一种能量采集认知物联网络抗干扰最优传输方法
1.本发明属于无线通信领域,具体涉及一种能量采集认知物联网络抗干扰最优传输方法。
背景技术:
2.随着信息技术和机器对机器(m2m)通信的最新进步,前所未有的物理对象正在连接到互联网。这导致了一种智能连接网络中分散对象和物联网(物联网)的实现。交通、医疗保健、工业自动化和灾难响应只是物联网如何显著改善我们的生活的几个例子。然而,越来越多的物联网对象可能会产生大量的数据,因为它们交换信息以保持连接和访问服务,这增加了对频谱资源的需求。如果采用静态频谱分配策略,可能会出现频谱稀缺的问题。认知无线电网络(crns)是解决这一问题的宝贵工具。根据周围的射频(rf)环境,crn通过学习、推理和决定有效地利用无线电频谱进行可靠和不间断的无线通信来适应外部条件。随着crn和物联网的不断发展,一种名为认知物联网(ciot)的强大范式被提出,物联网对象将具有认知能力,通过理解社会和物理世界中的决策来学习、思考和行动。因此,基于cr的物联网可能成为未来的必要要求。
3.大多数物联网设备主要通过无线通信技术进行互联,由电池供电,并位于分散的位置。电池容量有限所造成的能源问题是制约物联网发展的一个主要问题。能源收获(eh)可以从各种绿色能源中获取能源,如光、热、风和射频源,延长了能源限制网络的使用寿命。因此,这是下一代网络的关键技术。近年来,随着物联网的发展,从环境射频信号中获取能量引起了人们的广泛关注,因为它使低功率通信网络成为能源可持续的。将认知无线电技术与射频能量采集技术和物联网相结合,可以解决物联网设备爆炸性增长造成的频谱短缺和电池容量限制造成的能源短缺问题。
4.为了实现ciot网络的目标,保护网络免受各种恶意攻击是物联网系统发展的研究热点。cr网络由于其独特的特点,比其他无线电网络更容易受到安全威胁。cr网络攻击包括主用户仿真(pue)、目标函数攻击、学习攻击、频谱感知数据证伪、窃听和干扰。其中,干扰攻击被认为是最频繁和最具有威胁性的攻击,因为它们会导致连续传输的吞吐量下降、网络瘫痪或通信中断。物联网网络由于其异质性,也容易受到各种干扰攻击。
技术实现要素:
5.本发明的目的在于克服现有技术缺陷,提供一种能量采集认知物联网络抗干扰最优传输方法。
6.为实现上述目的,本发明的技术方案是:一种能量采集认知物联网络抗干扰最优传输方法,通过将认知无线电技术、能量采集技术、抗干扰技术在通信领域相结合,对认知通信网络各个节点在发送、接收信号被恶意攻击的情况下,认知基站无需先验知识,无模型的学习恶意节点信道攻击策略,制定对抗策略并调节各个节点的信道接入、模式选择和功率分配以达到系统吞吐量最大化目的;该方法具体步骤如下:
7.步骤1、搭建强化学习环境,考虑一个以认知基站cbs为圆心半径为1km的范围,n个ciot节点位于圆内且服从泊松分布,ciot节点拥有相同的初始功率p(t0)={p1(t0)=p0,...,pn(t0)=p0}和电池水平b(t0)={b1(t0)=b0,...,bn(t0)=b0},空闲信道数量为l;在此范围内考虑一个恶意攻击节点,它也服从泊松分布,也有初始功率pj(t0)=p
j0
;cbs为agent使用强化学习算法与环境进行交互;
8.步骤2、构建基于深度强化学习的认知通信网络抗干扰资源分配算法,首先生成认知通信网络的拓扑结构,初始化训练轮次数episode,每轮训练次数steps,actor的学习率lr_a,critic的学习率lr_c,奖励折扣率γ,经验回放池d的最大容量c,训练批次大小batch_size以及神经网络权重参数:策略网络actor的online权重θ
μ
和actor的target权重θ
μ
′
,q网络critic的online权重θq和actor的target权重θq′
;
9.步骤3、在每个episode的开始,更新认知通信网络环境中所有ciot节点和攻击节点的位置和并重新计算所有链路的信道增益,包括ciot节点与cbs的信道增益和恶意攻击节点与ciot节点的信道增益更新频谱感知得到的信道状态i(t)={i1(t),...,i
