一种防止HTTP的GET请求被劫持的方法与流程
一种防止http的get请求被劫持的方法
技术领域
1.本发明涉及互联网技术领域,更具体的说是涉及一种防止http的get请求被劫持的方法。
背景技术:
2.当用户在浏览器输入网站域名,发送了http的get请求后,由于http的get请求为明文方式,网络链路中的路由器会首先收到此次http的get请求,之后路由器的旁路设备标记此tcp连接为http协议,之后可以抢在网站服务器返回数据之前发送http协议的302代码进行下载文件的劫持,浏览器收到302代码后就会跳转到错误的文件下载地址下载软件了,随后网站服务器的真正数据到达后反而会被丢弃。或者,旁路设备在标记此tcp连接为http协议后,直接返回修改后的html代码,导致浏览器中被插入了广告或恶意代码,随后网站服务器的真正数据到达后最终也是被丢弃。
3.目前虽然可以采用https方式进行加密防止劫持,但是多数用户在浏览器输入网址时,只输入域名,并没有输入https://,这样导致浏览器依然使用http方式访问,导致网站依然被劫持。
4.因此,如何提供一种能够防止http的get请求被劫持的方法是本领域技术人员亟需解决的技术问题。
技术实现要素:
5.有鉴于此,本发明提供了一种防止http的get请求被劫持的方法,流量中无get请求的实现,是在tcp连接建立完成后,网站服务器主动给浏览器发送网页报文,然后浏览器根据返回的内容进行跳转,进而实现反劫持。
6.为了实现上述目的,本发明采用如下技术方案:
7.一种防止http的get请求被劫持的方法,包括以下步骤:
8.在用户浏览器中输入http请求,向网站web服务器发起tcp请求;
9.网站web服务器收到tcp请求后,与用户浏览器进行三次握手,并向用户浏览器返回js代码;
10.用户浏览器执行js代码,通过js代码获取当前用户访问的至少一个参数;
11.用户浏览器将该至少一个参数以https的方式传递给网站web服务器;
12.网站web服务器根据获得的至少一个参数判断用户访问的地址需求,并返回用户所需的网页结果。
13.进一步的,网站web服务器与用户浏览器进行三次握手的过程包括:
14.用户浏览器发送一个syn标志位置1的tcp包,同时选择一个初始序列号seq=x,用户浏览器进入同步已发送状态;
15.网站web服务器收到请求报文后,如果同意连接,则发出确认报文;确认报文中ack=1,syn=1,确认号ack=x+1,同时为自己初始化一个序列号seq=y,此时,网站web服务器
进入到同步收到状态;
16.用户浏览器收到确认报文后,向网站web服务器再次发出确认报文,发出的确认报文的ack=1,确认号ack=y+1,自己的序列号seq=x+1,此时,用户浏览器与网站web服务器间的连接建立,用户浏览器进入已建立连接状态。
17.进一步的,js代码获取的当前用户访问的至少一个参数包括:用户输入的域名。
18.进一步的,js代码获取的当前用户访问的至少一个参数还包括:用户输入的路径/文件名以及用户输入的其他参数。
19.进一步的,通过js代码window.location.host获取用户输入的域名,通过js代码window.location.pathname获取用户输入的路径/文件名,通过js代码window.location.search获取用户输入的其他参数。
20.经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种防止http的get请求被劫持的方法,用户浏览器与网站web服务器建立连接后,用户浏览器不主动发起get请求,而是网站web服务器主动返回js代码,通过js代码获取用户要访问的完整地址并进行跳转访问,由于流量中无get请求,因此劫持服务器读取不到get请求的内容,所以无法被劫持,进而解决了直接输入域名被劫持的问题。
附图说明
21.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
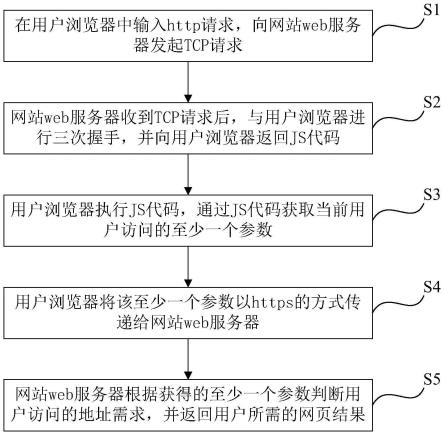
22.图1为本发明提供的防止http的get请求被劫持的方法的流程图。
具体实施方式
23.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
24.如图1所示,本发明实施例公开了一种防止http的get请求被劫持的方法,包括以下步骤:
25.s1、在用户浏览器中输入http请求,向网站web服务器发起tcp请求;
26.s2、网站web服务器收到tcp请求后,与用户浏览器进行三次握手,并向用户浏览器返回js代码;
27.s3、用户浏览器执行js代码,通过js代码获取当前用户访问的至少一个参数;
28.s4、用户浏览器将该至少一个参数以https的方式传递给网站web服务器;https是在http上建立ssl加密层,并对传输数据进行加密,是http协议的安全版,本身就可以防止被劫持。
29.s5、网站web服务器根据获得的至少一个参数判断用户访问的地址需求,并返回用户所需的网页结果。
30.由于目前进行http访问时,用户浏览器与web服务器建立连接之后,用户浏览器主动发起get请求,请求http头中的host字段带有需要访问的网址信息,劫持服务器获取到http请求后,根据get请求中的host判断应该劫持到什么样的网站,
31.劫持服务器在正常的web服务器之前返回,指定的网页内容,导致原网页在返回后失效,所以用户实际返回的是劫持服务器返回的内容。
32.本发明实施例中,用户浏览器与web服务器建立连接之后,用户浏览器不发起get请求,劫持服务器获取不到get请求的内容,网站web服务器主动返回js代码,通过js代码获取用户要访问的完整地址并进行跳转访问,由于流量中无get请求,因此劫持服务器读取不到get请求的内容,所以无法被劫持,进而解决了直接输入域名被劫持的问题
33.在一个具体实施例中,网站web服务器与用户浏览器进行三次握手的过程包括:
34.用户浏览器发送一个syn标志位置1的tcp包,同时选择一个初始序列号seq=x,用户浏览器进入同步已发送状态;
35.网站web服务器收到请求报文后,如果同意连接,则发出确认报文;确认报文中ack=1,syn=1,确认号ack=x+1,同时为自己初始化一个序列号seq=y,此时,网站web服务器进入到同步收到状态;
36.用户浏览器收到确认报文后,向网站web服务器再次发出确认报文,发出的确认报文的ack=1,确认号ack=y+1,自己的序列号seq=x+1,此时,用户浏览器与网站web服务器间的连接建立,用户浏览器进入已建立连接状态。
37.在一个实施例中,js代码获取的当前用户访问的至少一个参数包括:用户输入的域名、用户输入的路径/文件名以及用户输入的其他参数。
38.其中,通过js代码window.location.host获取用户输入的域名,通过js代码window.location.pathname获取用户输入的路径/文件名,通过js代码window.location.search获取用户输入的其他参数。
39.本发明实施例中,通过js代码window.location.hostname获取到用户输入的域名,通过window.location.pathname获取到用户输入的路径或文件名(如果有),通过window.location.search获取到用户输入的参数(如果有)。将https://字符与上述三者进行拼合得到用户的要访问的完整网址,然后通过js代码window.location.href进行跳转访问,实现https方式访问域名,最终解决直接输入域名被劫持的问题。
40.本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
41.对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1