一种针对私有网络协议格式和状态的逆向分析方法及装置
1.本发明属于信息安全技术领域,提供了一种针对私有网络协议格式和状态的逆向分析方法及装置。
背景技术:
2.随着近年来车联网、工控网、僵尸网络等多个领域的飞速发展,当前网络流量中存在大量基于特定目的开发的私有协议。相关协议无格式文档、不公开协议源码,导致协议漏洞挖掘、网络行为分析、网络监听、僵尸网络检测等多个领域已有的部分分析方式受到限制。且大量私有协议设计中存在安全缺陷,通过闭源的方式无法确保协议安全性。因此基于流量分析协议格式、状态转换关系问题成为关乎网络安全发展的关键。
3.当前协议逆向方向从分析对象的角度可分为基于网络轨迹的协议逆向、基于程序指令的协议逆向,前者应用前景广泛,但精度略有欠缺,且无法处理加密流量。后者在加密流量分析上具有可行性,但限制条件过多。本发明所述领域为基于网络轨迹的协议逆向。已有方式可分为三大类:第一类,基于比对的格式分析,如pi、discover、netzob、netplier。第二类,采用基于统计学的字段划分。如频繁项挖掘、信息熵、n-gram、hsmm推断kw等。第三类,结合nlp方向的学习模型,如强化学习、神经网络(lstm)等。
4.基于流量的协议逆向最早的工具是在2004年提出的pi,在私有流量大量涌现的近几年逐渐成为研究热点。其中基于序列比对的协议逆向是其重要分支,且持续有成果产出。相关方法根据字节变化特征进行比对,在奖惩函数指导下,构建得分矩阵和引导树。核心思路与寻找公共最长子序列有相似之处。相关研究中pi等工具思路一脉相承,主要创新在于:奖惩函数优化、误差判定机制优化、正反向结合判定fd字段、分隔符和长度等特定字符语义判定。
5.2021年发表于ndss的netplier方法,首次结合了序列比对和概率统计,将状态标注转换改为概率问题。该类方法存在以下缺点:(1)部分方法中引入过多协议先验知识。(2)除关键词判定外,功能段格式边界存在较多错误划分。(3)比对产出结果为协议边界格式,并未充分根据格式分析结果和后续状态机构建进行关联。
技术实现要素:
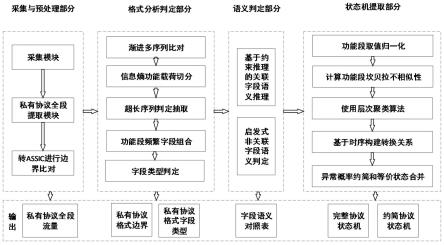
6.针对上述现有技术问题,本发明的目的在于提供一种针对私有网络协议格式和状态的逆向分析方法,该方法能够进行细粒度格式字段边界判定,方法基于渐进多序列比对、信息熵、概率统计优化协议边界判定,基于层次聚类实现状态标注。分析过程中不需要代码分析,因而能在具有限制条件的环境下根据流量进行协议分析。
7.为了达到上述目的,本发明采用如下技术方案:
8.一种针对私有网络协议格式和状态的逆向分析方法,其方法特征在于:预处理阶段增加可疑边界判定、格式逆向中使用信息熵划分功能段、使用频繁组合模式进行功能段格式合并、状态机构建的标注部分使用层次聚类、距离计算使用归一化后的坎贝拉不相似
性。具体包括以下步骤:
9.s1.采集阶段,使用tcpdump、nmap工具采集待分析流量,捕获流量包序列,得到输入流量集合,所述流量包序列包括请求流量包序列和响应流量包序列;
10.s2.预处理阶段,根据协议交互行为和流量包序列间的关系,对输入的流量包序列进行预处理,提取并初步划分私有协议全段信息;
11.s3.对步骤2得到的私有协议全段信息格式逆向阶段,结合渐进多序列比对、信息熵和频繁项,对格式边界进行细粒度判定,得到边界切分结果、字段类型,进而得到私有网络协议格式的协议边界部分;
12.s4.语义判定模块:基于边界切分结果,推断划分后的各字段语义含义,对具有关联属性字段使用已有方法进行判定,对非关联字段使用启发式判定,判定结果为“字段起止位置-语义”对应关系,进而得到私有网络协议格式的语义部分,由协议边界部分于语义部分构成私有网络协议格式;
13.s5.格式状态机构建阶段,基于格式边界推断结果进行被动状态机构建。
14.上述技术方案中,步骤2包括以下步骤:
15.2.1)底层已知协议进行解析,提取ip、端口信息,根据ip和端口信息判定流量收发方向,将采集的应用程序的流量包分为服务端和客户端两类,分别生成矩阵server、client,以txt格式存储,矩阵格式为:{{序号1,私有协议流量包1};{序号2,私有协议流量包2};...;{序号n,私有协议流量包n}};
16.2.2)私有协议全段提取,在2.1解析底层已知协议的基础上,对每条流量包中的应用层从第一字节至最后一字节进行私有协议全段提取,一条私有协议流量包存储为一行,按私有协议流量包的顺序形成包含私有协议全段的新文件server_all_oneline.txt、client_all_oneline.txt,每条流量均以十六进制表示;