l
(t)},信道状态为繁忙或空闲;更新后的ciot节点电池状态b(t)={b1(t),...,bn(t)};得到状态空间作为每个episode的开始的初始状态;
10.步骤4、在每个episode的第t个step,cbs将带入ddpg算法得到动作将动作与环境交互,在τ时间内ciot节点根据更新每个节点的工作模式mi(t),选择频谱接入或能量采集,之后在(1-τ)的时间内通过能量采集公式更新每个ciot节点获取的能量ei(t),或者在(1-τ)的时间内按照功率pi(t)接入空闲信道进行数据传输;在(1-τ)时间结束后更新每个ciot节点电池状态bi(t+1);cbs在每个t时隙最后根据下式计算ciot节点总的吞吐量即强化学习的奖励r:
[0011][0012]
其中t为每个时隙的时长,w为带宽,sinri(t)为第i个ciot节点的信噪比;在得到奖励r后,对于长期的系统性能,即累积吞吐量,不仅应该考虑当前时间段t上的瞬时奖励r,还应该考虑未来的奖励;因此,从第t个时间段开始的折现未来累积吞吐量表示如下:
[0013][0014]
其中,折扣率0<γ<1;
[0015]
将累计吞吐量最大化,表述为:
[0016][0017]
s.t.in
p
(t)≤il(t)
[0018]
[0019][0020]
其中,表示期望的给定值,g(t)表示从第t个时隙开始的折现未来累积吞吐量,in
p
(t)表示第t个时间段上功率分配策略集合中大于零的元素数,il(t)表示第t个时间段处的空闲通道数,t为每个时隙的周期,τ为每个时隙中控制阶段的持续时间,pi(t)表示第t个时隙处ciot节点i的发射功率,es表示为信号交换所需的能量,g
ib
(t)表示ciot节点i与cbs之间的信道增益,n表示高斯白噪声n~n(0,ω2),sinr
threshold
表示信干噪比阈值;
[0021]
步骤5、cbs将动作每带入环境后,环境会返回相应的奖励r和下一状态cbs将这个状态转换过程存入经验回放池r,作为训练online网络的数据集;之后从经验回放池r中,随机采样batch_size个已存放数据作为online策略网络、online q网络的一个mini-batch训练数据;用(si,ai,ri,s
i+1
)表示batch_size中的单个transition数据;接下来进行ddpg算法神经网络的更新:
[0022]
1)计算online q网络的gradient:
[0023]
q网络的loss定义:使用类似于监督式学习的方法,定义loss为均方误差mse:
[0024][0025]
其中yi其中为状态值函数:
[0026]
yi=ri+γq
′
(s
i+1
,μ
′
(s
i+1
|θ
μ
′
)|θq′
)
[0027]
基于标准的反向传播方法,求得l针对θq的gradient:
[0028]
2)更新online q网络:采用adam optimizer;
[0029]
3)计算online策略网络的policy gradient:
[0030]
采用off-policy的训练方法,policy gradient公式如下:
[0031][0032]
policy gradient是在s根据p
β
分布时的期望值,用monte-carlo方法来估算这个期望值,在经验回放池中存储的(si,ai,ri,s
i+1
)是基于cbs的行为策略β产生的,它们的分布函数(pdf)为p
β
,所以当从经验回放池中随机采样获得batch_size数据时,根据monte-carlo方法,将数据代入上述policy gradient公式,作为对上述期望值的一个无偏估计,policy gradient改写为:
[0033][0034]
4)更新online策略网络:采用adam optimizer;
[0035]
5)软更新target策略网络和target q网络,通过让target网络的权重缓慢地跟踪学习到的online网络来进行更新:
[0036][0037]
其中,ξ∈(0,1]表示基于ddpg的算法中target网络的更新速率。
[0038]
相较于现有技术,本发明具有以下有益效果:首先将多个次级用户在干扰者攻击下的最优传输问题表述为一个没有任何先验知识的马尔可夫决策过程(mdp),然后提出了一种基于深度强化学习(drl)的深度确定性策略梯度(ddpg)算法来进行干扰策略学习、动态频谱接入、工作模式选择和连续功率分配,使长期上行吞吐量最大化。通过在随机和扫描干扰攻击环境下的仿真,证明了所提出的算法可以有效地减少来自恶意干扰者的不利影响,即使他们使用不同的攻击策略。仿真结果表明提出的算法与dqn算法、贪婪和随机算法相比都具有更好的性能。
附图说明
[0039]
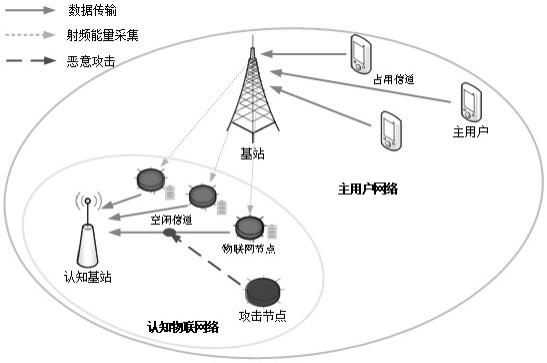
图1为本发明实施例中认知物联网络的系统模型;
[0040]
图2为本发明实施例中系统的时隙模型;
[0041]
图3为本发明实施例中强化学习框架;
[0042]
图4为本发明实施例中ddpg算法框架;
[0043]
图5为本发明实施例中不同算法在无恶意攻击情况下的系统性能;
[0044]
图6为本发明实施例中不同算法在随机攻击策略下的系统性能;
[0045]
图7为本发明实施例中不同算法在扫描攻击策略下的系统性能。
具体实施方式
[0046]
下面结合附图,对本发明的技术方案进行具体说明。
[0047]
考虑一种具有射频能量采集能力的多用户认知物联网模型,它由三部分组成。第一部分是由m个主用户(pu)和一个基站(bs)组成的主用户网络(pun)。第二部分是由一个认知基站(cbs)和n个ciot节点组成的认知物联网络(ciotn)。第三部分由一个恶意攻击节点(man)组成。系统模型如图1所示,具体方案如下:
[0048]
在该系统中,pun覆盖k个正交通道,ciotn位于pun的覆盖区域内。所有设备都在同步时隙模式下工作,pu在每个时隙中使用授权的频谱信道与bs进行通信。在ciotn中,cbs在整个认知物联网络中起核心作用,cbs定期感知许可频谱的状态,为ciot节点的上行传输寻找空闲信道并进行信道分配,在恶意攻击环境下,cbs还需要对攻击进行甄别并采取反制措施。cbs决定进行频谱感知,那么在感知阶段,它通过使用能量检测方法来感知信道状态。感知结果记为θ:θ=0和θ=1分别表示cbs感知信道为繁忙和空闲。信道的实际状态为c:c=0和c=1分别表示实际信道状态为繁忙和空闲。频谱感知具有误警概率p
fa
=pr{θ=0∣c=1}和漏检概率pm=pr{θ=1∣c=0},此外,还有正确检测到pu活动的概率pd=1-pm和频谱访问机会的概率po=1-p
fa
。
[0049]
我们考虑系统共有l个信道,根据感知结果我们得到了l个信道的信道状态向量i(t)={i1(t),...,ii(t),...,i
l
(t)},ii(t)∈{0,1},i∈1,..,l,并更新信道信任值
[0050]
感知结果为θ=1的概率为:
[0051][0052]
信道信任值更新为:
[0053][0054]
感知结果为θ=0的概率为
[0055]
信道信任值更新为:
[0056][0057]
确认了空闲信道,我们会获得信道功率增益g
xy
:
[0058][0059]
对于信道模型,同时考虑了大尺度路径损耗衰减和小尺度瑞利衰落。h
xy
表示瑞利衰落信道增益,表示大尺度路径损耗衰减,d
xy
表示x与y之间的距离,d0表示参考距离,α表示路径损失指数,x表示发射机(n个ciot节点、cbs和恶意攻击节点都是发射机),y表示接收机(n个ciot节点和cbs都是接收机)。
[0060]
