一种基于URL多角度特征的钓鱼网站检测方法
一种基于url多角度特征的钓鱼网站检测方法
技术领域
1.本发明涉及一种基于url多角度特征的钓鱼网站检测方法,属于信息安全技术领域。
背景技术:
2.网络钓鱼是一种利用社会工程和技术手段的网络攻击。犯罪分子通常会伪装成合法实体,诱骗用户的信任,并通过电子邮件或社交网络向用户发送消息,欺骗、施压、操纵用户泄露个人隐私数据(如银行账户、信用卡号、登陆凭证等)或下载恶意软件。
3.大多数反钓鱼工具通常使用基于列表的方法来提高检测效率。例如,google safe browsing建立了一个包含恶意软件和网络钓鱼的url列表,谷歌和火狐等许多浏览器都订阅了此项服务,来检查恶意链接。mcafee siteadvisor可以作为浏览器插件被用户访问,向用户显示网站的安全评级。此外,ebay toolbar、egress defend、netcraft toolbar、zonealarm和许多其他工具也被广泛用于钓鱼网站检测。基于列表的方法简单而有效,但需要频繁更新和维护,并且很难应对零日钓鱼攻击。
4.钓鱼攻击日益严峻,科研人员试图从网页中提取更有效的特征来检测钓鱼网站。基于视觉相似性的方法通过比较logo、图片、截图等视觉特征的相似程度来检测钓鱼网站,此类方法模型复杂,计算复杂度大且时间成本高。基于内容的方法通过提取网页特征来检测钓鱼攻击,特征来源包括url、网页源代码、whois信息、网页排名等,检测类型包括url分析、图片分析、文本分析、邮件分析、拼写和语法检查、dns检查等。基于视觉相似性和内容的方法(例如已有专利“一种基于多特征融合的钓鱼网站检测方法cn201810373630.1”,“钓鱼网站攻击检测方法、装置、电子设备及存储介质cn202210553089.9”)需要等待页面加载,严重影响钓鱼检测的实时性。
5.从url提取特征检测钓鱼网站,这可以检测零日钓鱼攻击,同时具有较高的实时性。已有专利“一种基于深度学习的钓鱼网站url检测方法cn201810750707.2”和“一种面向url的钓鱼网站检测方法cn202011361704.3”,都是通过神经网络(例如cnn和lstm)从url提取特征进行分类。基于深度学习的钓鱼url检测虽然可以避免特征工程,但其模型复杂度大,训练成本高,所需时间长,占用较多的计算资源,不易在资源受限的设备上使用。在基于机器学习的方法中,已有专利“基于机器学习的钓鱼网站url检测方法及系统cn202110231656.4”缺乏对url各组件的分析;“一种基于url字符串随机率特征提取的钓鱼网站检测方法cn202110359991.2”和“识别钓鱼网站的方法及装置cn201510885473.9”使用的特征中包含了第三方特征,这会增加特征提取的时间,在实时场景中应用性较差。
技术实现要素:
6.为解决上述问题,本发明公开了一种基于url多角度特征的钓鱼网站检测方法,属于信息安全技术领域。所述方法首先捕获网页对应的实际url作为待测url,然后对待测url分解获得各组件信息;之后对url及组件进行预处理,包括使用文本分解算法获得token和
分词列表,使用文本可读性检测算法计算token可读性权值;从完整url、各组件以及预处理结果提取成分特征和语言特征作为待测url的特征;最后将url特征输入训练好的机器学习分类器进行合法性判断。与基于列表的方法相比,所述方法可以检测没有出现过的url;与基于视觉相似性和内容的方法相比,所述方法无需等待页面加载,具有较高实时性;与基于url的同类方法相比,所述方法占用资源较少,特征丰富,泛化能力更强。
7.为了实现本发明的目的,本方案具体技术步骤如下:一种基于url多角度特征的钓鱼网站检测方法,所述方法包括以下步骤:
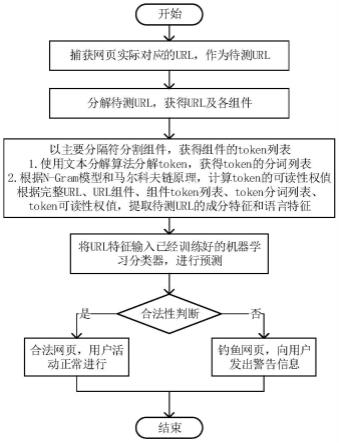
8.步骤(1)捕获目标网站的实际url,作为待测url;
9.步骤(2)将待测url分解,获得url的方案、权限、路径、参数、查询、锚点等组件;
10.步骤(3)对url及其组件提取成分特征和语言特征,获得url特征;
11.步骤(4)将url特征输入机器学习检测模型,判断url的合法性。
12.进一步的,所述步骤(1)中,由于url缩短服务及重定向等原因,用户访问的url与最终目标网站的url存在不一致的情况,本方法将目标网站最终的url作为待测url。
13.进一步的,所述步骤(2)中,一个完整的url包含若干组件,其中方案通常称为协议部分,权限包含用户名、密码、主机名和端口号四个子组件。在所有的组件中,协议和主机名是必要组件,路径和查询是可选组件,其余组件归类为不常见组件。
14.进一步的,所述步骤(3)中,对url及各组件提取的成分特征包括:
15.(3.1.1)url的成分特征:url的长度、https的使用、非常见组件的数量、url可疑符号的数量、url中数字的数量、双斜线的使用、url符号化token的数量;
16.(3.1.2)主机名(域)的成分特征:域名的长度、子域名的数量、ip地址的使用、
“‑”
的数量、子域名中顶级域名的使用、缩短服务的使用、域名中数字的数量;
