一种统一监控管理平台的制作方法
1.本发明涉互联网技术领域,具体涉及一种统一监控管理平台。
背景技术:
2.目前涉及运维的团队主要分为网络硬件设施、iaas云平台、通用paas平,其中,网络硬件设施使用了第三方提供的日志审计平台对日志和性能进行监控管理;iaas云平台包括vmware和openstack两部分,其中vmware使用自带的vrealize suite云管理平台对日志和性能进行监控管理;openstack使用自带的celimeter和开源的zabbix搭配进行性能监控,而日志方面目前仍未实现统一管理。
3.各个团队之间监控平台和日志管理系统相互独立,日志、监控、告警管理分散,信息不对称,造成了一旦应用发生故障,运维人员很难得到全面、最新的运行信息,难以有效定位故障具体原因,导致应用故障恢复时间过长等问题。为了提升运维效率和服务质量,快速有效的定位应用故障发生根源,有必要建设统一的监控平台。
技术实现要素:
4.本发明意在提供一种统一监控管理平台,以完善在应用监控、告警和故障定位与解决等方面的能力,实现从底层网络资源到上层应用的立体化监控体系。
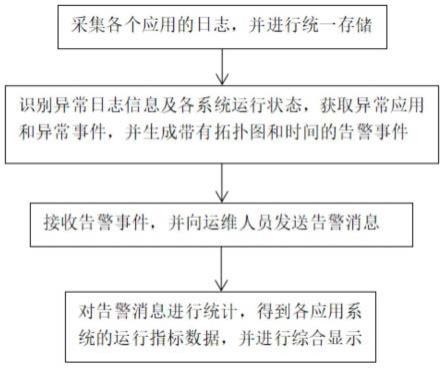
5.为达到上述目的,本发明采用如下技术方案:一种统一监控管理平台,包括:
6.采集模块,采集各个应用的日志,进行格式转换处理,并进行统一存储,同时存储故障排查表;
7.识别模块,识别异常日志信息及各系统运行状态,获取异常应用和异常事件,并生成带有拓扑图和时间的告警事件;
8.收发模块,接收告警事件,并向运维人员发送告警消息;
9.统计模块,对告警消息进行统计,得到各应用系统的运行指标数据,并进行综合显示。
10.本方案的原理及优点是:实际应用时,各个应用之间是相互独立的,因此需要先采集各个应用的日志,为了后续处理方便快捷,需进行格式转换处理,再统一存储;曾经发生过的异常事件,及其对应的故障排除操作均存储在故障排查表中,运维人员能够根据故障排查表迅速的处理异常事件,提高处理效率。
11.采集各个应用的日志后,需要对日志信息及各系统运行状态进行异常识别,获取异常应用和异常事件,获取异常应用的情况,异常应用中带有应用的拓扑关系,根据拓扑关系能够对故障点进行排查,获取异常事件,生成带有拓扑图和时间的告警事件,并将告警消息发送给运维人,运维人员能够及时追踪故障点,并对故障进行处理,缩短应用故障恢复时长,提升运维效率和服务质量。
12.最后,对告警消息进行统计,得到各应用系统的运行指标数据,并进行综合显示,运维人员能够得到全面、最新的运行信息,便于对各应用进行全局把控,提升管理效率。
13.优选的,作为一种改进,所述采集模块还包括:
14.频率设置模块,设置不同应用的采集频率;
15.定时获取日志模块,根据采集频率定时从elk统一日志平台获取指定应用的日志信息。
16.技术效果:能够根据实际应用的情况,对出现异常情况次数多、时间间隔短、较高的重要性的应用设置较高的采集频率,确保异常获取的及时性。
17.优选的,作为一种改进,所述识别模块还包括:
18.告警规则配置模块,对日志告警规则进行配置,所述日志告警规则包括应用告警规则和异常事件告警规则;
19.定时查询模块,对各个应用的应用状态进行定时查询,同时对应用异常日志定时查询;
20.异常日志处理模块,对异常日志进行合并、过滤和升级处理。
21.技术效果:不同的公司、不同的项目,所关注的异常事件是不同的,提供告警规则配置利于个性化的应用;定时查询应用状态,利于管理人员及时掌握当前运行情况,并及时对不合理的地方做出调整,异常日定时查询,实现异常日志的监控;且异常日志会存在事件重合的情况,对异常事件进行合并有益于操作流程的简洁;对于重要程度低、紧急程度低的异常事件进行过滤,对于重要程度高、紧急程度高的异常事件进行升级处理,利于资源的高效分配。
22.优选的,作为一种改进,所述应用状态包括日志告警规则、应用的拓扑图及应用当前最新状态。
