超密集组网多业务切片资源分配方法及装置
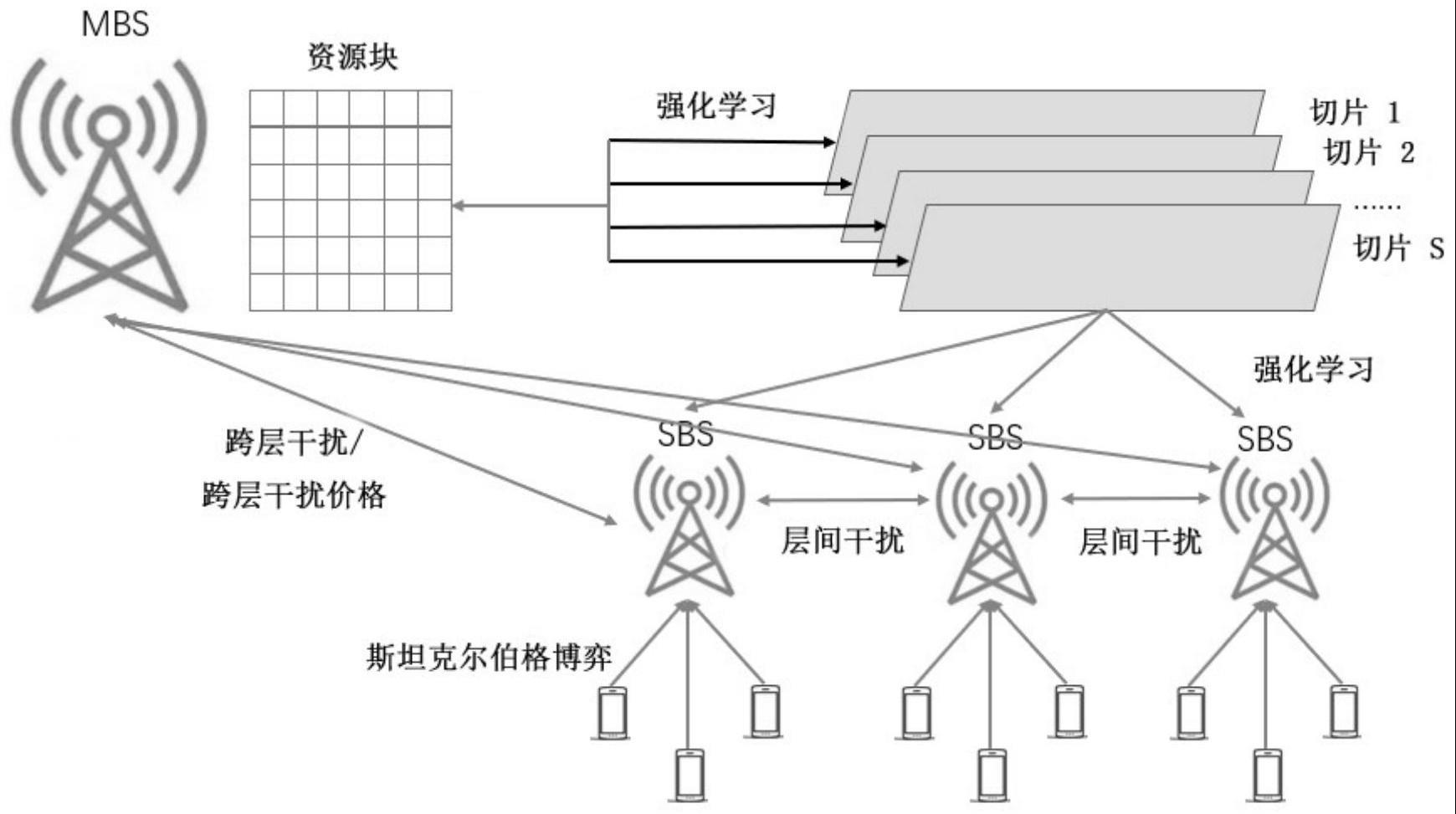
本发明涉及通信,尤其涉及一种超密集组网多业务切片资源分配方法及装置。
背景技术:
1、网络切片技术已经成为第五代移动网络(fifth generation mobile network,5g)的关键技术之一,在下一代移动网络以及其他技术领域中,网络对用户的差异性服务提出了更高的灵活性、隔离性、隐私性和定制性等需求,与此同时,提供特定服务的小范围网络的重要性也会增加,以满足不同场景和不同人群的需求。
2、新兴的解决方案之一是引入宏微基站异构的超密集组网,满足用户的传输容量和覆盖范围需求。基站的超密集组网可以在一定程度上提高系统的频谱效率,并通过快速资源调度进行动态无线资源调配,并在微基站(small base station,sbs)处复用宏基站(macro base station,mbs)的许可频谱,提高系统无线资源利用率和频谱效率,但同时也带来了系统干扰和系统成本问题。为了提供可靠的服务,微基站需要获取宏基站频谱的复用许可权,这需要在宏基站和微基站之间进行干扰协调,以保证其运营不受有害干扰的影响。
3、因此,亟需一种在保证用户通信质量和通信需求的前提下,减少微基站竞争干扰,优化无线资源分配的方法。
技术实现思路
1、鉴于此,本发明实施例提供了一种超密集组网多业务切片资源分配方法及装置,以消除或改善现有技术中存在的一个或更多个缺陷,解决现有技术在提高系统无线资源利用率和频谱效率时导致的系统干扰和系统成本的问题。
2、一方面,本发明提供了一种超密集组网多业务切片资源分配方法,其特征在于,所述超密集组网包括至少一个宏基站,每个宏基站还连接服务多个微基站;所述微基站的用户复用对应宏基站的切片资源,所述方法基于所述微基站与所述宏基站之间产生跨层干扰,以及相邻微基站之间产生同层干扰进行多业务切片资源分配;所述方法包括以下步骤:
3、获取多智能体强化学习模型,所述多智能体强化学习模型在每个微基站上均部署策略网络和价值网络;每个策略网络以对应单个微基站中各用户的传输速率以及总发射功率作为状态参数构建状态空间;获取用于表示各微基站中用户是否复用宏基站中资源块的关联参数,并以各微基站的关联参数集合和预测的其他各微基站的发射功率集合作为动作参数构建动作空间;每个微基站获取自身状态参数,根据所述策略网络选择相应的动作,每个微基站的价值网络根据相应微基站的状态参数和选择的动作以及其他微基站的状态参数和动作生成预估q值,并用于对相应微基站的策略网络进行参数更新;以最大化奖励值为优化目标构建所述预估q值与模型实际q值的损失函数,对所述价值网络进行参数更新;直至到达预设性能要求;
4、其中,在状态更新过程中,所述宏基站根据跨层干扰价格和用户在微基站中复用资源块产生的跨层干扰构建宏基站收益计算式;所述微基站根据所述关联参数、资源块固定带宽长度、信号与干扰加噪声比、同层干扰价格、同层干扰、所述跨层干扰价格和跨层干扰构建微基站收益计算式;将所述宏基站作为领导者,将各微基站作为追随者构建非合作博弈;固定所述关联参数的值,采用逆向归纳法对所述微基站收益计算式进行求解,得到各微基站的发射功率均衡解,以用于更新每个策略网络的状态空间;将所述发射功率均衡解代入所述宏基站收益计算式,得到所述跨层干扰价格均衡解;
5、将各微基站的状态参数输入所述多智能体强化学习模型,生成相应的动作策略,实现多业务切片资源分配。
6、在本发明的一些实施例中,所述宏基站根据跨层干扰价格和用户在微基站中复用资源块产生的跨层干扰构建宏基站收益计算式,所述宏基站收益计算式为:
7、
8、其中,umbs表示所述宏基站收益;uue表示所有微基站的用户集合;uprb表示资源块的总数;ubs表示所述宏基站和所有微基站的集合;表示用户i在微基站b使用资源块j的跨层干扰价格;表示用户i在微基站b使用资源块j造成的跨层干扰。
9、在本发明的一些实施例中,所述微基站根据所述关联参数、资源块固定带宽长度、信号与干扰加噪声比、同层干扰价格、同层干扰、所述跨层干扰价格和跨层干扰构建微基站收益计算式,所述微基站收益计算式为:
10、
11、s.t.