17.(3.1.3)路径的成分特征:路径的长度、路径的深度、路径中可疑符号的数量、路径中顶级域名的使用、路径中token的最大长度、文件扩展名的使用;
18.(3.1.4)查询的成分特征:查询的长度、查询中数字的数量、查询的数量。
19.进一步的,所述步骤(3)中,提取语言特征具体包含如下子步骤:
20.(3.2.1)构建相对词频库,基于词频库与动态规划原理,编写连续文本分解算法,目的是将文本拆解为若干个单词,尽可能保证单词的正确性;
21.(3.2.2)根据n-gram语言模型和马尔科夫链原理,构建文本可读性检测算法,目的是计算文本被理解的难易程度;
22.(3.2.3)以主要分隔符分割url组件获得组件的中间token列表。域名中“.”为主要分隔符,路径中“/”为主要分隔符,查询中“&”和“=”为主要分隔符;
23.(3.2.4)使用连续文本分解算法分解组件的中间token列表,对所有token的分词数取对数并求和获得文本离散度,统计所有长度小于2的分词获得文本的短token数量。
24.(3.2.5)使用文本可读性检测算法计算组件每个token的可读性,如果可读性大于预先设定的阈值,则认为不可读,否则认为可读。
25.(3.2.6)对url组件提取的语言特征中,主机名的语言特征包括:敏感词汇的数量(“www”的变形,“https”的使用)、元音字母的数量、唯一字符的数量、子域名的离散度、域名中短token的数量、二级域名的可读性、子域名中token可读性的最大值;路径的语言特征包括:路径的离散度、路径中短token的数量、路径中不可读token的数量。成分特征和语言特
征充分反映了url在组件和语言上的差异性,使url特征更加多样,可以提高模型的泛化能力。
26.进一步的,所述步骤(4)中,训练的机器学习算法包括随机森林、xgboost、人工神经网络、决策树、梯度提升树、adaboost、k最近邻、支持向量机、逻辑回归、朴素贝叶斯等;将url特征输入机器学习分类器判断url的合法性,如果是钓鱼url,则向用户发出警告,否则用户活动正常进行。
27.与现有技术相比,本发明的技术方案具有以下有益技术效果。
28.(1)本发明提出的钓鱼网站检测方法,将启发式与机器学习结合在一起。钓鱼网站具有生命周期较短、更新迭代快的特点,与基于列表的方法相比,所述方法不需要频繁更新和维护黑名单或白名单,可以检测没有出现过的钓鱼网站。
29.(2)本发明提出的钓鱼网站检测方法从url中提取特征,无需等待页面加载,无需从第三方获取特征,与基于视觉相似性与内容的方法相比,所述方法所需时间较短,可应用在实时环境中。
30.(3)本发明从url提取了成分特征和语言特征,成分特征不仅包括对url的整体分析,还包含对各组件的分析;语言特征可以在url组件分析的基础上,进一步区分合法和钓鱼url在语言上的不同,这使得所使用的特征更加全面地反映了url在组件和语言之间的差异性。与传统的基于url的方法相比,所述方法模型更加轻量级,不依赖第三方服务,特征更加多样,极大提高了模型的泛化能力,更加满足现实网络环境复杂、多变的特点。
附图说明
31.图1为钓鱼网站检测流程图;
32.图2为url结构信息图;
33.图3为文本分解流程图。
具体实施方式
34.以下将结合具体实施例对本发明提供的技术方案进行详细说明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
35.实施例:本发明提供的一种基于url多角度特征的钓鱼网站检测方法,其钓鱼网站检测流程如图1所示,包括如下步骤:
36.步骤(1)捕获目标网站的实际url,作为待测url;
37.本发明的一个实施例中,由于url缩短服务及重定向等原因,用户访问的url与最终目标网站的url存在不一致的情况,本方法将目标网站最终的url作为待测url。表1是实例网页url的初始和最终状态,本实例url使用了缩短服务。
38.表1:url实例
[0039] url初始urlhttp://bit.ly/shpee_coins待测urlhttps://bonussh0peecoin.blogspot.com/2021/08/shopee-fortune-box.html?m=1
[0040]
步骤(2)将待测url分解,获得url的方案、权限、路径、参数、查询、锚点等组件,图2为url的结构信息;
[0041]
本发明的一个实施例中,一个完整的url包含若干组件,其中方案通常称为协议部分,权限包含用户名、密码、主机名和端口号四个子组件。在所有的组件中,协议和主机名是必要组件,路径和查询是可选组件,其余组件归类为不常见组件。url的分解结果如表2所示:
[0042]
表2:url及组件信息
[0043] 结果urlhttps://bonussh0peecoin.blogspot.com/2021/08/shopee-fortune-box.html?m=1方案https用户名none密码none主机名bonussh0peecoin.blogspot.com端口号none路径/2021/08/shopee-fortune-box.html参数none查询m=1锚点none
[0044]
步骤(3)对url及其组件提取成分特征和语言特征,获得url特征;
