,全连接层中使用sigmod函数;通过不断调整暗网站点特征生成模型参数,重复进行训练,直至置信度达到设定的阈值,输出暗网站点特征生成模型识别的结果及其置信度;s313,删除已训练的暗网站点特征生成模型的全连接层、输出层以及置信度,并将其保存为训练后的暗网站点特征生成模型。
[0026]
通过以上步骤,较好地实现了暗网站点特征生成。
[0027]
作为一种优选的技术方案,步骤s4包括以下步骤:s41,输入未知会话的灰度数据;
s42,利用暗网站点特征生成模型,提取未知会话的特征向量;s43,将已有暗网站点标签的流量会话数据作为种子集,采用最大期望算法将样本划分为k个簇,计算步骤s41输入的未知会话与每个类簇的距离;其中,k为已知暗网站点的onion地址数,初始化的集群中心是每个簇类的均值;s44,得到聚类结果:若该会话与距离最近的类中心距离小于设定阈值(设定的阈值越小,识别准确性越高,优选0.05),则认为该会话为最近的暗网站点类簇的暗网站点,并对会话进行标注;否则,认为该会话为非已知的暗网站点会话。
[0028]
通过以上步骤,较好地实现了半监督聚类。
[0029]
作为一种优选的技术方案,步骤s5包括以下步骤:s51,将聚类结果以图形化结果展示,形成散点类簇图;s52,通过界面查看是否存在异常类簇,确认异常类簇是否为新的暗网站点;其中,异常类簇指不含有暗网站点标注的类簇;s53,若确认异常类簇为新的暗网站点,则结合人工经验,标注出异常类簇对应的暗网站点onion地址,并将标注后的暗网站点onion地址添加至步骤s1中的带暗网站点标记的流量样本数据中。
[0030]
通过以上步骤,较好地实现了聚类结果反馈。
[0031]
一种基于半监督聚类学习的暗网站点会话识别系统,基于所述的一种基于半监督聚类学习的暗网站点会话识别方法,包括依次电相连的以下模块:obfs4流量采集与暗网站点标注模块:用以,利用配置有obfs4插件的tor浏览器访问不同的暗网站点,在客户端采集obfs4流量的数据,并在pcap文件的文件名中标出访问的onion地址,得到带暗网站点标记的流量样本数据;obfs4流量预处理模块:用以,对pcap格式的流量数据进行预处理,得到带暗网站点标记的会话样本数据;暗网站点特征生成模块:用以,基于步骤s2中的带暗网站点标记的会话样本数据,利用深度学习cnn算法提取基于obfs4流量下的暗网站点特征向量;半监督聚类模块:用以,基于步骤s2得到的带暗网站点标记的会话样本数据以及s3中提取的基于obfs4流量下的暗网站点特征向量,利用半监督聚类算法对未知会话样本实现暗网站点onion地址的识别;聚类结果反馈模块:用以,对obfs4流量的聚类结果进行可视化展示,筛选出异常类簇,并结合人工经验,标注出异常类簇对应的暗网站点onion地址,并将标注后的暗网站点onion地址添加至步骤s1中的带暗网站点标记的流量样本数据中;obfs4流量预处理模块还与半监督聚类模块电相连。
[0032]
实施例2如图1至图6所示,作为实施例1的进一步优化,在实施例1的基础上,本实施例还包括以下技术特征:对obfs4网桥的tor 浏览器客户端的流量数据(即obfs4流量)进行分析,提出一种基于半监督聚类学习的暗网站点会话识别方法及系统。通过在旁路部署一种基于半监督聚类学习的暗网站点会话识别系统,对镜像流量进行分析,将分析与识别结果反馈至管理员。此外,管理员也可通过控制指令下发启动、停止等命令。部署拓扑如图1所示。
[0033]
基于半监督聚类学习的暗网站点会话识别系统的整体框架主要包括obfs4流量采集与暗网站点标注模块、obfs4流量预处理模型、暗网站点特征生成模块、半监督聚类模块,以及聚类结果反馈模块。
[0034]
本发明共涉及5个模块,包括:(1)obfs4流量采集与暗网站点标注模块:该模块主要通过配置有obfs4插件的tor浏览器访问不同的暗网站点,在客户端采集obfs4流量的数据,并在流量pcap包中标注暗网站点信息。
[0035]
(2)流量预处理模块:该模块对pcap格式的流量数据进行预处理,主要包括会话重组以及无关流量的过滤。
[0036]
(3)暗网站点特征生成模块:该模块主要基于暗网站点的标注数据,利用深度学习提取obfs4流量中的暗网站点特征。
[0037]
(4)半监督聚类模块:该模块主要基于现有的标注数据及其特征,对未知流量,通过半监督聚类算法实现对暗网站点的识别。
[0038]
(5)聚类结果反馈模块:该模块主要为可视化展示,对obfs4流量的聚类结果进行可视化展示,并结合人工经验,发现异常类簇(如未知标签的新类簇),并在暗网标注中进行反馈与更新。
[0039]