12、
13、
14、
15、
16、
17、
18、其中,ub表示所述微基站收益;uue,b表示微基站b的用户集合;us表示切片的种类;表示用户i和切片s、资源块j、微基站b之间的关联关系;b表示资源块固定带宽长度;表示用户i在微基站b使用资源块j造成信号与干扰加噪声比;表示用户i在微基站b使用资源块j的同层干扰价格;表示用户i在微基站b使用资源块j造成的同层干扰;表示用户i在微基站b使用资源块j的跨层干扰价格;表示用户i在微基站b使用资源块j造成的跨层干扰;表示用户i在微基站b分配给资源块j的发射功率;uue表示所有微基站的用户集合;ubs表示所述宏基站和所有微基站的集合;imax表示干扰最大值;uprb表示资源块的总数;τ表示资源块总数。
19、在本发明的一些实施例中,每个策略网络以对应单个微基站中各用户的传输速率以及总发射功率作为状态参数构建状态空间,其中,所述总发射功率使用所述发射功率均衡解,所述状态参数表示为:
20、
21、其中,sj(t)表示t时刻微基站的状态参数;rn,j(t)表示t时刻第n个用户复用资源块j的传输速率;用户i在微基站b*分配给资源块j的发射功率;uj表示复用资源块j的用户集合;
22、每个微基站的价值网络根据相应微基站的状态参数和选择的动作以及其他微基站的状态参数和动作生成预估q值,则所述价值网络的状态参数表示为:
23、sj'(t)=(sj(t),aj(t),s-j(t),a-j(t));
24、其中,sj(t)表示t时刻微基站的状态参数;aj(t)表示t时刻微基站的动作参数;s-j(t)表示t时刻其他微基站的状态参数集合;a-j(t)表示t时刻其他微基站的动作参数集合。
25、在本发明的一些实施例中,获取用于表示各微基站中用户是否复用宏基站中资源块的关联参数,并以各微基站的关联参数集合和预测的其他各微基站的发射功率集合作为动作参数构建动作空间,所述动作参数表示为:
26、aj(t)={wj,p-j};
27、其中,
28、
29、
30、其中,aj(t)表示t时刻微基站的动作参数;wj表示关联参数的集合;p-j表示预测的其他微基站发射功率的集合;表示用户i和切片s、资源块j、微基站b之间的关联关系;表示用户i在微基站b分配给资源块j的发射功率;uj表示复用资源块j的用户集合。
31、在本发明的一些实施例中,每个微基站的价值网络根据相应微基站的状态参数和选择的动作以及其他微基站的状态参数和动作生成预估q值,根据所述预估q值构建策略梯度,并用于对相应微基站的策略网络进行参数更新,所述策略梯度的计算式为:
32、
33、其中,表示所述策略梯度;θ表示策略参数;j(uj)表示累计预估奖励值;d表示经验回放池;uj(aj|sj)表示微基站根据状态做出的动作策略;表示所述价值网络;sj表示所述价值网络预估的微基站的状态;aj表示所述价值网络预估的微基站的动作;sother表示所述价值网络预估的其他微基站的状态;aother表示所述价值网络预估的其他微基站的动作。
34、在本发明的一些实施例中,以最大化奖励值为优化目标构建所述预估q值与模型实际q值的损失函数,对所述价值网络进行参数更新,所述损失函数的计算式为:
35、
36、其中,表示所述损失函数;θ表示策略参数;uj表示自适应权重参数;r表示动作产生的更新的结果;表示所述价值网络;sj表示所述价值网络预估的微基站的状态;aj表示所述价值网络预估的微基站的动作;sother表示所述价值网络预估的其他微基站的状态;aother表示所述价值网络预估的其他微基站的动作;表示所述实际q值。
37、在本发明的一些实施例中,以最大化奖励值为优化目标构建所述预估q值与模型实际q值的损失函数,对所述价值网络进行参数更新,所述奖励值的计算式为:
38、
39、其中,rewardj表示所述奖励值;uj表示所述自适应权重参数;rj表示微基站各用户复用资源块j的总传输速率;n表示用户总数量;r-j表示其他微基站的总传输速率;表示同层干扰价格;表示同层干扰;表示跨层干扰价格;表示跨层干扰;uj表示复用资源块j的用户集合。
40、在本发明的一些实施例中,所述自适应权重参数是根据全局环境的状态学习得到;
41、当uj=1时,所述奖励值仅与微基站自身的传输速率有关,为零和博弈;
42、当0<uj<1时,所述奖励值不仅与微基站自身的传输速率有关,还与其他微基站的传输速率有关,形成混合博弈。
43、另一方面,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上文中提及的任意一项所述方法的步骤。
44、本发明的有益效果至少是:
45、本发明提供一种超密集组网多业务切片资源分配方法及装置,通过获取预训练得到的多智能体强化学习模型,将各微基站自身状态参数输入该多智能体强化学习模型,相应生成动作策略,实现了在保证用户通信质量和通信需求的前提下,减少微基站的竞争和干扰,从而优化无线资源分配,缓解频谱紧张。
46、在多智能体强化学习模型训练中,预先构建宏基站收益计算式和微基站收益计算式,将资源分配问题建模为非合作博弈,求得发射功率均衡解和跨层干扰价格均衡解;再将发射功率均衡解用于更新多智能体强化学习模型中各策略网络的状态空间,引导模型向预设方向更新优化,简化模型的运算量。同时,多智能体强化学习模型在每个微基站上部署策略网络和价值网络,价值网络能够获取全局信息,生成更精准的预估q值,使得策略网络生成更优的动作策略。
47、本发明的附加优点、目的,以及特征将在下面的描述中将部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本发明的实践而获知。本发明的目的和其它优点可以通过在说明书以及附图中具体指出的结构实现到并获得。
48、本领域技术人员将会理解的是,能够用本发明实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本发明能够实现的上述和其他目的。
- 还没有人留言评论。精彩留言会获得点赞!