23.技术效果:根据应用拓扑图,能够了解应用相关联的节点,利于根据节点倒退异常事件发生源头,从根源解决问题,更好的设置日志告警规则。
24.优选的,作为一种改进,所述日志告警规则有应用的索引值配置、异常日志识别的参数及参数值、日志的刷新频率。
25.技术效果:根据日志告警规则对异常事件进行告警。
26.优选的,作为一种改进,所述告警消息的类别包括应用的事件告警、应用异常状态通知、异常日志告警。
27.技术效果:一个应用满足一种发送类型的条件就对通知对象发送消息,从应用本身、应用事件和日志内容三个角度考虑异常事件的生成,考虑更加全面。
28.优选的,作为一种改进,所述收发模块还包括:
29.自定义模块,自定义告警等级和告警消息模板;
30.故障排查模块,根据拓扑图定位故障点,并根据故障排查表排查异常原因,同时匹配出排除异常的操作手册;
31.异常分析模块,根据拓扑图定位新的异常事件的故障点,并根据对历史操作进行相关性分析,得到排除异常的操作建议;
32.操作建议发送模块,将故障点、排除异常的操作手册和操作建议发送给运维人员。
33.技术效果:根据告警事件,对告警等级进行自定义设置,并自主选择告警模板,能够实现个性化应用,提高使用好感;同时定位故障点及对应的排除故障的操作,利于运维人员高效排除故障,恢复正常运行。
34.优选的,作为一种改进,所述收发模块还包括:
35.新异常排除操作存储模块,将运维人员对新的异常事件实际的操作生成新的操作手册,并存入到故障排查表中。
36.技术效果:随着异常处理情况增多,故障排查表类型更加丰富,利于后续出现同样异常事件的处理。
37.优选的,作为一种改进,所述统计模块还包括:
38.运行指标数据生成模块,按时间段对各应用的告警事件、告警事件的级别、告警总数、最常见的告警事件名称、告警处理情况、告警信息发送情况进行统计,生成运行指标数据。
39.技术效果:将各应用的运行情况进行统计,利于清晰快捷的掌握运行情况。
40.优选的,作为一种改进,还包括显示频率设置模块,用于设置综合显示的更新频率;所述显示频率设置模块还包括:
41.重要性设置模块,赋予各应用的运行指标数据以不同的权重,并进行加权,得到重要性指标,根据重要性指标设置显示的更新频率;
42.排序模块,将最新的告警消息按重要性指标从大到小进行排序显示。
附图说明
43.图1为本发明实施例的流程示意图。
具体实施方式
44.实施例基本如附图1所示:
45.一种统一监控管理平台,包括:
46.采集模块,采集各个应用的日志,进行格式转换处理,并进行统一存储,同时存储故障排查表;对于基础设施相关的日志,系统自动从基础设施日志审计平台采集,经过格式转换处理后存储到elk统一日志平台,方便运维人员查询;各个应用之间是相互独立的,因此需要先采集各个应用的日志,为了后续处理方便快捷,需进行格式转换处理,再统一存储;曾经发生过的异常事件,及其对应的故障排除操作均存储在故障排查表中,运维人员能够根据故障排查表迅速的处理异常事件,提高处理效率。
47.频率设置模块,设置不同应用的采集频率;这里的应用为第三方系统,通过第三方提供的api接口获取所需数据和信息;应用组件和中间件运行状态从prometheus监控平台和paas平台获取,主机资源和基础设施部分的运行状态从iaas平台获取;日志信息从elk统一日志平台获取;不同的应用日志更新情况不同,实际应用时,根据实际需求设置不同应用的采集频率,避免不必要的工作,提高运行效率。
48.定时获取日志模块,根据采集频率定时从elk统一日志平台获取指定应用的日志信息,在elk统一日志平台能够收集、分析和存储多种格式的日志信息,同时提供可视化展示功能。
49.识别模块,识别异常日志信息及各系统运行状态,获取异常应用和异常事件,并生成带有拓扑图和时间的告警事件;所述识别模块还包括:
50.告警规则配置模块,对日志告警规则进行配置,所述日志告警规则包括应用告警
规则和异常事件告警规则;所述日志告警规则有应用的索引值配置、异常日志识别的参数及参数值、日志的刷新频率。不同的公司、不同的项目,所关注的异常事件是不同的,提供告警规则配置利于个性化的应用。
