识别音频数据声音来源的方法、存储介质和电子设备与流程
1.本发明涉及计算机技术领域,具体而言,涉及一种识别音频数据声音来源的方法、存储介质和电子设备。
背景技术:
2.远程会议是一种常用的会议形式。在传统的远程会议中,由于展示与会人的画面,确定当前说话人的方式可以是:通过在远程会议产品设计中采用改变画面布局、设置画面高亮等方式标注当前说话人;或者根据与会人的画面,通过动作、口型等信息快速分辨当前说话人。
3.近年来,远程会议场景中出现越来越多的虚拟会议室,在虚拟会议室中,与会人的画面被与会人对应的虚拟形象代替,虚拟会议室的场景布局和与会人的虚拟形象绑定。此时,产品设计中难以通过改变场景布局标注当前说话人,虚拟会议室的听众也难以快速分辨当前说话人。
4.此外,在虚拟会议室中,可能出现多位与会人同时发言的情况,此时会议语音较为混杂,听众难以清晰地分辨语音,导致用户体验感差。
5.针对上述的问题,目前尚未提出有效的解决方案。
技术实现要素:
6.本发明实施例提供了一种识别音频数据声音来源的方法、存储介质和电子设备,以至少解决虚拟空间中出现多位说话人同时发言的情况下音源混杂、用户体验差的技术问题。
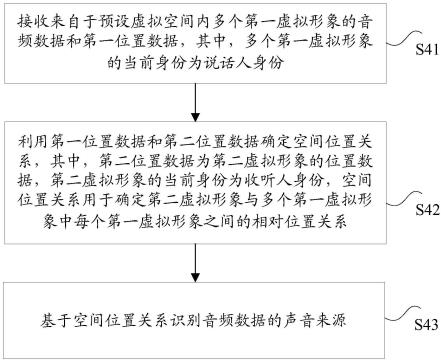
7.根据本发明实施例的一个方面,提供了一种识别音频数据声音来源的方法,包括:接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据的声音来源。
8.根据本发明实施例的另一方面,还提供了一种识别音频数据声音来源的方法,包括:接收来自于虚拟会议室内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为会议发言者身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为会议收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据在虚拟会议室内的声音来源。
9.根据本发明实施例的另一方面,还提供了一种识别音频数据声音来源的方法,包括:接收来自于虚拟课堂内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为课堂发言者身份;利用第一位置数据和第二位置数据确定空间位置
关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为课堂收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据在虚拟课堂内的声音来源。
10.根据本发明实施例的另一方面,还提供了一种计算机可读存储介质,上述计算机可读存储介质包括存储的程序,其中,在上述程序运行时控制上述计算机可读存储介质所在设备执行任意一项上述的识别音频数据声音来源的方法。
11.根据本发明实施例的另一方面,还提供了一种电子设备,包括:处理器;以及存储器,与上述处理器连接,用于为上述处理器提供处理以下处理步骤的指令:接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据的声音来源。
12.在本发明实施例中,接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份,通过利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系,进一步基于空间位置关系识别音频数据的声音来源。
13.容易注意到的是,通过本发明实施例,当预设虚拟空间内存在多个当前说话人时,通过多个当前说话人与收听人之间的相对位置关系,识别多个当前说话人的音频数据的声音来源,能够在预设虚拟空间内模拟人类的双耳效应确定说话人的方位,达到了在预设虚拟空间内根据多个说话人虚拟形象和收听人虚拟形象之间的相对位置关系识别多个说话人虚拟形象的音频数据的声音来源的目的,从而实现了在虚拟空间中出现多位说话人同时发言的情况下增强音频数据的辨识度、提高用户体验的技术效果,进而解决了虚拟空间中出现多位说话人同时发言的情况下音源混杂、用户体验差的技术问题。
附图说明
14.此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
15.图1示出了一种用于实现识别音频数据声音来源的方法的计算机终端(或移动设备)的硬件结构框图;
16.图2是根据本发明实施例的一种识别音频数据声音来源的方法的虚拟现实设备的硬件环境的示意图;
17.图3是根据本发明实施例的一种识别音频数据声音来源的方法的计算环境的结构框图;
18.图4是根据本发明实施例的一种识别音频数据声音来源的方法的流程图;
19.图5是根据本发明实施例的一种虚拟会议室的图形用户界面的示意图;
20.图6是根据本发明实施例的一种信号权重计算方式的示意图;
21.图7是根据本发明实施例的一种虚拟会议室中音频多声道回放过程的示意图;
22.图8是根据本发明实施例的一种音频数据双声道回放方式的示意图;
23.图9是根据本发明实施例的另一种识别音频数据声音来源的方法的流程图;
24.图10是根据本发明实施例的另一种识别音频数据声音来源的方法的流程图;
25.图11是根据本发明实施例的一种识别音频数据声音来源的装置的结构示意图;
26.图12是根据本发明实施例的一种可选的识别音频数据声音来源的装置的结构示意图;
27.图13是根据本发明实施例的另一种可选的识别音频数据声音来源的装置的结构示意图;
28.图14是根据本发明实施例的另一种识别音频数据声音来源的装置的结构示意图;
29.图15是根据本发明实施例的另一种可选的识别音频数据声音来源的装置的结构示意图;
30.图16是根据本发明实施例的又一种识别音频数据声音来源的装置的结构示意图;
31.图17是根据本发明实施例的另一种计算机终端的结构框图。
具体实施方式
32.为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
33.需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
34.首先,在对本发明实施例进行描述的过程中出现的部分名词或术语适用于如下解释:
35.虚拟会议室:是指通过线上的虚拟数字空间实现会议场景的应用产品。通过虚拟会议室,用户可以远程加入虚拟会议。用户终端可以通过三维渲染、虚拟现实(virtual reality,vr)等技术为用户还原会议场景,用户还可以通过用户终端关联的摄像头、话筒、扬声器等设备参加虚拟会议(如发言或收听)。
36.双耳效应:是指人类可以依靠双耳间的音量差、时间差和音色差判别声音方位的效应。
37.空间音频:是指通过多声道、环绕声等技术提供可以感知声音来源的空间位置信息的音频回放技术。
38.实施例1
39.根据本发明实施例,还提供了一种识别音频数据声音来源的方法实施例,需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
40.本发明实施例一所提供的方法实施例可以在移动终端、计算机终端或者类似的运算装置中执行。图1示出了一种用于实现识别音频数据声音来源的方法的计算机终端(或移动设备)的硬件结构框图。如图1所示,计算机终端10(或移动设备10)可以包括一个或多个(图中采用102a,102b,
……
,102n来示出)处理器102(处理器102可以包括但不限于微处理器(microcontroller unit,mcu)或可编程逻辑器件(field programmable gate array,fpga)等的处理装置)、用于存储数据的存储器104、以及用于通信功能的传输装置106。除此以外,计算机终端10还可以包括:显示器、输入/输出接口(i/o接口)、通用串行总线(universal serial bus,usb)端口(可以作为bus总线的端口中的一个端口被包括)、网络接口、光标控制设备(如鼠标、触控板等)、键盘、电源和/或相机。
41.本领域普通技术人员可以理解,图1所示的结构仅为示意,其并不对上述电子装置的结构造成限定。例如,计算机终端10还可包括比图1中所示更多或者更少的组件,或者具有与图1所示不同的配置。
42.应当注意到的是上述一个或多个处理器102和/或其他数据处理电路在本文中通常可以被称为“数据处理电路”。该数据处理电路可以全部或部分的体现为软件、硬件、固件或其他任意组合。此外,数据处理电路可为单个独立的处理模块,或全部或部分的结合到计算机终端10(或移动设备)中的其他元件中的任意一个内。如本发明实施例中所涉及到的,该数据处理电路作为一种处理器控制(例如与接口连接的可变电阻终端路径的选择)。
43.存储器104可用于存储应用软件的软件程序以及模块,如本发明实施例中的识别音频数据声音来源的方法对应的程序指令/数据存储装置,处理器102通过运行存储在存储器104内的软件程序以及模块,从而执行各种功能应用以及数据处理,即实现上述的识别音频数据声音来源的方法。存储器104可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器104可进一步包括相对于处理器102远程设置的存储器,这些远程存储器可以通过网络连接至计算机终端10。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