17.2.3)进行可疑边界判定,将步骤2.1和步骤2.2得到的server_all_oneline.txt、client_all_oneline.txt件中的十六进制字符转换assic码对比公有特征库,对流量包中可表示为:“#?///”的符合文本特征的字符位置进行标注,构建<包序号,文本特征1,位置1,...,文本特征n,位置n>的向量进行存储,向量中的文本特征n为边界点判定依据,位置n对应判定的可疑边界点,输出server_suspicious_boundary.txt、clientsuspicious_boundary.txt文件;
18.上述技术方案中,步骤3具体步骤为:
19.3.1)执行渐进多序列比对,进行初步边界划分,统计步骤2得到的私有协议流量包数量,流量总和大于1000条的文件使用g-ins-i算法进行渐进多序列比对,小于1000条的文件使用l-ins-i算法进行渐进多序列比对,渐进多序列比对过程中使用
“‑”
对序列中空位进行补全,使用空格标识字段边界:一条流量包比对结果作为一行向量,对比结果组成二维矩阵,行记录流量包顺序和载荷、列代表字符在序列中的位置,表示为:<<0001:p1 p2 p3p4-...
‑‑
p63p64...p256>,<0002:p1 p2 p3p4-p63
‑‑
...
‑‑
p128>...>,pn(n=1...256)代表实际私有协议流量包中的一字节数据,即2个16进制位数据,将二维矩阵存储到输出文件server_msa.txt、client_msa.txt。
20.3.2)提取私有协议功能段:在步骤3.1基础上,提取二维矩阵第一列纵向向量作为输入,以空格作为纵向向量提取的边界,计算纵向序列向量的信息熵,对3.1补全过程时填
充的
“‑”
字段在计算熵值时记为零,重复计算私有协议第一列至最后一列信息熵,将在两列间熵值急剧变化的位置进行一次载荷切分,提取初始字符至熵值陡增位置的字符,判定为私有协议功能段,输出功能段文件server_functional_oneline.txt、client_functional_oneline.txt。
21.3.3)超长序列判定模块:计算server_all_oneline.txt、client_all_oneline.txt两文件的每行序列长度,即每条输入流量包长度,以长度均值加标准差作为阈值,对超过阈值长度的单条流量包进行标记和提取,输出为server_oversize_oneline.txt、client_oversize_oneline.txt。
22.3.4)过度切割功能段组合:读取2.3中可疑边界,若可疑边界前后包含“空格标识”则不进行处理,若标注为可疑边界且前后无“空格标识”的字段,在可疑边界所在位置后方插入空格列。之后对长度为1字节和2字节的功能段计算字节间的组合频率,使用闭合频繁项进行挖掘,合并功能段中的高概率组合,合并长度上限设定为3字节(即6个16进制位),对判定为需要合并的字节,删除两列字节之间的空格,输出处理后的边界判定结果文件server_result.txt、client_result.txt。
23.3.5)判定字段类型,类型分为定长定值、变长变值、定长枚举、定长递增、定长无序五类,读取3.4输出文件,对每列中取值固定的字段标记为定长定值字段,对每列中取值为
“‑”
的位置标记为变长变值字段,对取值种类小于8种的字段标记为定长枚举字段、对取值类型符合递增规律的字段标记位定长递增字段,对其他定长字段判定为定长无序字段,输出s端和c端的字段类型判定结果,如s端:<<1-2,定长定值>,<2-4,定长枚举>,...,<14-256,变长变值>>,(数字代表十六进制时的字段起止位置)。
24.上述技术方案中,步骤4具体包括:
25.4.1)读取3.3判定的超长序列,统计数据段长度,将长度值和定长无序字段进行对比,若取值一致,将该定长无序字段判定为长度段;
26.4.2)对标志位等非关联字段,根据字符取值方式进行启发式判定,构建可疑语法列表,启发式判定规则如;定长定值取值判定为标志字段,定长枚举取值判定为控制字段、协议报文类型字段,定长递增型取值判定为序号位字段、功能段中定长高熵值字段判定为校验码字段,分别输出s端和c端的语义判定结果,判定结果为“字段起止位置-语义”对应关系,格式为:<字段位置,字段类型,可疑属性1,...,可疑属性n>。
27.上述技术方案中,步骤5具体步骤为:
28.5.1)功能段取值归一化,对3.2步骤中提取的功能段进行归一化处理,读取server_functional_oneline.txt、client_functional oneline.txt两文件,以文件中的“空格标识”为边界,分别抽取文件中的列向量,使用“0均值归一化”压缩功能段取值到同维度空间内,生成server result normalization.txt、client_result_normalization.txt;
29.5.2)状态标注,计算5.1中归一化后的功能段间的距离,使用层次聚类agnes算法进行状态标注,聚类出不同消息状态,距离计算中,读取5.1中server result normalization.txt、client result normalization.txt的每条横向向量,以每条流量包功能段的坎贝拉不相似值作为划分依据,聚类过程中,将每个流量包作为初始簇,计算任意两簇距离,合并距离最近的两个簇,生成新簇,重复合并距离最近簇,当最远两簇距离超过阈值或簇个数达指定值,终止层次聚类算法;
30.5.3)基于步骤5.2的状态标注,进行状态机绘制,基于类间转换的时序关系绘制转换边,使用已有的基于异常概率的状态剪枝、基于等价状态的状态合并两种方式进行状态简化。
31.上述技术方案中,格式边界达到了字节粒度划分、针对功能段过度切分进行合并处理。状态机提取部分,结合格式的切分信息优化了状态标注。
32.本发明还提供了一种针对私有网络协议格式和状态的逆向分析装置,包括以下模块:
33.信息采集录入模块:使用tcpdump、nmap工具采集待分析流量,捕获流量包序列,得到输入流量集合,所述流量包序列包括请求流量包序列和响应流量包序列;
34.预处理阶段模块:根据协议交互行为和流量包序列间的关系,对输入的流量包序列进行预处理:提取并初步划分私有协议全段信息;
35.提取协议边界模块:对私有协议全段信息格式逆向阶段,结合渐进多序列比对、信息熵和频繁项,对格式边界进行细粒度判定,得到边界切分结果、字段类型,进而得到私有网络协议格式的协议边界部分;
36.语义判定模块:基于边界切分结果,推断划分后的各字段语义含义,对具有关联属性字段使用已有方法进行判定,对非关联字段使用启发式判定,判定结果为“字段起止位置-语义”对应关系,进而得到私有网络协议格式的语义部分,由协议边界部分于语义部分构成私有网络协议格式;
37.状态机构建模块:基于格式边界推断结果进行被动状态机构建。
38.上述方案中,预处理阶段模块实现包括以下步骤:
39.2.1)底层已知协议进行解析,提取ip、端口信息,根据ip和端口信息判定流量收发方向,将采集的应用程序的流量包分为服务端和客户端两类,分别生成矩阵server、client,以txt格式存储,矩阵格式为:{{序号1,私有协议流量包1};{序号2,私有协议流量包2};...;{序号n,私有协议流量包n}};
40.2.2)私有协议全段提取,在2.1解析底层已知协议的基础上,对每条流量包中的应用层从第一字节至最后一字节进行私有协议全段提取,一条私有协议流量包存储为一行,按私有协议流量包的顺序形成包含私有协议全段的新文件server_all_oneline.txt、client_all_oneline.txt,每条流量均以十六进制表示;
41.2.3)进行可疑边界判定,将步骤2.1和步骤2.2得到的server_all_oneline.txt、client_all_oneline.txt件中的十六进制字符转换assic码对比公有特征库,对流量包中可表示为:“#?///”的符合文本特征的字符位置进行标注,构建<包序号,文本特征1,位置1,...,文本特征n,位置n>的向量进行存储,向量中的文本特征n为边界点判定依据,位置n对应判定的可疑边界点,输出server_suspicious_boundary.txt、client_suspicious_boundary.txt文件。
42.上述方案中,提取协议边界模块实现具体步骤为:
43.3.1)执行渐进多序列比对,进行初步边界划分,统计步骤2得到的私有协议流量包数量,流量总和大于1000条的文件使用g-ins-i算法进行渐进多序列比对,小于1000条的文件使用l-ins-i算法进行渐进多序列比对,渐进多序列比对过程中使用
“‑”
对序列中空位进行补全,使用空格标识字段边界;一条流量包比对结果作为一行向量,对比结果组成二维矩
阵,行记录流量包顺序和载荷、列代表字符在序列中的位置,表示为:<<0001:p1 p2 p3p4-...