51.定时查询模块,对各个应用的应用状态进行定时查询,同时对应用异常日志定时查询;所述应用状态包括日志告警规则、应用的拓扑图及应用当前最新状态。定时查询应用状态,利于管理人员及时掌握当前运行情况,并及时对不合理的地方做出调整,异常日定时查询,实现异常日志的监控。
52.异常日志处理模块,对异常日志进行合并、过滤和升级处理。合并是对同一批次内同一应用的相同事件进行合并;同时针对接收方为相同人员的事件自动进行聚合处理,合并为一条告警消息发送;过滤是在指定周期内,对来自于同一应用的相同事件,根据事件等级进行判断,自动过滤同等级或低等级的告警事件;升级是当未处理事件达到升级阈值时,系统自动对该事件进行升级处理,发送告警消息给更高级别的接收人。对异常日志进行合并、过滤和升级处理,有益于操作流程的简洁,同时还利于资源的高效分配。
53.收发模块,接收告警事件,并向运维人员发送告警消息;所述收发模块还包括:
54.自定义模块,自定义告警等级和告警消息模板;根据告警事件,对告警等级进行自定义设置,并自主选择告警模板,能够实现个性化应用,提高使用好感。
55.故障排查模块,根据拓扑图定位故障点,并根据故障排查表排查异常原因,同时匹配出排除异常的操作手册;拓扑图展示了与应用组件相关的各个实例节点,根据实例节点能够对故障点进行排查,故障排查表中还存储有曾经发生过的异常事件,及其对应的故障排除操,运维人员能够根据故障排查表迅速的处理异常事件,提高处理效率。
56.异常分析模块,根据拓扑图定位新的异常事件的故障点,并根据对历史操作进行相关性分析,得到排除异常的操作建议;当新的异常事件发生,故障排查表中无法查询时,对历史操作进行分析,为运维人员提出建议,提高运维人员处理新的异常事件的效率。
57.操作建议发送模块,将故障点、排除异常的操作手册和操作建议发送给运维人员。
58.新异常排除操作存储模块,将运维人员对新的异常事件实际的操作生成新的操作手册,并存入到故障排查表中。随着异常处理情况增多,故障排查表类型更加丰富,利于后续出现同样异常事件的处理。
59.统计模块,对告警消息进行统计,得到各应用系统的运行指标数据,并进行综合显示。所述统计模块还包括:
60.运行指标数据生成模块,按时间段对各应用的告警事件、告警事件的级别、告警总数、最常见的告警事件名称、告警处理情况、告警信息发送情况进行统计,生成运行指标数据;将各应用的运行情况进行统计,利于清晰快捷的掌握运行情况。如,告警事件统计包括告警事件的已处理、未处理分;告警事件的级别统计包括高、中、低等级的告警事件分布;告警总数的统计包括各应用的告警总数,及各告警类型的总数;告警处理情况包括已处理和未处理;告警信息发送情况包括已发送、已升级和未发送。
61.此外,还需要对应用异常状态统计,对故障和停止状态的应用进行汇总统计。
62.显示频率设置模块,设置综合显示的更新频率;所述显示频率设置模块还包括:
63.重要性设置模块,赋予各应用的运行指标数据以不同的权重,并进行加权,得到重要性指标,根据重要性指标设置显示的更新频率;重要性指标值越大,重要性越高,对应的
更新频率就越低,确保运维人员能够及时引起关注;
64.排序模块,将最新的告警消息按重要性指标从大到小进行排序显示,将最近发生的告警事件及告警持续时长进行展示。当出现异常的情况较多时,对重要性程度高的告警消息进行高频显示,并对最新的告警事件进行重要性排序,利于对应的处理人员高效处理对应事件。
65.以上所述的仅是本发明的实施例,方案中公知的具体技术方案和/或特性等常识在此未作过多描述。应当指出,对于本领域的技术人员来说,在不脱离本发明技术方案的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本技术要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1