44.传输装置106用于经由一个网络接口与网络连接以接收或者发送数据。上述的网络具体实例可包括计算机终端10的通信供应商提供的有线和/或无线网络。在一个实例中,传输装置106包括一个网络适配器(network interface controller,nic),其可通过基站与其他网络设备相连从而可与互联网进行通讯。在一个实例中,传输装置106可以为射频(radio frequency,rf)模块,其用于通过无线方式与互联网进行通讯。
45.如图1所示的显示器可以例如触摸屏式的液晶显示器(lcd),该液晶显示器可使得用户能够与计算机终端10(或移动设备)的用户界面进行交互。
46.此处需要说明的是,在一些可选实施例中,上述图1所示的计算机设备(或移动设备)可以包括硬件元件(包括电路)、软件元件(包括存储在计算机可读介质上的计算机代码)、或硬件元件和软件元件两者的结合。应当指出的是,图1仅为特定具体实例的一个实
例,并且旨在示出可存在于上述计算机设备(或移动设备)中的部件的类型。
47.此处需要说明的是,在一些实施例中,上述图1所示的计算机设备(或移动设备)具有触摸显示器(也被称为“触摸屏”或“触摸显示屏”)。在一些实施例中,上述图1所示的计算机设备(或移动设备)具有图像用户界面(gui),用户可以通过触摸触敏表面上的手指接触和/或手势来与gui进行人机交互,此处的人机交互功能可选的包括如下交互:创建网页、绘图、文字处理、制作电子文档、游戏、视频会议、即时通信、收发电子邮件、通话界面、播放数字视频、播放数字音乐和/或网络浏览等、用于执行上述人机交互功能的可执行指令被配置/存储在一个或多个处理器可执行的计算机程序产品或可读存储介质中。
48.本发明实施例一所提供的方法实施例可以在虚拟现实(virtual reality,vr)设备或增强现实(augmented reality,ar)设备中执行。以vr设备为例,图2是根据本发明实施例的一种识别音频数据声音来源的方法的虚拟现实设备的硬件环境的示意图。如图2所示,虚拟现实设备204与终端206相连接,终端206与服务器202通过网络进行连接,上述虚拟现实设备204并不限定于:虚拟现实头盔、虚拟现实眼镜、虚拟现实一体机等,上述终端204并不限定于pc、手机、平板电脑等,服务器202可以为媒体文件运营商对应的服务器,上述网络包括但不限于:广域网、城域网或局域网。
49.可选地,本发明实施例的虚拟现实设备204包括:存储器2041、处理器2042和传输装置2043(图2中未示出)。存储器2041用于存储应用程序,该应用程序可以用于执行本发明实施例提供的识别音频数据声音来源的方法。处理器2042可以调用并执行存储器2041中存储的应用程序,以通过本发明实施例提供的识别音频数据声音来源的方法得到所识别的音频数据的声音来源。
50.可选地,本发明实施例的终端206也可以用于执行识别音频数据声音来源的方法,并通过vr设备或ar设备的显示画面展示音频数据的声音来源信息,或者通过vr设备或ar设备关联的音频输出设备播放执行识别音频数据声音来源的方法过程中生成的音频。
51.图2示出的硬件结构框图,不仅可以作为上述ar/vr设备(或移动设备)的硬件环境的示例性框图,还可以作为上述服务器的示例性框图。
52.图3是根据本发明实施例的一种识别音频数据声音来源的方法的计算环境的结构框图,图3以框图示出了使用上述图2所示的vr设备(或移动设备)作为计算环境301中计算节点的一种实施例。
53.仍然如图3所示,计算环境301包括运行在分布式网络上的多个(图3中采用310-1,310-2,
…
,来示出)计算节点(如服务器)。每个计算节点都包含本地处理和内存资源,终端用户302可以在计算环境301中远程运行应用程序或存储数据。应用程序可以作为计算环境301中的多个服务320-1(代表服务a),320-2(代表服务d),320-3(代表服务e)和320-4(代表服务h)进行提供。
54.仍然如图3所示,终端用户302可以通过客户端上的web浏览器或其他软件应用程序提供和访问服务,在一些实施例中,可以将终端用户302的供应和/或请求提供给入口网关330。入口网关330可以包括一个相应的代理来处理针对服务320(计算环境301中提供的一个或多个服务)的供应和/或请求。
55.仍然如图3所示,服务320是根据计算环境301支持的各种虚拟化技术来提供或部署的。在一些实施例中,可以根据基于虚拟机(virtual machine,vm)的虚拟化、基于容器的
虚拟化和/或类似的方式提供服务320。基于虚拟机的虚拟化可以是通过初始化虚拟机来模拟真实的计算机,在不直接接触任何实际硬件资源的情况下执行程序和应用程序。在虚拟机虚拟化机器的同时,根据基于容器的虚拟化,可以启动容器来虚拟化整个操作系统(operating system,os),以便多个工作负载可以在单个操作系统实例上运行。
56.在基于容器虚拟化的一个实施例中,服务320的若干容器可以被组装成一个pod(例如,kubernetes pod)。举例来说,如图3所示,服务320-2可以配备一个或多个pod 340-1,340-2,
…
,340-n(统称为pod 340)。每个pod 340可以包括代理345和一个或多个容器342-1,342-2,
…
,342-m(统称为容器342)。pod 340中一个或多个容器342处理与服务的一个或多个相应功能相关的请求,代理345通常控制与服务相关的网络功能,如路由、负载均衡等。其他服务320也可以类似于pod 340的pod。
57.在操作过程中,执行来自终端用户302的用户请求可能需要调用计算环境301中的一个或多个服务320,执行一个服务320的一个或多个功能可能需要调用另一个服务320的一个或多个功能。如图3所示,服务320-1(代表服务a)从入口网关330接收终端用户302的用户请求,服务320-1(代表服务a)可以调用服务320-2(代表服务d),服务320-2(代表服务d)可以请求服务320-3(代表服务e)执行一个或多个功能。
58.上述的计算环境可以是云计算环境,资源的分配由云服务提供上管理,允许功能的开发无需考虑实现、调整或扩展服务器。该计算环境允许开发人员在不构建或维护复杂基础设施的情况下执行响应事件的代码。服务可以被分割完成一组可以自动独立伸缩的功能,而不是扩展单个硬件设备来处理潜在的负载。
59.在上述运行环境下,本发明提供了如图4所示的一种识别音频数据声音来源的方法。图4是根据本发明实施例的一种识别音频数据声音来源的方法的流程图,如图4所示,该识别音频数据声音来源的方法包括:
60.步骤s41,接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份;
61.步骤s42,利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;
62.步骤s43,基于空间位置关系识别音频数据的声音来源。
63.上述预设虚拟空间可以是虚拟会议室对应的虚拟数字空间。本发明实施例中以虚拟会议室为例,在下文中对技术方案进行说明。
64.在本发明实施例中,上述第一虚拟形象可以是虚拟会议室中当前时刻的说话人对应的虚拟形象。上述多个第一虚拟形象可以是虚拟会议室中同时存在的多个说话人对应的多个虚拟形象。上述多个第一虚拟形象的音频数据可以是虚拟会议室中多个说话人发出的音频数据。上述多个第一虚拟形象的第一位置数据可以是该多个第一虚拟对象中每个虚拟对象在虚拟会议室中的空间坐标位置信息
65.在本发明实施例中,上述第二虚拟形象可以是虚拟会议室中当前时刻的收听人对应的虚拟形象。上述第二位置数据可以是上述第二虚拟对象在虚拟会议室中的空间坐标位置信息。
66.利用上述第一位置数据和上述第二位置数据,可以确定上述空间位置关系。该空
间位置关系可以是虚拟会议室中当前时刻的收听人对应的虚拟形象(相当于上述第二虚拟形象)与上述多个说话人中每个说话人对应的虚拟形象(相当于上述第一虚拟形象)之间的相对位置关系(如,包括方位、距离等)。
67.在本发明实施例中,基于上述空间位置关系,可以识别音频数据的声音来源。例如在虚拟会议室中,基于收听人对应的虚拟形象与多个说话人中每个说话人对应的虚拟形象之间的相对位置关系,可以识别音频数据中的哪个声音来源于多个说话人中的哪个说话人。
68.容易理解的是,本发明实施例提供的上述方法的重点在于:能够模仿人类双耳效应,在预设虚拟空间中实现音频空间来源识别,具体地,可以在虚拟会议室中帮助收听人快速识别当前说话人。
69.通过本发明实施例的上述步骤s41至步骤s43,接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份,通过利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系,进一步基于空间位置关系识别音频数据的声音来源。
70.容易注意到的是,通过本发明实施例,当预设虚拟空间内存在多个当前说话人时,通过多个当前说话人与收听人之间的相对位置关系,识别多个当前说话人的音频数据的声音来源,能够在预设虚拟空间内模拟人类的双耳效应确定说话人的方位,达到了在预设虚拟空间内根据多个说话人虚拟形象和收听人虚拟形象之间的相对位置关系识别多个说话人虚拟形象的音频数据的声音来源的目的,从而实现了在虚拟空间中出现多位说话人同时发言的情况下增强音频数据的辨识度、提高用户体验的技术效果,进而解决了虚拟空间中出现多位说话人同时发言的情况下音源混杂、用户体验差的技术问题。
71.下面对本发明实施例的上述方法进行进一步地介绍。
72.在一种可选的实施例中,在步骤s42中,利用第一位置数据和第二位置数据确定空间位置关系,包括如下方法步骤:
73.步骤s421,利用多个第一虚拟形象中每个第一虚拟形象在预设虚拟空间内的第一坐标位置与第二虚拟形象在预设虚拟空间内的第二坐标位置进行差值运算,得到空间位置关系,其中,空间位置关系包括:第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对方位关系,第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对距离关系。
74.在上述可选的实施例中,所进行的差值计算可以是空间向量差值计算。针对多个第一虚拟形象中每个第一虚拟形象在预设虚拟空间内的第一坐标位置与第二虚拟形象在预设虚拟空间内的第二坐标位置,确定空间向量,空间向量的长度可以用于表示在预设虚拟空间内第一虚拟形象中每个第一虚拟形象与第二虚拟形象之间的相对距离关系,空间向量的方向可以用于表示在预设虚拟空间内第一虚拟形象中每个第一虚拟形象与第二虚拟形象之间的相对方位关系,其中,空间向量的方向可以用该空间向量与通道朝向(如当前收听人的左声道方向或右声道方向)之间的夹角表示。
75.本发明实施例提供的上述识别音频数据声音来源的方法可以应用于电子商务服
务场景、教育培训场景、医疗卫生场景、科研学术场景下进行虚拟会议的情景中。以下以电子商务服务场景的虚拟会议室为例,对本发明实施例的技术方案进行具体的说明。
76.图5是根据本发明实施例的一种虚拟会议室的图形用户界面的示意图,如图5所示,在电子商务服务场景下的虚拟会议室m1中,可以包括:虚拟会议大厅、多个虚拟座位、多个与会人的虚拟形象(图5中显示有说话人a、说话人b和与会人c)等。本例中,与会人c为当前用户对应的虚拟人物,该与会人c的当前身份为收听人。
77.仍然如图5所示,在电子商务服务场景下,用于提供虚拟会议室m1的应用产品中,可以提供如下功能:“邀请加入大厅”功能(用于邀请当前未入会的人员加入当前虚拟会议室m1),“坐下”功能(用于控制当前用户对应的虚拟形象坐在指定的虚拟座位上),“静音”功能(用于关闭当前用户的话筒),“音量”功能(用于调节当前用户的扬声器或耳机的音量大小),“分享”功能(用于将当前用户的屏幕广播给虚拟会议室m1中的其他与会人),“设置”功能(用于支持当前用户为虚拟会议室m1调整系统偏好设置),“退出”功能(用于退出虚拟会议室m1)。
78.仍然如图5所示,在虚拟会议室m1中,说话人a位于与会人c的左侧,说话人b位于与会人c的右侧。
79.示例性地,在电子商务服务场景下的虚拟会议室m1中,为与会人c识别音频数据声音来源的过程可以包括:接收说话人a发送的位置坐标xa和音频数据sa,接收说话人b发送的位置坐标xb和音频数据sb。
80.需要说明的是,位置坐标xa为说话人a在虚拟会议室m1中的空间坐标,音频数据sa为说话人a发出的声音数据,位置坐标xb为说话人b在虚拟会议室m1中的空间坐标,音频数据sb为说话人b发出的声音数据。
81.在虚拟会议室m1中,与会人c所使用的当前设备可以给出该与会人c的位置坐标xc。
82.利用上述说话人a的位置坐标xa和与会人c的位置坐标xc,可以在虚拟会议室m1中确定说话人a与与会人c之间的空间位置关系;利用上述说话人b的位置坐标xb和与会人c的位置坐标xc,可以在虚拟会议室m1中确定说话人b与与会人c之间的空间位置关系。
83.需要说明的是,上述虚拟会议室m1可以是虚拟二维会议室或虚拟三维会议室。在虚拟二维会议室中,所有与会人(包括说话人和收听人)的空间坐标为二维坐标;在虚拟三维会议室中,所有与会人(包括说话人和收听人)的空间坐标为三维坐标。
84.在一种可选的实施例中,在步骤s43中,基于空间位置关系识别音频数据的声音来源,包括如下方法步骤:
85.步骤s431,利用空间位置关系确定音频数据在目标回放设备上每个声道分量对应的权重系数,其中,目标回放设备为第二虚拟形象关联的回放设备并且目标回放设备支持多声道的空间音频回放;
86.步骤s432,基于目标回放设备上每个声道分量对应的权重系数合成多声道空间音频;
87.步骤s433,通过多声道空间音频识别音频数据的声音来源。
88.在上述可选的实施例中,目标回放设备可以是当前身份为收听人的用户所采用的音频输出设备,该音频输出设备可以支持多声道的空间音频回放。利用第二虚拟形象与多
个第一虚拟形象中每个第一虚拟形象之间的相对方位关系和相对距离关系,可以确定多个第一虚拟形象的音频数据在上述目标回放设备上每个声道分量对应的权重系数。
89.上述权重系数可以用于表示多个第一虚拟形象中每个第一虚拟形象对应的音频数据在目标回放设备上每个声道上的信号强度。例如,某个第一虚拟形象在目标回放设备的左声道上权重系数越大,表示当前收听人在左声道中越能够清晰地听到该第一虚拟形象的声音(如音量更大)。
90.容易理解的是,通过基于目标回放设备上每个声道分量对应的权重系数合成多声道空间音频,以及通过多声道空间音频识别音频数据的声音来源,能够结合多个说话人在虚拟会议室中的空间位置关系,帮助当前收听人快速分别声音来源。
91.在一种可选的实施例中,在步骤s431中,利用空间位置关系确定音频数据在目标回放设备上每个声道分量对应的权重系数,包括如下方法步骤:
92.步骤s4311,利用空间位置关系确定目标长度与目标夹角,其中,目标长度为目标回放设备上每个声道分量对应的收听位置与多个第一虚拟形象中每个第一虚拟形象的第一坐标位置形成的目标向量的长度,目标夹角为目标向量对应的方向与目标回放设备上每个声道分量对应的方向之间的夹角;
93.步骤s4312,基于目标长度计算得到目标回放设备上每个声道分量对应的第一衰减系数,以及基于目标夹角计算得到目标回放设备上每个声道分量对应的第二衰减系数,其中,第一衰减系数为距离性衰减系数,第二衰减系数为指向性衰减系数;
94.步骤s4313,采用第一衰减系数和第二衰减系数计算得到目标回放设备上每个声道分量对应的权重系数。
95.在上述可选的实施例中,目标回放设备上每个声道分量对应的收听位置可以对应于当前收听人的多个收听位置,目标向量对应的方向可以对应于当前收听人的收听方向(如双耳朝向)。例如,左声道分量的收听位置可以对应于当前收听人的左耳位置,右声道分量的收听位置可以对应于当前收听人的右耳位置,左声道的收听方向可以对应于当前收听人的左耳朝向,右声道的收听方向可以对应于当前收听人的右耳朝向。该左耳位置、该右耳位置、该左耳朝向和该右耳朝向可以基于当前收听人的位置坐标利用预设规则进行计算,也可以利用当前收听人使用的其他智能设备(如智能穿戴设备:智能眼镜、智能手表、智能耳麦等,该智能设备与当前收听人使用的智能手机相关联)实时获取。
96.具体地例如,如果当前收听人佩戴有与智能手机相关联的智能耳机,该智能耳机安装有陀螺仪,通过该智能手机的摄像头对当前收听人进行动作捕捉,并利用光学识别算法得到当前收听人的面部朝向,基于该面部朝向利用该智能耳机实时获取当前收听人的双耳实时朝向(或者结合使用摄像头进行),并利用该实时朝向确定该当前收听人在虚拟会议室中的空间位置关系,进而计算衰减系数和声道权重等。比如当前收听人c的头部向左侧偏转至面向说话人a时,说话人a与收听人c之间的相对方位关系从“a位于c左侧”变换为“a位于c正前方”。由此,可以增加当前收听人的与会沉浸感。
97.仍然以在虚拟会议室m1中为与会人c识别音频数据声音来源为例对本发明的上述可选的实施例进行具体说明。
98.利用上述说话人a的位置坐标xa和与会人c的位置坐标xc,可以在虚拟会议室m1中确定空间向量空间向量的长度表示说话人a和与会人c之间的相对距离关系;由于说
话人a位于与会人c的左侧,空间向量与与会人c的左声道l方向之间的夹角表示说话人a和与会人c之间的相对方位关系。
99.同理,利用上述说话人b的位置坐标xb和与会人c的位置坐标xc,可以在虚拟会议室m1中确定空间向量空间向量的长度表示说话人b和与会人c之间的相对距离关系;由于说话人b位于与会人c的右侧,空间向量与与会人c的右声道r方向之间的夹角表示说话人b和与会人c之间的相对方位关系。
100.示例性地,在电子商务服务场景下的虚拟会议室m1中,为与会人c识别音频数据声音来源的过程可以包括:根据说话人a的位置坐标xa、说话人b的位置坐标xb与会人c的位置坐标xc,计算得到说话人a和说话人b在与会人c的左声道l和右声道r中信号振幅的权重。
101.需要说明的是,上述信号振幅的权重包括:说话人a在与会者c的左声道l中的信号权重w
la
,说话人a在与会者c的右声道r中的信号权重w
ra
,说话人b在与会者c的左声道l中的信号权重w
lb
,说话人b在与会者c的右声道r中的信号权重w
rb
。
102.图6是根据本发明实施例的一种信号权重计算方式的示意图,如图6所示,以说话人a在与会者c的左声道l中的信号权重w
la
为例,计算该信号权重w
la
的具体实现方式可以包括如下方法步骤:
103.步骤e51,根据预设人耳偏移模型(可以是由技术人员参考现实场景的双耳效应根据本发明提供的方法预先确定的),利用下述公式(1)计算在虚拟会议室m1中与会人c的左耳的收听位置c
l
:
104.c
l
=xc+(-1,0)
×rꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式(1)
105.在上述公式(1)中,xc为与会人c在虚拟会议室m1中的空间坐标,(-1,0)表示与会人c的左声道l的朝向,r表示预设常量;
106.步骤e52,基于与会人c的左耳的收听位置c
l
和说话人a的位置坐标xa,确定向量(从c
l
指向xa的向量)的长度d,以及确定向量与与会人c的左声道l的朝向之间的夹角θ;
107.步骤e53,根据现实场景中点声源在自由空间中的传播规律,采用预设反函数进行拟合,得到说话人a的音频数据sa在虚拟会议室m1的空间中的衰减系数a1(相当于上述第一衰减系数),本例中取a1=d-1
;
