一种恶意周期行为检测方法与流程
1.本发明涉及信息安全技术领域,具体涉及一种恶意周期行为检测方法。
背景技术:
2.在信息安全领域,周期行为(beaconing)指网络设备之间具有固定周期,或具有规律性动态周期的通信行为。良性周期行为对信息系统、网络安全没有威胁,例如操作系统、杀毒软件定期向服务器请求更新,时间校准服务的自动校准行为等。恶性周期行为对信息安全威胁很大,最典型的恶性周期行为存在于命令和控制(c&c)攻击场景:被c&c攻陷的感染机通常会有规律地向控制机发起通信,以便于感知哪些感染机是活动且受控的;此外,一些低频率攻击,如低速拒绝服务攻击、低频口令爆破攻击等,也符合恶性周期行为的特征。
3.在大流量的复杂网络环境中,这种恶性周期行为更容易隐藏;另一方面,新型攻击通常采用更多干扰技术,严重削弱传统方法对恶意周期行为的检测效果。因此,亟需一种更为有效的恶意周期行为检测方法,以此提升发现网络威胁的能力、保障信息安全。
4.一类基于时序的方法,大多存在抗干扰性、鲁棒性低、漏报率高的不足,实际网络环境中,当设备下线造成请求周期中断,或恶意程序主动中断、休眠,或其他服务器刻意在其恶意行为的周期中加入随机扰动时,现有方法漏报率显著增加,例如:
5.公布号为cn106850647b的专利公开了一种基于dns请求周期性的恶意域名检测算法,该方法首先将dns请求记录处理成柱状图数据,用jeffrey散度算法计算相似性,当相似性低于阈值时判定为周期行为时判定为恶意域名,该方法存在鲁棒性低、漏报率高的不足。
6.公布号为cn108347447b的专利公开了一种基于周期性通讯行为分析的p2p僵尸网络检测方法,该方法主要原理是:先将访问时间戳序列升序排列,再求其一阶差分,再求一阶差分序列的变异系数,当该变异系数小于阈值时数据量被判定为周期性数据流,产生周期性数据流的主机为僵尸机,因此该方法同样存在鲁棒性低、漏报率高的不足。
7.另一类基于机器学习的检测方法,非常依赖已采集的恶意行为的样本数据,且关键算法大多属于“黑箱模型”。应对新型攻击时,旧样本失效,检测结果不理想,这类方法存在成本高、可解释性差,且准确率、漏报率不稳定的不足。
技术实现要素:
8.本发明的目的在于提供一种恶意周期行为检测方法,应用场景广泛灵活、可以检测新型高级攻击:适用于多种复杂的攻击检测场景,如命令与控制攻击检测场景、低速拒绝服务攻击检测场景、dns恶意域名检测场景、大规模流量数据的恶意攻击检测场景、基于加密协议攻击的检测场景等,还在于能够降低检测成本、提高准确度、降低漏报率和提高可解释性。
9.本发明的目的可以通过以下技术方案实现:
10.一种恶意周期行为检测方法,包括以下步骤:
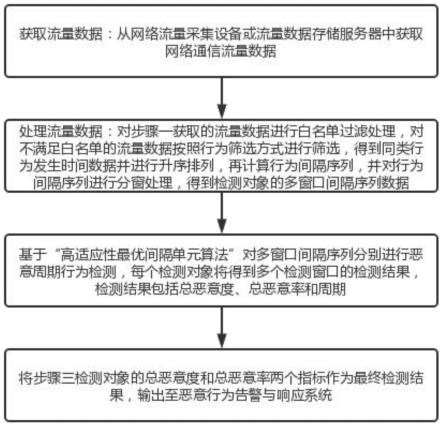
11.步骤一:获取流量数据:从网络流量采集设备或流量数据存储服务器中获取网络
通信流量数据;
12.步骤二:处理流量数据:对步骤一获取的流量数据进行白名单过滤处理,对不满足白名单的流量数据按照行为筛选方式进行筛选,得到同类行为发生时间数据并进行升序排列,再计算行为间隔序列,并对行为间隔序列进行分窗处理,得到检测对象的多窗口间隔序列数据;
13.步骤三:基于“高适应性最优间隔单元算法”对多窗口间隔序列分别进行恶意周期行为检测,每个检测对象将得到多个检测窗口的检测结果,检测结果包括总恶意度、总恶意率和周期;
14.步骤四:将步骤三检测对象的总恶意度和总恶意率两个指标作为最终检测结果,输出至恶意行为告警与响应系统。
15.作为本发明进一步的方案:步骤一中,所述流量数据包含的主要字段包括客户端ip、服务端ip和行为发生时间。
16.作为本发明进一步的方案:步骤二中,行为筛选方式在不同应用场景中,包括多种筛选方式,如:
17.客户端ip+服务端ip+应用层协议;
18.客户端ip+服务端ip+应用层协议+应用层会话持续时间小于x秒;
19.客户端ip+应用层协议+应用层会话总流量小于等于y比特;
20.应用层协议+应用层登录用户名+应用层登录失败;
21.客户端ip+其他协议层行为;
22.其中,x和y是根据待检测协议历史数据计算得到的经验阈值。
23.作为本发明进一步的方案:步骤二中,行为间隔序列的计算方法是通过计算后一个行为时间点距离上一个行为时间点的时间差,即得到行为间隔时间。
24.作为本发明进一步的方案:步骤二中,检测对象的多窗口间隔序列数据的获取为设置2个分窗参数:窗口大小window_size和分窗步长window_step,按照每window_size个间隔元素划分一次窗口,再向前滑动window_step个间隔元素再次划分一次窗口,直到最后所剩间隔元素不足窗口大小时停止;