每个ciot节点均可以利用射频能量采集装置从其他ciot节点和干扰节点的信号中获取能量,每个ciot节点只在接收到cbs的控制指令后选择进行频谱接入、能量采集或数据传输。il(t)表示第t个时隙的空闲信道数,其中il(t)≤l。ciot节点和cbs以同步的时隙方式运行。pi(t)表示第t个时隙上ciot节点i的发射功率。因此,在第t个时隙上,所有ciot节点的功率分配策略集合表示为p(t)={pi(t),i=1,2,...,n},其中p(t)中大于零的元素数记为inp(t)。如果pi(t)》0,则选择相应的节点ciot节点i在访问模式下工作,以使用分配的功率pi(t)进行数据传输。否则,如果pi(t)=0,则表示对应的节点ciot节点i在采集模式下工作。因此,in(t),被选择访问空闲通道的ciot节点的数量,应该等于inp(t)。ciot节点i在第t个时间槽的工作模式mi(t)可以描述为:
[0061][0062]
因此,第t个时间段的所有节点的工作模式集可以表示为m(t)={mi(t),i=1,...,n}。
[0063]
在我们考虑的系统中,cbs有足够的电网供电,恶意攻击节点也设置为有源供电,而ciot节点则由从周围环境中获得的射频能量供电。这意味着每个ciot节点都可以从其他活动的辅助节点的传输信号中获取能量。如附图2所示,ciot节点的通信操作以时隙结构的形式依次连续进行,时隙包括两部分:控制阶段和操作阶段(工作阶段)。在控制阶段,ciot节点接收来自cbs发送的控制信号,即频谱接入、工作模式和连续功率控制信号。在操作阶段,ciot节点根据控制阶段获得的控制指令,或进行频谱接入并数据传输,或进行射频能量采集。
[0064]
基于上述说明,单个ciot节点i在第t个时隙的采集射频能量可以描述为:
[0065][0066]
其中,η表示能量转换率,t为每个时隙的周期,τ为每个时隙中控制阶段的持续时间,其中包括信令交换和策略广播的时间,pj(t)表示恶意攻击节点在第t个时隙上的功率,pk(t)表示ciot节点k在第t个时隙上的功率,g
ji
(t)表示恶意攻击节点与ciot节点i之间的信道增益,g
ki
(t)表示ciot节点k与ciot节点i之间的信道增益。第t个时隙上所有ciot节点收获的能量的集合记为e(t)={ei(t),i=1,...,n}。
[0067]
电池容量标记为b
max
,所有ciot节点的电池容量都一样。所有节点的当前电池状态集合记为b(t)={bi(t),i=1,...,n}。由于能量收集过程和能量转换也需要时间,在当前时隙中收集的能量被存储在电池中,并将在未来的时隙中使用。可充电电池被认为是理想的,因为在能量储存或回收过程中没有能量损失。一旦电池满了,额外收集的能量就被放弃了。所收集的能量被认为仅用于信令交换和数据传输。信号交换所需的能量表示为es,它是一个常数。ciot节点i在不同时隙上的电池演化可以表示为:
[0068]bi
(t+1)=min{b
max
,bi(t)+ei(t)-(t-τ)mi(t)pi(t)-zi(t)es}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0069][0070]
其中,zi(t)表示电池容量必须大于控制信号交换所需的能量,不然强制执行能量采集。
[0071]
man采用随机、扫描两种不同方式的干扰攻击对ciot节点的信道进行攻击,扫描攻击我们认为是有固定进攻策略的,攻击的策略只与上一时刻的攻击状态有关,所以恶意攻击被描述是符合马尔可夫决策过程(mdp)。我们假设一个功率有限的干扰模型,在每个时隙中,man可以在m个通道上以最大功率p
max
的发射干扰信号。man在其时间平均功率上也有一个约束p
avg
,其中p
avg
<p
max
。在每个时隙中,man可以从m+1个离散功率水平{p
j0
,p
j1
,...,p
jm
}中进行选择,我们假设man在所有的m个通道上发出相同的功率水平。我们将表示为一个攻击概率向量。在每个时隙中,当发射机在目标信道上主动传输数据时,如果满足平均功率约束,干扰器可以以功率p
ji
攻击该信道。最终,接收器接收到的信号干扰噪声比(sinr)为:
[0072][0073]
其中,fi(t)=fj(t)表示发射机所选的信道被恶意节点攻击,fi(t)≠fj(t)表示发射机所选的信道未被恶意节点攻击,n表示高斯白噪声。