‑‑
p63p64...p256>,<0002:p1 p2 p3p4-p63
‑‑
...
‑‑
p128>...>,pn(n=1...256)代表实际私有协议流量包中的一字节数据,即2个16进制位数据,将二维矩阵存储到输出文件server_msa.txt、client_msa.txt;
44.3.2)提取私有协议功能段:在步骤3.1基础上,提取二维矩阵第一列纵向向量作为输入,以空格作为纵向向量提取的边界,计算纵向序列向量的信息熵,对3.1补全过程时填充的
“‑”
字段在计算熵值时记为零,重复计算私有协议第一列至最后一列信息熵,将在两列间熵值急剧变化的位置进行一次载荷切分,提取初始字符至熵值陡增位置的字符,判定为私有协议功能段,输出功能段文件server_functional_oneline.txt、client_functional_oneline.txt;
45.3.3)超长序列判定模块:计算server_all_oneline.txt、client_all_oneline.txt两文件的每行序列长度,即每条输入流量包长度,以长度均值加标准差作为阈值,对超过阈值长度的单条流量包进行标记和提取,输出为server_oversize_oneline.txt、client_oversize_oneline.txt;
46.3.4)过度切割功能段组合:读取步骤2.3中可疑边界,若可疑边界前后包含“空格标识”则不进行处理,若标注为可疑边界且前后无“空格标识”的字段,在可疑边界所在位置后方插入空格列。之后对长度为1字节和2字节的功能段计算字节间的组合频率,使用闭合频繁项进行挖掘,合并功能段中的高概率组合,合并长度上限设定为3字节,对判定为需要合并的字节,删除两列字节之间的空格,输出处理后的边界判定结果文件server_result.txt、client_result.txt;
47.3.5)判定字段类型,类型分为定长定值、变长变值、定长枚举、定长递增、定长无序五类,读取步骤3.4的输出文件,对每列中取值固定的字段标记为定长定值字段,对每列中取值为
“‑”
的位置标记为变长变值字段,对取值种类小于8种的字段标记为定长枚举字段、对取值类型符合递增规律的字段标记位定长递增字段,对其他定长字段判定为定长无序字段,输出s端和c端的字段类型判定结果,如s端:<<1-2,定长定值>,<2-4,定长枚举>,...,<14-256,变长变值>>,(数字代表十六进制时的字段起止位置);
48.上述方案中,语义判定模块实现具体包括:
49.4.1)读取3.3判定的超长序列,统计数据段长度,将长度值和定长无序字段进行对比,若取值一致,判定该定长无序字段为长度,否则判定字段为待定;
50.4.2)对标志位等非关联字段,根据字符取值方式进行启发式判定,构建可疑语法列表,启发式判定规则如;定长定值取值判定为标志字段,定长枚举取值判定为控制字段、协议报文类型字段,定长递增型取值判定为序号位字段、功能段中定长高熵值字段判定为校验码字段,分别输出s端和c端的语义判定结果,判定结果为“字段起止位置-语义”对应关系,格式为:<字段位置,字段类型,可疑属性1,...,可疑属性n>;
51.上述方案中,语义判定模块具体步骤为:
52.5.1)功能段取值归一化,对3.2步骤中提取的功能段进行归一化处理,读取server_functional_oneline.txt、client_functional oneline.txt两文件,以文件中的“空格标识”为边界,分别抽取文件中的列向量,使用“0均值归一化”压缩功能段取值到同维度空间内,生成server_result_normalization.txt、client_result_normalization.txt;
