一种基站与核心网的RESET消息优化的方法与流程
一种基站与核心网的reset消息优化的方法
技术领域
1.本发明属于it与软件开发技术领域,具体涉及一种基站与核心网的reset消息优化的方法。
背景技术:
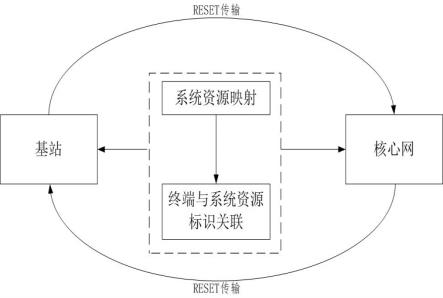
2.在5g网络中,当基站和核心网之间的系统资源出现故障需要发送reset消息给非故障一方且受影响的不是故障一方对应非故障一方的所有ue时,将这部分系统资源对应的resource id列表发给非故障方依据该消息中的resource id找到相关联的所有ue,释放非故障方这些ue占用的系统资源和网络资源场景下,消息过多并发造成网络时延及资源的开销过大。reset消息传递上限一般为1000个,超过则需要缓存等待。
3.例如现有专利技术(cn113301598b)公开了一种基站及核心网的资源管理方法,通过将系统资源抽象为系统资源标识resource id,系统资源标识resource id和系统资源可以一对一映射(如1个resource id和1个进程对应),也可以一对多映射(如1个resource id和多个进程对应),并将ue与系统资源标识关联,从而实现在reset过程中只需发送系统资源标识resource id,无需发送大量的ue标识,减少发送的消息包大小和发送消息的条数,减少设备间接口处模块的负担,减少占用基站和核心网之间网络传输资源,降低成本投入。但是该方法没有提出解决基站和核心网之间网络时延及资源的开销过大以及reset消息传递的优化方案。
技术实现要素:
4.本发明针对现有技术的问题,提供一种基站与核心网的reset消息优化的方法,通过本方法可以有效解决基站和核心网之间网络时延及资源的开销过大问题,同时也可以使得reset消息(subtask)可共用taskmanager的进程,并且可以共用tcp连接和心跳消息,同时可以共用一些数据集和数据结构,从而减小资源的消耗。
5.为了实现上述发明目的,本发明的技术方案如下:一种基站与核心网的reset消息优化的方法,包括以下步骤:1)当核心网与基站之间发生网络故障时,故障一方主动发起携带自身标识的reset消息通知非故障一方;2)非故障一方收到reset消息后向flink的发送包含reset消息、ip信息的数据请求指令;3)flink收到reset消息请求后,通知taskmanager管理模块里创建task slots,并通过task slots存储reset消息;通过flink将reset消息以流的方式传递,最终分配给task slots,使传递的reset消息中不均匀的文件大小,可以均匀分布在taskslot里面;4) 将reset消息映射为一个subtask,对不同subtask不均匀的文件大小做插值处理;reset消息映射为一个subtask,多个subtask交叉部分形成算法链,可以共用资源,提高reset消息传输效率,减小资源消耗;
5)将经过插值处理提优后的subtask分别依次放入不同的task slot,同时使用智能分配模型结合flink里的task slot里的共享的slot将充分的利用分槽资源,从而完成subtask在taskmanager上的均匀分布。
6.插值处理会将subtask中大量重复的价值不大数据过滤掉,依次序放入task slot;避免过大的subtask传递到task slot,通过调度将它传递到共享的slot,其他资源相当的subtask均匀的放到多个taskslot里面。
7.进一步的,所述reset消息包括resource id。
8.进一步的,所述步骤4)中插值处理指采用二次插值方法,以每个cpu的核数为个数及相邻点做插值,得到二次插值。
9.进一步的,所述步骤5)中,所述智能分配模型公式如下:其中:x=分类对象的当前数值,y=分类对象的cpu的核数为个数相邻点做插值相邻点,i=分类对象的顺序号。
10.进一步的,所述每个taskmanager管理模块至少有一个task slots。
11.所述智能分配模型主要作用是对连续近似数据间隔取值,从而避免一个很大的reset消息传递给task slots造成数据阻塞。进故宫差值获取后就可以将数据变小,分摊给其他task slots。
12.所述taskmanager可划分多个task slot,默认数量可以以cpu的核数为准。