108.步骤e54,根据现实场景中人耳的指向性规律,采用预设心形函数进行拟合,得到说话人a的音频数据sa的指向性衰减系数a2(相当于上述第二衰减系数),本例中取
109.步骤e55,将衰减系数a1与指向性衰减系数a2相乘,得到说话人a在与会者c的左声道l中的信号权重w
la
=a1×
a2。
110.需要说明的是,上述步骤e53中采用的预设反函数和上述步骤e54中采用的预设心形函数仅为一种可能的示例,在具体应用场景中,可以根据场景需求采用其他可能的函数进行拟合和权重计算。
111.在一种可选的实施例中,在步骤s4312中,基于目标夹角计算得到目标回放设备上每个声道分量对应的第二衰减系数,包括如下方法步骤:
112.步骤s4314,对目标回放设备上每个声道分量对应的音频数据进行快速傅里叶变换,得到变换结果;
113.步骤s4315,基于变换结果,采用目标夹角计算得到目标回放设备上每个声道分量对应的第二衰减系数。
114.在上述可选的实施例中,在基于目标夹角计算得到目标回放设备上每个声道分量对应的朝向性衰减系数(相当于上述第二衰减系数)时,还可以将虚拟空间中不同声音来源引起的相位差、频谱影响等因素纳入考量,得到更加真实的空间音频效果。
115.仍然以在虚拟会议室m1中为与会人c识别音频数据声音来源为例对本发明的上述可选的实施例进行具体说明。
116.在计算说话人a在与会者c的左声道l中的信号权重w
la
时,上述步骤e54中,计算指向性衰减系数a2(相当于上述第二衰减系数)的过程中,由于人耳对于不同频域的收音指向性不同,可以先对音频数据sa进行快速傅里叶变换(fast fourier transform,fft),得到变化后的音频数据sa2,然后再基于音频数据sa2,通过计算得到对不同频点对应的不同的指向性衰减函数a2。
117.在一种可选的实施例中,在步骤s432中,基于目标回放设备上每个声道分量对应的权重系数合成多声道空间音频,包括如下方法步骤:
118.步骤s4321,基于目标回放设备上每个声道分量对应的权重系数以及每个声道分量对应的音频数据进行加权求和运算,得到多声道空间音频。
119.在上述可选的实施例中,所进行的加权求和计算可以是线性加权计算。
120.仍然以在虚拟会议室m1中为与会人c识别音频数据声音来源为例对本发明的上述可选的实施例进行具体说明。
121.示例性地,在电子商务服务场景下的虚拟会议室m1中,为与会人c识别音频数据声音来源的过程可以包括:计算得到说话人a和说话人b在与会人c的左声道l和右声道r中信号振幅的权重后,分别对左声道l和右声道r中的各个信号进行加权合成,得到与会人c的左声道l回放音频audio
l
和右声道r回放音频audior。
122.具体地,例如,在虚拟会议室m2中,存在同时发言的n名当前说话人,当前收听人收到的该n名当前说话人的音频数据记为s1,s2,...,sn;该n名当前说话人在当前收听人的左声道l中的信号权重记为w
l1
,w
l2
,...,w
ln
;该n名当前说话人在当前收听人的右声道r中的信号权重记为w
r1
,w
r2
,...,w
rn
。为当前收听人回放虚拟会议室m2的音频时,左声道l的回放音频右声道r的回放音频
123.图7是根据本发明实施例的一种虚拟会议室中音频多声道回放过程的示意图,如图7所示,在虚拟会议室中,通过话筒和网络接收说话人a和说话人b的语音波形和空间坐标;然后基于上述说话人a和说话人b的空间坐标,对说话人a、说话人b和与会人c进行空间还原,得到说话人a对与会人c的权重a(例如可以包括w
la
=0.8和w
ra
=0.2)和说话人b对与会人c的权重b(例如可以包括w
lb
=0.3和w
rb
=0.7);进一步地,基于说话人a和说话人b的语音波形、权重a和权重b进行加权合成,得到当前收听人的多声道回放音频;在当前收听人关联的支持多声道的扬声器或耳机中播放多声道回放音频。
124.容易理解的是,在上述虚拟会议室m1中,说话人a位于与会人c的左侧,因此,说话
人a在与会人c的左声道l上具有较高的权重,也就是说w
la
>w
lb
,与会人c在左声道l上主要收听来自说话人a的声音;同理,说话人b位于与会人c的右侧,因此,说话人b在与会人c的右声道r上具有较高的权重,也就是说w
rb
>w
ra
,与会人c在右声道r上主要收听来自说话人b的声音。
125.图8是根据本发明实施例的一种音频数据双声道回放方式的示意图,如图8所示,与会人c在左声道l上主要收听来自说话人a的声音,在右声道r上主要收听来自说话人b的声音。
126.容易注意到的是,通过本发明实施例提供的上述方法,能够使虚拟会议室m1中的与会人c更容易地分辨出“左侧”的声音(也即,左声道l中主要收听的声音)来自于说话人a,“右侧”的声音(也即,右声道r中主要收听的声音)来自于说话人b,并且,当说话人a和说话人b同时发言时,与会人c也可以通过左右声道的声音区分该说话人a和说话人b的声音,消除了现有技术中虚拟会议室中声音混杂的问题。
127.容易注意到的是,在传统的线下会议中,当同时存在多个说话人时,会议收听人可以通过双耳效应区分不同来源的声音,并通过大脑将注意力集中在感兴趣的声音来源上(过滤或者忽略其他声音来源)。在本发明实施例中,能够通过虚拟会议室场景中虚拟形象(可以是说话人或者收听人)之间的空间相对关系,增强音频数据的辨识度,也就是说,可以模仿人类的双耳效应,判断音频数据的声音来源于哪位说话人,从而结果虚拟会议室场景下同时存在多个说话人时声音混杂的问题,提升虚拟会议室的与会者的与会体验。
128.在一种可选的实施例中,识别音频数据声音来源的方法还包括如下方法步骤:
129.步骤s44,获取音频数据在目标回放设备上不同声道分量之间的相位差,其中,相位差用于辅助判别多个第一虚拟形象中每个第一虚拟形象的方位;
130.步骤s45,在目标回放设备上每个声道分量对应的时域上插入相位差。
131.在上述可选的实施例中,由于人的双耳收听位置不同,在将音频数据进行多声道回放时,还可以考虑该音频数据在目标回放设备上不同声道分量之间的相位差,从而提升多声道回放音频的质量,提高用户的收听体验。
132.仍然以在虚拟会议室m1中为与会人c识别音频数据声音来源为例对本发明的上述可选的实施例进行具体说明。将说话人a与与会人c之间的距离记为d
ac
,说话人b与与会人c之间的距离记为d
bc
。由于通常情况下d
ac
与d
bc
并不相等,可以在为与会人c回放多声道空间音频数据时,考虑相位差
133.具体地,假设d
ac
>d
bc
,根据下述公式(2)计算相位差
[0134][0135]
在上述公式(2)中,f表示声音的频率(可以由技术人员预先设定),v表示声音传播的速度(可以由技术人员预先设定)。
[0136]
在为与会人c回放多声道空间音频数据时,在相位落后通道的音频中加上上述相位差说话人a位于与会人c的左侧,则对说话人a的音频数据sa来说,与会人c的右声道r为相位落后通道,在合成右声道r的回放音频audior时,将说话人a的音频数据sa的相位向后偏移同理,说话人b位于与会人c的右侧,则对说话人b的音频数据sb来说,与会人c的左声道l为相位落后通道,在合成左声道l的回放音频budio
l
时,将说话人b的音频数据sb的
相位向后偏移由此,可以使所合成的多声道回放音频具有更加真实的效果,提升用户的与会体验。
[0137]
在一种可选的实施例中,通过终端设备提供一图形用户界面,图形用户界面所显示的内容至少部分地包含一虚拟空间场景,识别音频数据声音来源的方法还包括如下方法步骤:
[0138]
步骤s461,响应作用于图形用户界面的第一触控操作,将多个第一虚拟形象添加至预设虚拟空间;
[0139]
步骤s462,响应作用于图形用户界面的第二触控操作,启用第二虚拟形象对应的虚拟扬声器控件;
[0140]
步骤s463,通过虚拟扬声器控件对应的目标回放设备对多个第一虚拟形象的音频数据进行空间音频回放,以识别音频数据的声音来源。
[0141]
在上述可选的实施例中,图形用户界面内可以显示有一虚拟空间场景。
[0142]
在上述可选的实施例中,用户可以对图形用户界面进行第一触控操作。用户可以触控该图形用户界面中的“邀请新成员”按钮或加号按钮等,或者在预设的触控区域内执行指定的第一触控手势,以实现如下过程:将多个第一虚拟形象添加至预设虚拟空间,该多个第一虚拟形象为多个与会人(可以是说话人也可以是收听人)在预设虚拟空间中对应的虚拟形象。
[0143]
在上述可选的实施例中,用户可以对图形用户界面进行第一触控操作。用户可以触控该图形用户界面中的“开启麦克风”按钮或话筒按钮等,或者在预设的触控区域内执行指定的第二触控手势,以实现如下过程:启用第二虚拟形象对应的虚拟扬声器控件。该第二虚拟形象可以是预设虚拟空间中当前身份为说话人的虚拟形象,启用该第二虚拟形象对应的虚拟扬声器控件后,可以将该第二虚拟形象对应的说话人发出的声音广播给预设虚拟空间中的其他与会人。
[0144]
在响应上述第二触控操作,启用第二虚拟形象对应的虚拟扬声器控件后,可以通过本发明实施例提供的上述识别音频数据声音来源的方法,通过虚拟扬声器控件对应的目标回放设备对多个第一虚拟形象的音频数据进行空间音频回放,以帮助当前收听人识别音频数据的声音来源。
[0145]
特别地,上述第一触控操作和上述第二触控操作均可以是用户用手指接触上述终端设备的显示屏并触控该终端设备的操作。该触控操作可以包括单点触控、多点触控,其中,每个触控点的触控操作可以包括点击、长按、重按、划动等。上述第一触控操作和上述第二触控操作还可以是通过鼠标、键盘等输入设备实现的触控操作。
[0146]
在上述运行环境下,本发明提供了如图9所示的一种识别音频数据声音来源的方法。图9是根据本发明实施例的另一种识别音频数据声音来源的方法的流程图,如图9所示,该识别音频数据声音来源的方法,包括:
[0147]
步骤s91,接收来自于虚拟会议室内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为会议发言者身份;
[0148]
步骤s92,利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为会议收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关
系;
[0149]
步骤s93,基于空间位置关系识别音频数据在虚拟会议室内的声音来源。
[0150]
在本发明实施例中,上述第一虚拟形象可以是虚拟会议室中当前时刻的会议发言者对应的虚拟形象。上述多个第一虚拟形象可以是虚拟会议室中同时存在的多个会议发言者对应的多个虚拟形象。上述多个第一虚拟形象的音频数据可以是虚拟会议室中多个会议发言者发出的音频数据。上述多个第一虚拟形象的第一位置数据可以是该多个第一虚拟对象中每个虚拟对象在虚拟会议室中的空间坐标位置信息
[0151]
在本发明实施例中,上述第二虚拟形象可以是虚拟会议室中当前时刻的会议收听者对应的虚拟形象。上述第二位置数据可以是上述第二虚拟对象在虚拟会议室中的空间坐标位置信息。
[0152]
利用上述第一位置数据和上述第二位置数据,可以确定上述空间位置关系。该空间位置关系可以是虚拟会议室中当前时刻的会议收听者对应的虚拟形象(相当于上述第二虚拟形象)与上述多个会议发言者中每个会议发言者对应的虚拟形象(相当于上述第一虚拟形象)之间的相对位置关系(如,包括方位、距离等)。
[0153]
在本发明实施例中,基于上述空间位置关系,可以识别音频数据的在虚拟会议室内的声音来源。在虚拟会议室中,基于会议收听者对应的虚拟形象与多个会议发言者中每个会议发言者对应的虚拟形象之间的相对位置关系,可以识别音频数据中的哪个声音来源于多个会议发言者中的哪个会议发言者。
[0154]
容易理解的是,本发明实施例提供的上述方法的重点在于:能够模仿人类双耳效应,在虚拟会议室中实现音频空间来源识别,具体地,可以在虚拟会议室中帮助会议收听者快速识别当前会议发言者。
[0155]
通过本发明实施例的上述步骤s91至步骤s93,接收来自于虚拟会议室内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为会议发言者身份,通过利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为会议收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系,进一步基于空间位置关系识别音频数据的在虚拟会议室内的声音来源。
[0156]
容易注意到的是,通过本发明实施例,当虚拟会议室内存在多个当前会议发言者时,通过多个当前会议发言者与会议收听者之间的相对位置关系,识别多个当前会议发言者的音频数据的在虚拟会议室内的声音来源,能够在虚拟会议室内模拟人类的双耳效应确定会议发言者的方位,达到了在虚拟会议室内根据多个会议发言者虚拟形象和会议收听者虚拟形象之间的相对位置关系识别多个会议发言者虚拟形象的音频数据的在虚拟会议室内的声音来源的目的,从而实现了在虚拟空间中出现多位会议发言者同时发言的情况下增强音频数据的辨识度、提高用户体验的技术效果,进而解决了虚拟空间中出现多位说话人同时发言的情况下音源混杂、用户体验差的技术问题。
[0157]
相关技术提供的传统会议室产品中,通常使用与会人的画面进行布局调整或者高亮显示的方式标识当前说话人。然而,对于虚拟会议室的复杂场景(存在多个说话人同时发言)来说,相关技术中标识当前说话人的方法无法解决声音混杂的问题,使得虚拟会议室中的与会者的与会体验较差。
[0158]
与相关技术相比,本发明实施例提供的方法能够在预设虚拟空间中模仿人类的双耳效应,并通过多声道回放设备,将预设虚拟空间中当前说话人的位置信息提供给收听人,以便收听人能够更容易地在预设虚拟空间中识别当前说话人。此外,本发明实施例提供的上述方法还能够减轻预设虚拟空间中多来源音频的混杂问题,在同等网络条件下能够提升预设虚拟空间中音频数据的辨识度。总的来说,本发明实施例提供的上述方法可以应用于远程会议、虚拟会议等相关产品中,有利于提升整体的会议音频质量,增强与会人的与会体验(如增加会议沉浸感)。
[0159]
在一种可选的实施例中,通过终端设备提供一图形用户界面,图形用户界面所显示的内容至少部分地包含一虚拟会议室场景,识别音频数据声音来源的方法还包括如下方法步骤:
[0160]
步骤s94,响应作用于图形用户界面的第一触控操作,将多个第一虚拟形象添加至虚拟会议室;
[0161]
步骤s95,响应作用于图形用户界面的第二触控操作,启用第二虚拟形象对应的虚拟扬声器控件;
[0162]
步骤s96,通过虚拟扬声器控件对应的目标回放设备对多个第一虚拟形象的音频数据进行空间音频回放,以识别音频数据在虚拟会议室内的声音来源。
[0163]
在上述可选的实施例中,图形用户界面内可以显示有一虚拟会议室场景。
[0164]
在上述可选的实施例中,用户可以对图形用户界面进行第一触控操作。用户可以触控该图形用户界面中的“邀请新成员”按钮或加号按钮等,或者在预设的触控区域内执行指定的第一触控手势,以实现如下过程:将多个第一虚拟形象添加至虚拟会议室,该多个第一虚拟形象为多个与会人(可以是说话人也可以是收听人)在虚拟会议室中对应的虚拟形象。
[0165]
在上述可选的实施例中,用户可以对图形用户界面进行第一触控操作。用户可以触控该图形用户界面中的“开启麦克风”按钮或话筒按钮等,或者在预设的触控区域内执行指定的第二触控手势,以实现如下过程:启用第二虚拟形象对应的虚拟扬声器控件。该第二虚拟形象可以是虚拟会议室中当前身份为说话人的虚拟形象,启用该第二虚拟形象对应的虚拟扬声器控件后,可以将该第二虚拟形象对应的说话人发出的声音广播给虚拟会议室中的其他与会人。
[0166]
在响应上述第二触控操作,启用第二虚拟形象对应的虚拟扬声器控件后,可以通过本发明实施例提供的上述识别音频数据声音来源的方法,通过虚拟扬声器控件对应的目标回放设备对多个第一虚拟形象的音频数据进行空间音频回放,以识别音频数据在虚拟会议室内的声音来源。
[0167]
特别地,上述第一触控操作和上述第二触控操作均可以是用户用手指接触上述终端设备的显示屏并触控该终端设备的操作。该触控操作可以包括单点触控、多点触控,其中,每个触控点的触控操作可以包括点击、长按、重按、划动等。上述第一触控操作和上述第二触控操作还可以是通过鼠标、键盘等输入设备实现的触控操作。
[0168]
在上述运行环境下,本发明提供了如图10所示的一种识别音频数据声音来源的方法。图10是根据本发明实施例的另一种识别音频数据声音来源的方法的流程图,如图10所示,该识别音频数据声音来源的方法,包括:
[0169]
步骤s1001,接收来自于虚拟课堂内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为课堂发言者身份;
[0170]
步骤s1002,利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为课堂收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;
[0171]
步骤s1003,基于空间位置关系识别音频数据在虚拟课堂内的声音来源。
[0172]
在本发明实施例中,上述第一虚拟形象可以是虚拟课堂中当前时刻的课堂发言者对应的虚拟形象。上述多个第一虚拟形象可以是虚拟课堂中同时存在的多个课堂发言者对应的多个虚拟形象。上述多个第一虚拟形象的音频数据可以是虚拟课堂中多个课堂发言者发出的音频数据。上述多个第一虚拟形象的第一位置数据可以是该多个第一虚拟对象中每个虚拟对象在虚拟课堂中的空间坐标位置信息
[0173]
在本发明实施例中,上述第二虚拟形象可以是虚拟课堂中当前时刻的课堂收听者对应的虚拟形象。上述第二位置数据可以是上述第二虚拟对象在虚拟课堂中的空间坐标位置信息。
[0174]
利用上述第一位置数据和上述第二位置数据,可以确定上述空间位置关系。该空间位置关系可以是虚拟课堂中当前时刻的课堂收听者对应的虚拟形象(相当于上述第二虚拟形象)与上述多个课堂发言者中每个课堂发言者对应的虚拟形象(相当于上述第一虚拟形象)之间的相对位置关系(如,包括方位、距离等)。
[0175]
在本发明实施例中,基于上述空间位置关系,可以识别音频数据的在虚拟课堂内的声音来源。在虚拟课堂中,基于课堂收听者对应的虚拟形象与多个课堂发言者中每个课堂发言者对应的虚拟形象之间的相对位置关系,可以识别音频数据中的哪个声音来源于多个课堂发言者中的哪个课堂发言者。
[0176]
容易理解的是,本发明实施例提供的上述方法的重点在于:能够模仿人类双耳效应,在虚拟课堂中实现音频空间来源识别,具体地,可以在虚拟课堂中帮助课堂收听者快速识别当前课堂发言者。
[0177]
通过本发明实施例的上述步骤s1001至步骤s1003,接收来自于虚拟课堂内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为课堂发言者身份,通过利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为课堂收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系,进一步基于空间位置关系识别音频数据的在虚拟课堂内的声音来源。
[0178]