[0074]
传输策略优化方法。本发明的目标是最大化ciot节点的吞吐量,根据吞吐量公式,吞吐量与传输功率成正比,而传输功率与传输时间成反比,无论功率如何变化,传输时间和吞吐量都是此消彼长的关系,因此,我们需要合理的控制ciot节点选择合适的功率值才能
平衡二者对ciot节点吞吐量的影响。
[0075]
由上所述,我们的目的是解决一个组合优化的问题,随着机器学习的不断成熟,强化学习算法开始被提出用来解决频谱资源分配问题。强化学习是指智能系统以试错的方式来获得系统从环境信息到行动的映射,以使得系统行动能从环境中获得最大的累积效用。对于认知物联网络来说,强化学习状态是利用外部环境状态的学习及对先前状态的一些报酬累积,去判断并执行下一个策略行为,而这些报酬的积累是用来表示先前外部环境的影响,必须通过每一次策略行为后进行及时更新。本发明中,长期吞吐量最大化被定义为马尔可夫决策过程(mdp)的一个框架,如附图3。随后,提出了深度确定性的策略梯度算法(ddpg)的调度方案,以实现mdp问题的最优策略。ddpg是为了解决连续动作控制问题而提出的算法。以前学习的q-learning算法、sarsa算法以及dqn算法针对的动作空间都是离散的,ddpg就是对dqn算法的扩展,主要就是让dqn能够解决连续动作控制的问题而提出的。经过多次迭代后,系统在面对不同的状态时,可以自行做出最优的动作。本文在单用户的使用场景下,将马尔科夫决策过程中的各类参数设置如下:
[0076]
agent:cbs;
[0077]
状态空间s:信道状态、ciot节点的功率状态和电池水平;
[0078]
动作空间a:频谱感知策略、动态接入调度、工作模式选择和功率分配策略;
[0079]
奖励函数r:n个时隙内ciot节点总吞吐量的期望值。
[0080]
如图1至图3所示,本实例提供了一种基于深度强化学习的能量采集认知物联网络抗干扰最优传输方案,具体包括以下步骤:
[0081]
步骤1、首先搭建强化学习环境(environment),考虑一个以认知基站(cbs)为圆心半径为1km的范围,n个ciot节点位于圆内且服从泊松分布,ciot节点拥有相同的初始功率p(t0)={p1(t0)=p0,...,pn(t0)=p0}和电池水平b(t0)={b1(t0)=b0,...,bn(t0)=b0},空闲信道数量为l。在此范围内考虑一个恶意攻击节点,它也服从泊松分布,也有初始功率pj(t0)=p
j0
。cbs为agent使用强化学习算法与环境进行交互。
[0082]
步骤2、构建基于深度强化学习的认知通信网络抗干扰资源分配算法,首先生成通信网络的拓扑结构,初始化训练轮次数episode,每轮训练次数steps,actor的学习率lr_a,critic的学习率lr_c,奖励折扣率γ,经验回放池d的最大容量c,训练批次大小batch_size以及神经网络权重参数:策略网络actor的online权重θ
μ
和actor的target权重θ
μ
′
,q网络critic的online权重θq和actor的target权重θq′
,见图4。
[0083]
步骤3、在每个episode的开始,更新认知通信网络环境中所有ciot节点和攻击节点的位置和并重新计算所有链路的信道增益,包括ciot节点与cbs的信道增益和恶意攻击节点与ciot节点的信道增益更新频谱感知得到的信道状态(繁忙或空闲)i(t)={i1(t),...,i
l
(t)};更新后的ciot节点电池状态b(t)={b1(t),...,bn(t)}。将这三个组合为状态空间作为每个episode的开始的初始状态。
[0084]
步骤4、在每个episode的第t个step,cbs将带入ddpg算法得到动作将动作与环境交互,在τ时间内ciot节点根据更新每个节点的工作模式mi(t),选择频谱接入或能量采集,之后在(1-τ)的时间内通过能量采集公
carlo方法来估算这个期望值,在经验回放池中存储的(si,ai,ri,s