本发明整体流程图如图2所示:更具体地:一、本发明中的obfs4流量采集与暗网站点标注的过程描述如下:第1步:判断是否为测试阶段,若为测试阶段,则获取网关镜像流量,并保存为pcap文件格式,结束;否则,进入步骤2。
[0040]
第2步:在tor浏览器中,配置obfs4网桥,使网络可以连通;第3步:获取待访问的暗网站点列表;第4步:对每一个暗网站点依次进行访问,并利用wireshark采集tor浏览器客户端流量,并用站点名为标注。
[0041]
二、本发明中的流量预处理的过程描述如下:根据obfs4的通信原理,obfs4网桥客户端接收经过tor加密的payload,然后使用obfs4函数对其再次封装,在会话层面表现为未知协议的tcp会话。本发明基于上述原理,设计如下预处理步骤,筛选出测试阶段的疑似obfs4流量。
[0042]
第1步:解析流量数据,过滤广播流量、icmp协议、udp流量,并对会话进行重组,并提取会话五元组信息;第2步:过滤http、tls、dns、ssh等协议的会话。
[0043]
第3步:判断会话协议类型是否为未知协议,若是,则保留会话;否则,过滤该会话。
[0044]
第4步:对保留的会话信息进行存储,并提取会话中前100个交互报文的前1024个字节,若不足1024字节,则利用0xff进行填充至1024字节,以此构成会话字节矩阵,并将此转为灰度图像。
[0045]
三、本发明中的暗网站点特征生成的过程描述如下:本发明中的暗网站点特征生成模块主要包含深度学习模型构建与训练、生成特征两个步骤。本发明使用半监督深度学习的方式,通过少量的标注数据训练网络,提取obfs4
会话特征。
[0046]
第1步:模型构建与训练;step1:利用有暗网站点标注的obfs4流量训练cnn网络,对输入的会话灰度图像进行第一次卷积运算(可使用3*3的卷积核),再使用2*2核进行池化,其次在第二次卷积中使用3*3的卷积,并在全连接层中使用sigmod函数,并输出网络识别的结果与置信度,如下图所示。通过不断调整模型参数,重复进行训练,直至置信度达到可接受的阈值(该阈值可自定义设置,为提高拦截的精确率,本技术中默认为0.95)。
[0047]
step2:删除已训练cnn网络模型的全连接层、输出层以及置信度,并将其保存为特征生成模型。
[0048]
第2步:生成特征;输入会话灰度数据,将特征生成模型的输出作为特征。
[0049]
四、本发明中的半监督聚类的过程描述如下:半监督聚类模块主要实现了暗网站点的识别,其流程如下图所示:第1步:输入未知会话的灰度数据;第2步:利用特征生成模型,提取未知会话的特征;第3步:将已有暗网站点标签的流量会话数据作为种子集,采用最大期望算法将样本划分为k个簇(k为已知暗网站点的标签数),初始化的集群中心是每个簇类的均值,计算该未知会话与每个类簇的距离;第4步:若该会话与距离最近的类中心距离小于0.05,则认为该会话为此类的暗网站点,并对会话进行标注;否则认为非已知的暗网站点会话。
[0050]
五、本发明中的聚类结果反馈的过程描述如下:第1步:将聚类结果以图形化结果展示,形成散点类簇图;第2步:管理员通过界面查看是否存在异常类簇,即不含有暗网站点标注的类簇,通过人工确认,确认异常类簇是否为新的暗网站点;第3步:若确认为新的暗网站点,则将暗网站点标注信息与会话信息反馈至暗网站点标注模块,增加标注样本。
[0051]
本发明针对现有从网络流量层面识别暗网站点会话的方法泛化性不足,且由于暗网站点流量数据采集难、标注成本高,现有识别方法实用性较低的问题,本发明提出了一种基于半监督聚类学习的暗网站点会话识别方法及系统。基于配置obfs4网桥的tor 浏览器客户端的流量数据(即obfs4流量),利用深度学习自动提取obfs4流量下暗网站点会话的特征,降低对专家知识的依赖性;并通过半监督聚类学习,在标注样本数量少的条件下,有效识别暗网站点会话,提升识别方法的泛化性与实用性。
[0052]
如上所述,可较好地实现本发明。
[0053]
本说明书中所有实施例公开的所有特征,或隐含公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合和/或扩展、替换。
[0054]
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,依据本发明的技术实质,在本发明的精神和原则之内,对以上实施例所作的任何简单的修改、等同替换与改进等,均仍属于本发明技术方案的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1