25.其中,window_size、window_step均为正整数。
26.作为本发明进一步的方案:步骤三中,总恶意度为多个窗口的“恶意度”的均值计算得到;
27.总恶意率为多个窗口的“是否恶意”的恶意比例计算得到。
28.作为本发明进一步的方案:步骤三中,高适应性最优间隔单元算法的步骤如下:
29.k1:输入:待检测的单个间隔序列series、下界系数l、上界系数u、搜索步数用step_size、标准化系数n;
30.k2:计算多个参数:搜索下界lower、搜索上界upper、计算搜索步长step;计算离散搜索范围search_scope;
31.其中,lower=min(series)*l,其中min表示求序列series的最小值;
32.upper=median(series)*u,其中median表示求序列series的中位数;
33.step=(upper-lower)/step_size;
34.search_scope=range(lower,upper,step);
35.其中,range表示从lower开始,每隔step长度取1个搜索点,直到upper为止,总共得到step_size个搜索点;
36.k3:计算离散搜索范围中每个搜索点“损失值”,得到损失值序列cost;
37.k4:计算周期unit和恶意度anomaly;
38.其中,周期:
39.恶意度:
40.求cost中最小值时其下标i的取值,用imin表示,n为输入的标准化系数,rl1为损失函数;
41.k5:通过经验阈值法或统计学方法或机器学习方法确定恶意度阈值t;
42.k6:判断检测对象是否恶意anomaly_binary,如下:
[0043][0044]
其中,t为恶意度阈值;1表示“恶意”,0表示“非恶意”;
[0045]
k7:输出单个间隔序列的检测结果:恶意度anomaly、是否恶意anomaly_binary和周期unit;
[0046]
其中,下界系数l取值为0.5-1之间的正数,上界系数u=1;搜索步数step_size=1000,标准化系数n=4,恶意度阈值t=0.45,
[0047]
作为本发明进一步的方案:k3中,损失值序列cost的获取步骤如下:
[0048]
k31:ui是离散搜索范围search_scope中第i个元素;
[0049]
k32:其中cost_function表示损失函数;
[0050]
cost_function损失函数的计算公式,包括:
[0051]
k321:rl1损失函数:
[0052]
k322:rlk损失函数:
[0053]
其中“c”表示序列x的所有元素个数,表示四舍五入取整运算符,“||”表示取绝对值运算符,k是正整数。
[0054]
本发明的有益效果:发明应用场景广泛灵活、可以检测新型高级攻击:适用于多种复杂的攻击检测场景,如命令与控制攻击检测场景、低速拒绝服务攻击检测场景、dns恶意域名检测场景、大规模流量数据的恶意攻击检测场景、基于加密协议攻击的检测场景,具有成本低、准确度高、漏报率低、可解释性高的特点。
附图说明
[0055]
下面结合附图对本发明作进一步的说明。
[0056]
图1是本发明流程图;
[0057]
图2是本发明处理流量数据流程图;
[0058]
图3是本发明高适应性最优间隔单元算法流程图。
具体实施方式
[0059]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0060]
请参阅图1-图3所示,本发明为一种恶意周期行为检测方法,包括如下步骤:
[0061]
步骤一:获取流量数据:从网络流量采集设备或流量数据存储服务器中获取网络通信流量数据(简称流量数据);
[0062]
步骤二:处理流量数据:对步骤一获取的流量数据进行白名单过滤处理,对不满足白名单的流量数据按照行为筛选方式进行筛选,得到同类行为发生时间数据并进行升序排列,再计算行为间隔序列,并对行为间隔序列进行分窗处理,得到检测对象的多窗口间隔序列数据;
[0063]
步骤三:采用“高适应性最优间隔单元算法”对多窗口间隔序列分别进行恶意周期行为检测,每个检测对象将得到多个检测窗口的检测结果,检测结果包括总恶意度、总恶意率和周期;
[0064]
步骤四:将检测结果输出至恶意行为告警与响应系统。
[0065]
步骤一中,流量数据包含的主要字段包括客户端ip、服务端ip和行为发生时间;
[0066]
在一些实施例中,流量数据还包括或部分包括:传输层协议、源端口号、目的端口号、应用层协议、应用层登录用户名、应用层登录是否成功、深度包识别的应用层行为、应用层会话持续时间、应用层会话流量(含总流量、上行流量、下行流量)、应用层会话数据包数(含总包数、上行包数、下行包数)、其他协议层行为(如“向dns服务器发起对某域名的请求”、“发起ping请求”、“发起tck syn请求”);