容易注意到的是,通过本发明实施例,当虚拟课堂内存在多个当前课堂发言者时,通过多个当前课堂发言者与课堂收听者之间的相对位置关系,识别多个当前课堂发言者的音频数据的在虚拟课堂内的声音来源,能够在虚拟课堂内模拟人类的双耳效应确定课堂发言者的方位,达到了在虚拟课堂内根据多个课堂发言者虚拟形象和课堂收听者虚拟形象之间的相对位置关系识别多个课堂发言者虚拟形象的音频数据的在虚拟课堂内的声音来源的目的,从而实现了在虚拟空间中出现多位课堂发言者同时发言的情况下增强音频数据的辨识度、提高用户体验的技术效果,进而解决了虚拟空间中出现多位说话人同时发言的情
况下音源混杂、用户体验差的技术问题。
[0179]
需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明并不受所描述的动作顺序的限制,因为依据本发明,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本发明所必须的。
[0180]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到根据上述实施例的方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
[0181]
实施例2
[0182]
根据本发明实施例,还提供了一种用于实施上述识别音频数据声音来源的方法的装置实施例,图11是根据本发明实施例的一种识别音频数据声音来源的装置的结构示意图,如图11所示,该装置包括:接收模块1101、确定模块1102和识别模块1103,其中,
[0183]
接收模块1101,用于接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份;
[0184]
确定模块1102,用于利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;
[0185]
识别模块1103,用于基于空间位置关系识别音频数据的声音来源。
[0186]
可选地,上述确定模块1102还用于:利用多个第一虚拟形象中每个第一虚拟形象在预设虚拟空间内的第一坐标位置与第二虚拟形象在预设虚拟空间内的第二坐标位置进行差值运算,得到空间位置关系,其中,空间位置关系包括:第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对方位关系,第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对距离关系。
[0187]
可选地,上述识别模块1103还用于:利用空间位置关系确定音频数据在目标回放设备上每个声道分量对应的权重系数,其中,目标回放设备为第二虚拟形象关联的回放设备并且目标回放设备支持多声道的空间音频回放;基于目标回放设备上每个声道分量对应的权重系数合成多声道空间音频;通过多声道空间音频识别音频数据的声音来源。
[0188]
可选地,上述识别模块1103还用于:利用空间位置关系确定目标长度与目标夹角,其中,目标长度为目标回放设备上每个声道分量对应的收听位置与多个第一虚拟形象中每个第一虚拟形象的第一坐标位置形成的目标向量的长度,目标夹角为目标向量对应的方向与目标回放设备上每个声道分量对应的方向之间的夹角;基于目标长度计算得到目标回放设备上每个声道分量对应的第一衰减系数,以及基于目标夹角计算得到目标回放设备上每个声道分量对应的第二衰减系数,其中,第一衰减系数为距离性衰减系数,第二衰减系数为指向性衰减系数;采用第一衰减系数和第二衰减系数计算得到目标回放设备上每个声道分
量对应的权重系数。
[0189]
可选地,上述识别模块1103还用于:对目标回放设备上每个声道分量对应的音频数据进行快速傅里叶变换,得到变换结果;基于变换结果,采用目标夹角计算得到目标回放设备上每个声道分量对应的第二衰减系数。
[0190]
可选地,上述识别模块1103还用于:基于目标回放设备上每个声道分量对应的权重系数以及每个声道分量对应的音频数据进行加权求和运算,得到多声道空间音频。
[0191]
可选地,图12是根据本发明实施例的一种可选的识别音频数据声音来源的装置的结构示意图,如图12所示,该装置除包括图11所示的所有模块外,还包括:插入模块1104,用于获取音频数据在目标回放设备上不同声道分量之间的相位差,其中,相位差用于辅助判别多个第一虚拟形象中每个第一虚拟形象的方位;在目标回放设备上每个声道分量对应的时域上插入相位差。
[0192]
可选地,图13是根据本发明实施例的另一种可选的识别音频数据声音来源的装置的结构示意图,如图13所示,该装置除包括图12所示的所有模块外,还包括:显示模块1105,用于:响应作用于图形用户界面的第一触控操作,将多个第一虚拟形象添加至预设虚拟空间;响应作用于图形用户界面的第二触控操作,启用第二虚拟形象对应的虚拟扬声器控件;通过虚拟扬声器控件对应的目标回放设备对多个第一虚拟形象的音频数据进行空间音频回放,以识别音频数据的声音来源。
[0193]
此处需要说明的是,上述接收模块1101、确定模块1102和识别模块1103对应于实施例1中的步骤s41至步骤s43,三个模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为装置的一部分可以运行在实施例一提供的计算机终端10中。
[0194]
在本发明实施例中,接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份,通过利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系,进一步基于空间位置关系识别音频数据的声音来源。
[0195]
容易注意到的是,通过本发明实施例,当预设虚拟空间内存在多个当前说话人时,通过多个当前说话人与收听人之间的相对位置关系,识别多个当前说话人的音频数据的声音来源,能够在预设虚拟空间内模拟人类的双耳效应确定说话人的方位,达到了在预设虚拟空间内根据多个说话人虚拟形象和收听人虚拟形象之间的相对位置关系识别多个说话人虚拟形象的音频数据的声音来源的目的,从而实现了在虚拟空间中出现多位说话人同时发言的情况下增强音频数据的辨识度、提高用户体验的技术效果,进而解决了虚拟空间中出现多位说话人同时发言的情况下音源混杂、用户体验差的技术问题。
[0196]
根据本发明实施例,还提供了一种用于实施上述另一种识别音频数据声音来源的方法的装置实施例,图14是根据本发明实施例的另一种识别音频数据声音来源的装置的结构示意图,如图14所示,该装置包括:接收模块1401、确定模块1402和识别模块1403,其中,
[0197]
接收模块1401,用于接收来自于虚拟会议室内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为会议发言者身份;
[0198]
确定模块1402,用于利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为会议收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;
[0199]
识别模块1403,用于基于空间位置关系识别音频数据在虚拟会议室内的声音来源。
[0200]
可选地,图15是根据本发明实施例的另一种可选的识别音频数据声音来源的装置的结构示意图,如图15所示,该装置除包括图14所示的所有模块外,还包括:显示模块1404,用于响应作用于图形用户界面的第一触控操作,将多个第一虚拟形象添加至虚拟会议室;响应作用于图形用户界面的第二触控操作,启用第二虚拟形象对应的虚拟扬声器控件;通过虚拟扬声器控件对应的目标回放设备对多个第一虚拟形象的音频数据进行空间音频回放,以识别音频数据在虚拟会议室内的声音来源。
[0201]
此处需要说明的是,上述接收模块1401、确定模块1402和识别模块1403对应于实施例1中的步骤s91至步骤s93,三个模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为装置的一部分可以运行在实施例一提供的计算机终端10中。
[0202]
在本发明实施例中,接收来自于虚拟会议室内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为会议发言者身份,通过利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为会议收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系,进一步基于空间位置关系识别音频数据的在虚拟会议室内的声音来源。
[0203]
容易注意到的是,通过本发明实施例,当虚拟会议室内存在多个当前会议发言者时,通过多个当前会议发言者与会议收听者之间的相对位置关系,识别多个当前会议发言者的音频数据的在虚拟会议室内的声音来源,能够在虚拟会议室内模拟人类的双耳效应确定会议发言者的方位,达到了在虚拟会议室内根据多个会议发言者虚拟形象和会议收听者虚拟形象之间的相对位置关系识别多个会议发言者虚拟形象的音频数据的在虚拟会议室内的声音来源的目的,从而实现了在虚拟空间中出现多位会议发言者同时发言的情况下增强音频数据的辨识度、提高用户体验的技术效果,进而解决了虚拟空间中出现多位说话人同时发言的情况下音源混杂、用户体验差的技术问题。
[0204]
根据本发明实施例,还提供了一种用于实施上述又一种识别音频数据声音来源的方法的装置实施例,图16是根据本发明实施例的又一种识别音频数据声音来源的装置的结构示意图,如图16所示,该装置包括:接收模块1601、确定模块1602和识别模块1603,其中,