53.5.2)状态标注,计算5.1归一化后的功能段间的距离,使用层次聚类agnes算法进行状态标注,聚类出不同消息状态,距离计算中,读取5.1)中server_result_normalization.txt、client_result_normalization.txt的每条横向向量,以每条流量包功能段的坎贝拉不相似值作为划分依据,聚类过程中,将每个流量包作为初始簇,计算任意两簇距离,合并距离最近的两个簇,生成新簇,重复合并距离最近簇,当最远两簇距离超过阈值或簇个数达指定值,终止层次聚类算法;
54.5.3)基于步骤5.2的状态标注,进行状态机绘制,基于类间转换的时序关系绘制转换边,使用已有的基于异常概率的状态剪枝、基于等价状态的状态合并两种方式进行状态简化。
55.本发明同现有技术相比,其有益效果表现在:
56.一、预处理阶段进行了编码判定。基于私有协议设计与公开协议语法的部分相似性,对当前公开协议进行大量分析后,提取了文本类协议中具有标志性的字段辅助格式边界切分。可细化混合类型流量边界判定粒度。
57.二、格式边界切分部分结合字节变化特征、组合频率对不同数量的流量进行分析,对组合频率超过阈值的字段进行合并。减小单一比对方式中,不同功能字段的相似取值对边界切分的负面影响。此外,仅使用信息熵值划分功能段和载荷段,不使用信息熵进行细粒度划分,实现功能段提取优化。在为后续状态标注构建基础的同时,避免字节粒度的分析中,信息熵差值过小导致边界无法切分。
58.三、状态标注部分使用层次聚类,结合归一化后的坎贝拉距离进行类别区分。可动态调整阈值在任意层次得到指定类别数。避免由类别数量未知导致的过多人工干预。
59.四、本发明利用现有流量信息,根据需要将流量进行边界切分和状态标注,因此本发明可在非受控环境下,即无程序源码、无协议规范文档情况下进行协议逆向工作。
附图说明
60.图1是本发明的总体架构图。
具体实施方式
61.下面将结合附图及具体实施方式对本发明作进一步的描述。
62.实施例
63.针对耐德公司推出的基于以太网tcp/ip的modbus协议。方案中未引入modbus已知先验,因此modbus/tcp协议对于本方案及装置可定义为私有协议。
64.采集阶段,在核心交换机上使用抓包工具采集900条请求响应流量包序列预处理阶段,首先基于osi模型对流量进行自下而上的解析,记录流量ip、端口信息,根据ip和端口判定收发方向。之后对每条流量包中的应用层从第一字节至最后一字节进行私有协议全段提取。最后进行可疑边界判定,将十六进制字符转换assic码对比公有特征库,当前流量中无特殊字符,因此不做标注。输出server_all_oneline.txt、client_all_oneline.txt。文件内单包处理结果如下<0001:059400000006010300080004>
65.格式逆向阶段,首先执行l-ins-i算法进行渐进多序列比对。序列比对过程中使用
“‑”
补全空位,使用空格标识字段边界。对比结果组成二维矩阵,行记录流量包顺序和载荷、
列代表字段位置。输出s端和c端的第一次字段边界判定结果,单包结果如下:<0001:0594000000060103000800
‑‑
...
‑‑
04>。
66.提取二维矩阵第一段纵向向量作为输入,以空格作为纵向向量提取的边界。计算纵向序列向量的信息熵,对标记为
“‑”
的字段在计算时记为零。在序列熵值方差最大点切分载荷,提取初始字符至熵值陡增位置的字符,判定为私有协议功能段。
67.计算输入流量长度分布,对超过阈值长度的单条流量包进行标记和提取,读取s2第3步中的可疑边界作为功能段格式切分依据,对处于功能段的边界划分结果进行补全。
68.过度切割功能段组合:对非超长序列的流量包计算单字节与单字节在输入中组合频率,计算后向组合概率、合并高概率功能字段,合并长度上限设定为3字节(即6个16进制位)。输出结果“私有协议格式边界”文件server_result.txt、client_result.txt,单包结果如下:<0001:0594000000060103000800
‑‑
...