[0067]
其中,上行流量的方向为“客户端”到“服务端”的流量;
[0068]
下行流量的方向为“服务端”到“客户端”的流量。
[0069]
步骤二中,流量数据的处理包括如下步骤:
[0070]
s1:对流量数据进行白名单过滤,得到不满足白名单条件的流量数据(黑名单流量数据);
[0071]
s2:将黑名单流量数据按照行为筛选方式进行处理,筛选同类的行为流量数据,选取“行为发生时间”列,得到同类行为发生时间数据;
[0072]
s3:将上述同类行为发生时间数据按升序排列,再计算行为间隔序列;
[0073]
s4:将上述行为间隔序列数据进行分窗处理,得到检测对象的多窗口检测序列数据。
[0074]
其中,白名单是通过搜集的合法软件或服务的特征列表,满足白名单条件的软件或服务不具威胁性,其流量数据不做检测。
[0075]
s2中,行为筛选方式在不同应用场景、不同实施例中,根据步骤一中流量数据的类型包括多种筛选方式,如下:
[0076]
s21:在一些实施例中,筛选条件为:“客户端ip+服务端ip+应用层协议”,即筛选客户端与服务端之间的某应用层协议的所有流量数据,作为检测对象;应用于常规场景下的恶意周期行为检测;
[0077]
s22:在一些实施例中,筛选条件为:“客户端ip+服务端ip+应用层协议+应用层会话持续时间小于x秒”,即筛选客户端与服务端之间的、某应用层协议的、具有某种持续时间特征的所有流量数据,作为检测对象;应用于常规场景下的恶意周期行为检测;其中“x”是根据待检测协议历史数据计算得到的经验阈值;
[0078]
s23:在一些实施例中,筛选条件为:“客户端ip+应用层协议+应用层会话总流量小于等于y比特”,即筛选客户端的、某应用层协议的、具有某种流量特征的所有流量数据,作为检测对象;应用于客户端受控于一个或多个c&c服务器场景下的恶意周期行为检测;也可以应用于加密协议攻击场景下的恶意周期行为检测;其中“y”是根据待检测协议历史数据计算得到的经验阈值;
[0079]
s24:在一些实施例中,筛选条件为:“应用层协议+应用层登录用户名+应用层登录失败”,即筛选某应用层协议的某用户名的失败登录流量数据,作为检测对象;应用于针对某应用的特定用户名的低速口令破解场景下的恶意周期行为检测;
[0080]
s25:在一些实施例中,筛选条件为:“客户端ip+其他协议层行为”,即筛选客户端某协议行为的流量数据作为检测对象;应用于针对某类特定行为的恶意周期行为检测;其中“其他协议层行为”可以是“向dns服务器发起对某域名的请求”、“发起ping请求”、“发起tcp syn请求”等。
[0081]
s3中,行为间隔序列的计算方法如下:
[0082]
计算后一个行为时间点距离上一个行为时间点的时间差,即得到行为间隔时间。
[0083]
s4中,得到检测对象的多窗口间隔序列数据w,方法如下:
[0084]
设置2个分窗参数:窗口大小(window_size)和分窗步长(window_step),按照每window_size个间隔元素划分一次窗口,再向前滑动window_step个间隔元素再次划分一次窗口,直到最后所剩间隔元素不足窗口大小时停止;
[0085]
上述参数window_size、window_step均为正整数,能够根据应用场景、部署服务器的计算能力灵活设置。
[0086]
s41:在一些实施例中,当服务器性能不足时,考虑适当增大window_size和window_step;
[0087]
优选地,window_size=30,window_step=1。
[0088]
具体的,当经过s1和s2处理后,得到以下同类行为发生时间数据:[1600326765.5388,1600327125.4243,1600327245.8115,1600327488.2358,1600327609.2651,1600327727.1547],作为样例【数据1】;
[0089]
数据1
[0090]
同类行为发生时间数据1600326765.53881600327125.42431600327245.81151600327488.23581600327609.26511600327727.1547
[0091]
对【数据1】进行升序排列和计算行为间隔序列,得到【数据2】,【数据2】由【数据1】
排序后的同类行为发生时间数据计算时间差得到;
[0092]
数据2
[0093]
行为间隔序列数据-359.8855120.3872242.4243121.0293117.8896