[0045]
本发明的一个实施例中,对url及各组件提取的成分特征如下所述,具体特征见表3:
[0046]
(3.1.1)url的成分特征:url的长度、https的使用、非常见组件的数量、url可疑符号的数量、url中数字的数量、双斜线的使用、url符号化token的数量;
[0047]
(3.1.2)主机名(域)的成分特征:域名的长度、子域名的数量、ip地址的使用、
“‑”
的数量、子域名中顶级域名的使用、缩短服务的使用、域名中数字的数量;
[0048]
(3.1.3)路径的成分特征:路径的长度、路径的深度、路径中可疑符号的数量、路径中顶级域名的使用、路径中token的最大长度、文件扩展名的使用;
[0049]
(3.1.4)查询的成分特征:查询的长度、查询中数字的数量、查询的数量。
[0050]
表3:url成分特征
[0051]
特征值特征值url_length72shortening_service-1no_https-1digit_in_domain1suspicious_components_url0path_length32suspicious_symbols_url13path_depth3digit_in_url8suspicious_symbols_path3double_slash_redirecting-1tld_in_path1url_token_count7longest_path_token23domain_length28'having_file_ext1subdomain_count1query_length3having_ip_address-1digit_in_query1prefix_suffix_in_domain-1query_count1tld_in_subdomain0
ꢀꢀ
[0052]
本发明的一个实施例中,提取语言特征具体包含如下子步骤:
[0053]
(3.2.1)构建相对词频库,基于词频库与动态规划原理,编写连续文本分解算法,目的是将文本拆解为若干个单词,尽可能保证单词的正确性,文本分解的流程如图3所示;
[0054]
(3.2.2)根据n-gram语言模型和马尔科夫链原理,构建文本可读性检测算法,目的是计算文本被理解的难易程度;
[0055]
(3.2.3)以主要分隔符分割url组件获得组件的中间token列表,本实施例组件的token列表如表4所示。域名中“.”为主要分隔符,路径中“/”为主要分隔符,查询中“&”和“=”为主要分隔符;
[0056]
表4:url部分组件token列表
[0057]
组件token列表主机名['bonussh0peecoin','blogspot','com']路径['2021','08','shopee-fortune-box.html']查询['m','1']
[0058]
(3.2.4)使用连续文本分解算法分解组件的中间token列表,对所有token的分词数取对数并求和获得文本离散度,统计所有长度小于2的分词获得文本的短token数量,部分组件的分词列表如表5所示;
[0059]
表5:url部分组件分词列表
[0060]
组件token列表主机名['bonus','sh','0','pee','coin','blogspot','com']路径['2021','08','shop','ee','fortune','box','html']查询['m','1']
[0061]
(3.2.5)使用文本可读性检测算法计算组件每个token的可读性,如果可读性大于预先设定的阈值,则认为不可读,否则认为可读。
[0062]
(3.2.6)对url组件提取的语言特征中,主机名的语言特征包括:敏感词汇的数量(“www”的变形,“https”的使用)、元音字母的数量、唯一字符的数量、子域名的离散度、域名中短token的数量、二级域名的可读性、子域名中token可读性的最大值;路径的语言特征包括:路径的离散度、路径中短token的数量、路径中不可读token的数量。本实例url语言特征见表6所示:
[0063]
表6:实例url语言特征
[0064]
特征值sensitive_vocabulary0vowel_domain8unique_char_domain7dispersion_subdomain2.322short_token_domain3elusive_domain0most_elusive_subdomain2.865dispersion_path2.322
short_token_path2elusive_token_path0
[0065]
步骤(4)将url特征输入机器学习检测模型,判断url的合法性;
[0066]
本发明的一个实施例中,训练的机器学习算法包括随机森林、xgboost、人工神经网络、决策树、梯度提升树、adaboost、k最近邻、支持向量机、逻辑回归、朴素贝叶斯等,将随机森林作为主要分类器,输入url特征并判断url的合法性,待测url最终的判断结果为钓鱼url,用户将会收到该网页的警告信息。
[0067]
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1