13.所述通过动态调整task slot的个数,用户可以自定义reset消息可以相互隔离。同时,使用智能分配模型结合flink里的task slot里的共享的slot将充分的利用分槽资源,使代价较大的subtask能够均匀的分布在taskmanager上;这样就使得reset消息可共用taskmanager的进程,并且可以共用tcp连接和心跳消息,同时可以共用一些数据集和数据结构,从而减小资源消耗。
14.本发明具有的优点及有益效果如下:本发明通过动态的调整task slot的个数,用户可以自定义reset消息(subtask)可以相互隔离;同时,使用共享的slot的将充分的利用分槽的资源,使代价较大的subtask能够均匀的分布在taskmanager上,这样就使得reset消息(subtask)可共用taskmanager的进程,并且可以共用tcp连接和心跳消息,同时可以共用一些数据集和数据结构,从而减小资源的消耗;本发明采用智能分配模型可以实现间隔均匀和flink sql引擎原理transformer时序处理更加匹配,还可以较真实还原task slot场景缺失数据。
附图说明
15.图1为本发明方法的工作示意图。
具体实施方式
16.下面结合具体实施例对本发明做进一步说明。
17.实施例:一种基站与核心网的reset消息优化的方法,包括以下步骤:
1)当核心网与基站之间发生网络故障时,故障一方主动发起携带自身标识的reset消息通知非故障一方;2)非故障一方收到reset消息后通过程序向flink的发送包含reset消息、ip信息的数据请求指令;3)flink收到reset消息请求后,通知taskmanager管理模块里创建task slots,并通过task slots存储reset消息;4) 将reset消息映射为一个subtask,对不同subtask不均匀的文件大小做插值处理;5)将经过插值处理提优后的subtask分别依次放入不同的task slot,同时使用智能分配模型结合flink里的task slot里的共享的slot将充分的利用分槽资源,从而完成subtask在taskmanager上的均匀分布。
18.所述reset消息包括resource id。
19.所述步骤4)中插值处理指采用二次插值方法,以每个cpu的核数为个数及相邻点做插值,得到二次插值。
20.所述步骤5)中,所述智能分配模型公式如下:其中:x=分类对象的当前数值,y=分类对象的cpu的核数为个数相邻点做插值相邻点,i=分类对象的顺序号。
21.所述每个taskmanager管理模块至少有一个task slots。
22.所述智能分配模型由二次插值方法构建,具体由于flink sql引擎原理采用代码生成技术(codegen)生成transformer算法进行代码编译为可执行的jobgraph的原理,因此我们利用transformer对一段时间的数据、资源占用数据进行持续分析,针对数据序列,发现内存容量异常前的潜在特征,使内存容量预警更精准。所述智能分配模型主要作用是对连续近似数据间隔取值,从而避免一个很大的reset消息传递给task slots造成数据阻塞。进故宫差值获取后就可以将数据变小,分摊给其他task slots。
23.首先,访问部署在taskmanager上的所有reset消息映射的子任务(subtask)等信息。
24.其次、为适应模型处理,对不同subtask的文件不均匀的文件大小做插值处理。采用二次插值方法,以每个cpu的核数为个数相邻点做插值,得到二次插值。即,人工智能算法提优后的subtask数据。
[0025] 最后,将经过人工智能算法提优后的subtask分别依次放入不同的task slot,从而完成子任务subtask在taskmanager上的均匀分布。
[0026]
文中所述术语定义如下:flink:开源流处理框架,将数据以流的形式进行传递,taskmanager:任务管理程序,通过该管理器创建多个task slots,每个占用taskmanager的一部分内存task slots: 进程插槽,subtask:算子,映射未一个reset消息,多个内容类似的reset消息会有较差内容,
有交叉的subtask组成算法链,可以共享资源,较快数据传输。
[0027]
resource id,是基站和核心网发送故障的时候字带的reset消息的id。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1