[0205]
接收模块1601,用于接收来自于虚拟课堂内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为课堂发言者身份;
[0206]
确定模块1602,用于利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为课堂收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;
[0207]
识别模块1603,用于基于空间位置关系识别音频数据在虚拟课堂内的声音来源。
[0208]
此处需要说明的是,上述接收模块1601、确定模块1602和识别模块1603对应于实施例1中的步骤s1001至步骤s1003,三个模块与对应的步骤所实现的实例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为装置的一部分可以运行在实施例一提供的计算机终端10中。
[0209]
接收来自于虚拟课堂内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为课堂发言者身份,通过利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为课堂收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系,进一步基于空间位置关系识别音频数据的在虚拟课堂内的声音来源。
[0210]
容易注意到的是,通过本发明实施例,当虚拟课堂内存在多个当前课堂发言者时,通过多个当前课堂发言者与课堂收听者之间的相对位置关系,识别多个当前课堂发言者的音频数据的在虚拟课堂内的声音来源,能够在虚拟课堂内模拟人类的双耳效应确定课堂发言者的方位,达到了在虚拟课堂内根据多个课堂发言者虚拟形象和课堂收听者虚拟形象之间的相对位置关系识别多个课堂发言者虚拟形象的音频数据的在虚拟课堂内的声音来源的目的,从而实现了在虚拟空间中出现多位课堂发言者同时发言的情况下增强音频数据的辨识度、提高用户体验的技术效果,进而解决了虚拟空间中出现多位说话人同时发言的情况下音源混杂、用户体验差的技术问题。
[0211]
需要说明的是,本实施例的优选实施方式可以参见实施例1中的相关描述,此处不再赘述。
[0212]
实施例3
[0213]
根据本发明实施例,还提供了一种电子设备的实施例,该电子设备可以是计算设备群中的任意一个计算设备。该电子设备包括:处理器和存储器,其中:
[0214]
存储器,与上述处理器连接,用于为上述处理器提供处理以下处理步骤的指令:接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据的声音来源。
[0215]
在本发明实施例中,接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份,通过利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系,进一步基于空间位置关系识别音频数据的声音来源。
[0216]
容易注意到的是,通过本发明实施例,当预设虚拟空间内存在多个当前说话人时,通过多个当前说话人与收听人之间的相对位置关系,识别多个当前说话人的音频数据的声音来源,能够在预设虚拟空间内模拟人类的双耳效应确定说话人的方位,达到了在预设虚
拟空间内根据多个说话人虚拟形象和收听人虚拟形象之间的相对位置关系识别多个说话人虚拟形象的音频数据的声音来源的目的,从而实现了在虚拟空间中出现多位说话人同时发言的情况下增强音频数据的辨识度、提高用户体验的技术效果,进而解决了虚拟空间中出现多位说话人同时发言的情况下音源混杂、用户体验差的技术问题。
[0217]
需要说明的是,本实施例的优选实施方式可以参见实施例1中的相关描述,此处不再赘述。
[0218]
实施例4
[0219]
本发明的实施例可以提供一种计算机终端,该计算机终端可以是计算机终端群中的任意一个计算机终端设备。可选地,在本实施例中,上述计算机终端也可以替换为移动终端等终端设备。
[0220]
可选地,在本实施例中,上述计算机终端可以位于计算机网络的多个网络设备中的至少一个网络设备。
[0221]
在本实施例中,上述计算机终端可以执行识别音频数据声音来源的方法中以下步骤的程序代码:接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据的声音来源。
[0222]
可选地,图17是根据本发明实施例的另一种计算机终端的结构框图,如图17所示,该计算机终端可以包括:一个或多个(图中仅示出一个)处理器122、存储器124、以及外设接口126。
[0223]
其中,存储器可用于存储软件程序以及模块,如本发明实施例中的识别音频数据声音来源的方法和装置对应的程序指令/模块,处理器通过运行存储在存储器内的软件程序以及模块,从而执行各种功能应用以及数据处理,即实现上述的识别音频数据声音来源的方法。存储器可包括高速随机存储器,还可以包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器可进一步包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至计算机终端。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
[0224]
处理器可以通过传输装置调用存储器存储的信息及应用程序,以执行下述步骤:接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据的声音来源。
[0225]
可选地,上述处理器还可以执行如下步骤的程序代码:利用多个第一虚拟形象中每个第一虚拟形象在预设虚拟空间内的第一坐标位置与第二虚拟形象在预设虚拟空间内的第二坐标位置进行差值运算,得到空间位置关系,其中,空间位置关系包括:第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对方位关系,第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对距离关系。
[0226]
可选地,上述处理器还可以执行如下步骤的程序代码:利用空间位置关系确定音频数据在目标回放设备上每个声道分量对应的权重系数,其中,目标回放设备为第二虚拟形象关联的回放设备并且目标回放设备支持多声道的空间音频回放;基于目标回放设备上每个声道分量对应的权重系数合成多声道空间音频;通过多声道空间音频识别音频数据的声音来源。
[0227]
可选地,上述处理器还可以执行如下步骤的程序代码:利用空间位置关系确定目标长度与目标夹角,其中,目标长度为目标回放设备上每个声道分量对应的收听位置与多个第一虚拟形象中每个第一虚拟形象的第一坐标位置形成的目标向量的长度,目标夹角为目标向量对应的方向与目标回放设备上每个声道分量对应的方向之间的夹角;基于目标长度计算得到目标回放设备上每个声道分量对应的第一衰减系数,以及基于目标夹角计算得到目标回放设备上每个声道分量对应的第二衰减系数,其中,第一衰减系数为距离性衰减系数,第二衰减系数为指向性衰减系数;采用第一衰减系数和第二衰减系数计算得到目标回放设备上每个声道分量对应的权重系数。
[0228]
可选地,上述处理器还可以执行如下步骤的程序代码:对目标回放设备上每个声道分量对应的音频数据进行快速傅里叶变换,得到变换结果;基于变换结果,采用目标夹角计算得到目标回放设备上每个声道分量对应的第二衰减系数。
[0229]
可选地,上述处理器还可以执行如下步骤的程序代码:基于目标回放设备上每个声道分量对应的权重系数以及每个声道分量对应的音频数据进行加权求和运算,得到多声道空间音频。
[0230]
可选地,上述处理器还可以执行如下步骤的程序代码:获取音频数据在目标回放设备上不同声道分量之间的相位差,其中,相位差用于辅助判别多个第一虚拟形象中每个第一虚拟形象的方位;在目标回放设备上每个声道分量对应的时域上插入相位差。
[0231]
可选地,上述处理器还可以执行如下步骤的程序代码:响应作用于图形用户界面的第一触控操作,将多个第一虚拟形象添加至预设虚拟空间;响应作用于图形用户界面的第二触控操作,启用第二虚拟形象对应的虚拟扬声器控件;通过虚拟扬声器控件对应的目标回放设备对多个第一虚拟形象的音频数据进行空间音频回放,以识别音频数据的声音来源。
[0232]
处理器可以通过传输装置调用存储器存储的信息及应用程序,以执行下述步骤:接收来自于虚拟会议室内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为会议发言者身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为会议收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据在虚拟会议室内的声音来源。
[0233]
可选地,上述处理器还可以执行如下步骤的程序代码:响应作用于图形用户界面的第一触控操作,将多个第一虚拟形象添加至虚拟会议室;响应作用于图形用户界面的第二触控操作,启用第二虚拟形象对应的虚拟扬声器控件;通过虚拟扬声器控件对应的目标回放设备对多个第一虚拟形象的音频数据进行空间音频回放,以识别音频数据在虚拟会议室内的声音来源。
[0234]
处理器可以通过传输装置调用存储器存储的信息及应用程序,以执行下述步骤:
接收来自于虚拟课堂内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为课堂发言者身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为课堂收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据在虚拟课堂内的声音来源。
[0235]
在本发明实施例中,接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份,通过利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系,进一步基于空间位置关系识别音频数据的声音来源。
[0236]
容易注意到的是,通过本发明实施例,当预设虚拟空间内存在多个当前说话人时,通过多个当前说话人与收听人之间的相对位置关系,识别多个当前说话人的音频数据的声音来源,能够在预设虚拟空间内模拟人类的双耳效应确定说话人的方位,达到了在预设虚拟空间内根据多个说话人虚拟形象和收听人虚拟形象之间的相对位置关系识别多个说话人虚拟形象的音频数据的声音来源的目的,从而实现了在虚拟空间中出现多位说话人同时发言的情况下增强音频数据的辨识度、提高用户体验的技术效果,进而解决了虚拟空间中出现多位说话人同时发言的情况下音源混杂、用户体验差的技术问题。
[0237]
本领域普通技术人员可以理解,图17所示的结构仅为示意,计算机终端也可以是智能手机(如android手机、ios手机等)、平板电脑、掌声电脑以及移动互联网设备(mobile internet devices,mid)、pad等终端设备。图17其并不对上述电子装置的结构造成限定。例如,计算机终端还可包括比图17中所示更多或者更少的组件(如网络接口、显示装置等),或者具有与图17所示不同的配置。
[0238]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令终端设备相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:闪存盘、只读存储器(read-only memory,rom)、随机存取器(random access memory,ram)、磁盘或光盘等。
[0239]
根据本发明实施例,还提供了一种计算机可读存储介质的实施例。可选地,在本实施例中,上述计算机可读存储介质可以用于保存上述实施例1所提供的识别音频数据声音来源的方法所执行的程序代码。
[0240]
可选地,在本实施例中,上述计算机可读存储介质可以位于计算机网络中计算机终端群中的任意一个计算机终端中,或者位于移动终端群中的任意一个移动终端中。
[0241]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据的声音来源。
[0242]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的
程序代码:接收来自于预设虚拟空间内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为说话人身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为收听人身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据的声音来源。
[0243]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:利用多个第一虚拟形象中每个第一虚拟形象在预设虚拟空间内的第一坐标位置与第二虚拟形象在预设虚拟空间内的第二坐标位置进行差值运算,得到空间位置关系,其中,空间位置关系包括:第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对方位关系,第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对距离关系。
[0244]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:利用空间位置关系确定音频数据在目标回放设备上每个声道分量对应的权重系数,其中,目标回放设备为第二虚拟形象关联的回放设备并且目标回放设备支持多声道的空间音频回放;基于目标回放设备上每个声道分量对应的权重系数合成多声道空间音频;通过多声道空间音频识别音频数据的声音来源。
[0245]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:利用空间位置关系确定目标长度与目标夹角,其中,目标长度为目标回放设备上每个声道分量对应的收听位置与多个第一虚拟形象中每个第一虚拟形象的第一坐标位置形成的目标向量的长度,目标夹角为目标向量对应的方向与目标回放设备上每个声道分量对应的方向之间的夹角;基于目标长度计算得到目标回放设备上每个声道分量对应的第一衰减系数,以及基于目标夹角计算得到目标回放设备上每个声道分量对应的第二衰减系数,其中,第一衰减系数为距离性衰减系数,第二衰减系数为指向性衰减系数;采用第一衰减系数和第二衰减系数计算得到目标回放设备上每个声道分量对应的权重系数。
[0246]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:对目标回放设备上每个声道分量对应的音频数据进行快速傅里叶变换,得到变换结果;基于变换结果,采用目标夹角计算得到目标回放设备上每个声道分量对应的第二衰减系数。
[0247]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:基于目标回放设备上每个声道分量对应的权重系数以及每个声道分量对应的音频数据进行加权求和运算,得到多声道空间音频。
[0248]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:获取音频数据在目标回放设备上不同声道分量之间的相位差,其中,相位差用于辅助判别多个第一虚拟形象中每个第一虚拟形象的方位;在目标回放设备上每个声道分量对应的时域上插入相位差。
[0249]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:响应作用于图形用户界面的第一触控操作,将多个第一虚拟形象添加至预设虚拟空间;响应作用于图形用户界面的第二触控操作,启用第二虚拟形象对应的虚拟扬声器控件;通过虚拟扬声器控件对应的目标回放设备对多个第一虚拟形象的音频数据进行空间
音频回放,以识别音频数据的声音来源。
[0250]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:接收来自于虚拟会议室内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为会议发言者身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为会议收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据在虚拟会议室内的声音来源。
[0251]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:响应作用于图形用户界面的第一触控操作,将多个第一虚拟形象添加至虚拟会议室;响应作用于图形用户界面的第二触控操作,启用第二虚拟形象对应的虚拟扬声器控件;通过虚拟扬声器控件对应的目标回放设备对多个第一虚拟形象的音频数据进行空间音频回放,以识别音频数据在虚拟会议室内的声音来源。
[0252]
可选地,在本实施例中,计算机可读存储介质被设置为存储用于执行以下步骤的程序代码:接收来自于虚拟课堂内多个第一虚拟形象的音频数据和第一位置数据,其中,多个第一虚拟形象的当前身份为课堂发言者身份;利用第一位置数据和第二位置数据确定空间位置关系,其中,第二位置数据为第二虚拟形象的位置数据,第二虚拟形象的当前身份为课堂收听者身份,空间位置关系用于确定第二虚拟形象与多个第一虚拟形象中每个第一虚拟形象之间的相对位置关系;基于空间位置关系识别音频数据在虚拟课堂内的声音来源。
[0253]
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
[0254]
在本发明的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
[0255]
在本发明所提供的几个实施例中,应该理解到,所揭露的技术内容,可通过其它的方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模块的间接耦合或通信连接,可以是电性或其它的形式。
[0256]
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0257]
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0258]
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机
设备(可为个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
[0259]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1