[0094]
对【数据2】进行分窗处理,得到3个分窗之后的间隔序列数据,即【数据3】;
[0095][0096][0097]
步骤三中,高适应性最优间隔单元算法的步骤如下;
[0098]
w1:输入:待检测的单个间隔序列(用series表示)、下界系数(用l表示)、上界系数(用u表示)、搜索步数(用step_size表示)、标准化系数n;
[0099]
w2:计算多个参数:搜索下界(用lower表示)、搜索上界(用upper表示)、计算搜索步长(用step表示);计算离散搜索范围(用search_scope表示);公式如下:
[0100]
lower=min(series)*l,其中min()表示求序列series的最小值;
[0101]
upper=median(series)*u,其中median()表示求序列series的中位数;
[0102]
step=(upper-lower)/step_size
[0103]
search_scope=range(lower,upper,step)
[0104]
其中,range()表示从lower开始,每隔step长度取1个搜索点,直到upper为止,总共得到step_size个搜索点;
[0105]
w3:计算离散搜索范围中每个搜索点“损失值”,得到损失值序列cost;步骤如下:
[0106]
w31:ui是离散搜索范围search_scope中第i个元素;
[0107]
w32:其中cost_function表示损失函数;
[0108]
其中,cost_function损失函数的计算公式,是以下两种之一:
[0109]
a.rl1损失函数:
[0110]
b.rlk损失函数:
[0111]
其中“c”表示序列x的所有元素个数,表示四舍五入取整运算符,“||”表示取绝对值运算符,k是正整数;
[0112]
w4:计算周期(用unit表示)和恶意度(用anomaly表示);方法步骤如下:
[0113]
w41:求cost中最小值时其下标i的取值,用imin表示;
[0114]
w42:周期:
[0115]
w43:恶意度:
[0116]
其中n为输入的标准化系数,rl1为损失函数;
[0117]
w5:确定恶意度阈值(用t表示);该方法具体是以下三种之一:
[0118]
w51:经验阈值法:凭借专业技术人员经验确定t值;
[0119]
w52:统计学方法:基于历史攻击数据或模拟渗透测试攻击数据,用正态分布“小概率事件”思想确定t值;
[0120]
w53:机器学习方法:基于历史攻击数据或模拟渗透测试攻击数据,建立解释度高的有监督学习模型,确定t的取值;优选的机器学习方法是“决策树”算法;
[0121]
w6:判断检测对象是否恶意(用anomaly_binary表示);公式如下:
[0122][0123]
其中t为恶意度阈值;1表示“恶意”,0表示“非恶意”;
[0124]
w7:输出单个间隔序列的检测结果:恶意度(anomaly),是否恶意(anomaly_binary)、周期(unit)。
[0125]
优选地,下界系数l取值为0.5-1之间的正数,上界系数u=1;搜索步数step_size=1000,标准化系数n=4,恶意度阈值t=0.45。
[0126]
本发明的核心点之一:在于流量数据的字段包括客户端ip、服务端ip、行为发生时间、传输层协议、源端口号、目的端口号、应用层协议、应用层登录用户名、应用层登录是否成功、深度包识别的应用层行为、应用层会话流量、应用层会话数据包数、其他协议层行为;
[0127]
本发明的核心点之二:行为筛选方式在不同应用场景中,能够根据所述的“流量数据”灵活组合,得到多种组合筛选方案;如:
[0128]
(1)客户端ip+服务端ip+应用层协议
[0129]
(2)客户端ip+服务端ip+应用层协议+应用层会话持续时间小于x秒
[0130]
(3)客户端ip+应用层协议+应用层会话总流量小于等于y比特
[0131]
(4)应用层协议+应用层登录用户名+应用层登录失败
[0132]
(5)客户端ip+其他协议层行为
[0133]
其中,x和y是根据待检测协议历史数据计算得到的经验阈值。
[0134]
本发明的核心点之三:应用场景广泛灵活、可以检测新型高级攻击:适用于多种复
杂的攻击检测场景,例如命令与控制攻击检测场景、低速拒绝服务攻击检测场景、dns恶意域名检测场景、大规模流量数据的恶意攻击检测场景、基于加密协议攻击的检测场景等。
[0135]
以上对本发明的一个实施例进行了详细说明,但所述内容仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1