i+1
),是基于cbs的行为策略β产生的,它们的分布函数(pdf)为p
β
,所以当我们从经验回放池中随机采样获得batch_size数据时,根据monte-carlo方法,将数据代入上述policy gradient公式,可以作为对上述期望值的一个无偏估计,所以policy gradient可以改写为:
[0106][0107]
4)更新online策略网络:采用adam optimizer。
[0108]
5)软更新target策略网络和target q网络,通过让这些target网络的权重缓慢地跟踪学习到的online网络来进行更新:
[0109][0110]
其中,ξ∈(0,1]表示基于ddpg的算法中target网络的更新速率。
[0111]
为了展示本方法的效果,我们将研究该算法在吞吐量方面的性能,我们比较了几种传统的传输策略算法,分别是:
[0112]
1.随机传输策略,它随机选择ciot节点来访问空闲通道,并从中为这些节点选择功率。
[0113]
2.贪婪的传输策略,它选择ciot节点访问具有最大信噪比的信道,选择消耗所有剩余能量以最大限度地提高即时吞吐量,而不考虑长期吞吐量。
[0114]
3.dqn传输策略,使用传统的dqn算法对ciot节点进行离散功率分配,其中分配的传输功率从预处理的离散功率集中选择:
[0115][0116]
如图5所示,在信道数量为10,频谱空闲概率为50%的环境中,受物联网设备的限制,设ciot节点的最大发射功率为100mw,电池最大容量5j,控制信号交换所消耗功率为固定值es=10mw,带宽为1mhz,加性高斯白噪声功率谱密度为-170dbm/hz,时隙周期t为1s,控制时长τ=0.2s,能量转换率η=0.8,信噪比阈值sinr
threshold
=10db。训练轮次数episodes为500,每轮训练次数steps为100,结果表明,在无恶意攻击下的环境里,ddpg算法所获得的平均吞吐量比其他算法的都要高出许多。随机算法由于不考虑信道状态和信道增益也不考虑ciot节点的电池状态,只是随机的分配功率给随机的信道,故而平均吞吐量最低;e-greedy算法考虑信道状态,对感知到的空闲信道贪婪的分配最大的功率且不考虑电池状态,故而也只有较低的平均吞吐量;dqn算法即考虑信道状态也考虑ciot节点的电池状态,但是只有固定的离散功率进行分配;我们的ddpg算法在dqn的基础上考虑了连续的功率变化,因此获得了最高的平均吞吐量,比dqn高了40%,是e-greedy算法的两倍。
[0117]
如图6所示,其他前置条件相同的情况下,加入了恶意攻击节点,节点以random攻击方式,在每个时隙随机选择m=3个信道进行攻击,最大干扰功率为200mw。结果表明random与e-greedy算法由于不考虑信道状态和电池状态,干扰对其的影响有限,但仍然保
持一个低水平的平均吞吐量;dqn和ddpg在random攻击干扰下,平均吞吐量较无攻击情况下有明显下降,但仍远高于random与e-greedy算法,这是由于随机干扰攻击的策略不确定性造成的,算法难以学习到随机策略。
[0118]
如图7所示,其他前置条件相同的情况下,加入了恶意攻击节点,节点以扫描(scan)攻击方式,在每个时隙按照固定的扫描策略,对m=3个信道进行攻击,在最大干扰功率为200mw。结果表明干扰对random与e-greedy算法的影响依旧有限且吞吐量保持一个低水平;dqn受扫描干扰影响最重,固定的功率分配使其无法应对扫描干扰的侵害,吞吐量只比e-greedy算法略高;ddpg由于使用连续的功率分配,且使用策略网络actor和q网络critic相互学习,更新网络权重,因此可以更好的学习到扫描干扰的策略,并制定策略,在被干扰的信道进行能量采集,在未被干扰的信道进行信道接入,因而获得了最高的平均吞吐量。
[0119]
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1