‑‑
04>。
69.进行字段类型判定,判定字段类型,读取server_msa.txt、client_msa.txt文件,对每列中取值为
“‑”
的位置标记为变长变值字段。对每列中取值固定的位置标记定长定值字段、对其他位置标记定长无序字段。输出结果“私有协议格式字段类型”。分析结果如下:<<1-4定长枚举>,<5-8定长定值>,<9-12定长无序>,<12-13定长定值>,<14-15定长枚举>,<16-496变长变值>>。
70.对长度等具有前后关联特性的字段结合约束推理分析方法进行判定,执行语法推理,判定长度字段。对标志位等非关联字段,根据字符取值方式进行启发式判定,构建可疑语法列表,定长定值取值判定为标志字段,定长枚举取值判定为控制字段、协议报文类型字段,定长递增型取值判定为序号位字段、功能段中功能段中定长高熵值字段判定为校验码字段。输出结果“字段语义对照表”,推断结果如下:<<1_4,定长枚举,控制字段,协议报文类型字段>,<5-8,定长定值,标志字段>,<9-12,定长无序,长度>,<12-13,定长定值,标志字段>,<14-15,定长枚举,控制字段,协议报文类型字段>,<16-496变长变值,数据段>>
71.格式状态机构建阶段,首先进行功能段取值归一化,读取server_result.txt、client_result.txt,以s3中判定的空格字段为边界,分别抽取文件中的列向量,使用0均值归一化对所有处理后的对功能段压缩到同维度空间内。生成server_result_normalization.txt、client_result_normalization.txt
72.层次聚类进行状态标注,使用agnes聚类出不同消息状态。将每个输入作为一簇。计算任意两簇距离,距离计算中,读取1)中每条横向向量,以每条流量包功能段的坎贝拉不相似性作为划分依据,重复上述步骤到最远两簇距离超过阈值或簇个数达指定值,终止算法。
73.状态机绘制,基于类间转换的时序关系绘制转换边,输出结果“完整协议状态机”。使用已有的基于异常概率的状态剪枝、基于等价状态的状态合并两种方式进行状态简化,输出结果“约简协议状态机”。
74.本发明还提供了一种针对私有网络协议格式和状态的逆向分析装置,包括以下模块:
75.信息采集录入模块:采集网络流量;
76.私有协议提取模块:拆解底层已知协议、解析ip端口、提取待分析私有协议字段;
77.字符比对模块:对比公开文本协议标志字段、判定可疑边界点;
78.渐进多序列比对模块:执行多序列比对、协议字符对齐;
79.字段类型判定模块:标记定长定值、变长变值、定长枚举、定长递增、定长无序字段;
80.载荷切分模块:计算纵向信息熵,切分载荷段和功能段;
81.超长序列判定模块:计算输入流量长度分布,对超过阈值长度的单条流量包进行标记和提取;
82.功能段组合模块:计算功能段组合频率,针对过度切分的单字节,计算后向组合概率、合并高概率功能字段,合并上限设定为6个16进制位,对超长序列首字节至熵值突变点的字节执行正常字段计算,对比差异结果;
83.语义判定模块:调用已有关联分析方法分析字段、基于字段变化特征启发式判定语义类型;
84.归一化模块:将对齐后判定为功能段的连续字节纵向进行0均值标准化,将原始数据集归一化为均值为0、方差1的数据集;
85.不相似性计算模块:根据坎贝拉距离计算序列功能段不相似性;
86.层次聚类算法模块:基于距离对输入流量进行分类;
87.转换关系构建模块:基于时序转换生成协议状态机;
88.概率约简模块:计算类间输入转换概率、合并状态。
89.以上仅是本发明众多具体应用范围中的代表性实施例,对本发明的保护范围不构成任何限制。凡采用变换或是等效替换而形成的技术方案,均落在本发明权利保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1