一种实时流量留存和批量抽取方法与流程
本发明涉及一种实时流量留存和批量抽取方法,属于网络流量存储与提取。
背景技术:
1、当前随着5g移动互联网、大数据、人工智能、物联网、区块链等网络技术的飞速发展,网络信息安全面临全新的技术挑战。通过分析实时网络流量,对网络流量进行流量识别、过滤、解析,得到网络安全态势分析,是维护网络安全的一种至关重要的手段。而针对实时流量,以流量摘要(主要是pcap文件)的形式留存过去一段时间的网络情况,在新的安全事件出现时,可以还原当时的场景。尤其通过对dns、netflow、http等海量访问日志的留存,可以最大程度复现过去一段时间的网络态势。对实时网络流量留存,需要考虑的主要问题为海量流量数据的存储和抽取效率问题。目前实时流量留存和批量抽取的技术在业界相关的研究和方法较少。
2、现有的业界流量留存技术主要是将流量数据按照类型(比如视频、音频、图片、文本、二进制文件等)存储到消息队列或者分布式文件系统中,之后便可以按照类型或文件夹抽取某一类的流量数据。现有技术存在的问题:当流量数据较小时,存储时磁盘寻道次数增加,导致存储速度变慢。其次,消息队列或分布式文件系统只能支持按某类型维度进行抽取,如果抽取流量数据时指定源ip和时间段或其他多个维度,则需要对所有留存的流量数据进行逐条对比,通过对比每条流量数据中的源ip、时间或其他维度来确定要抽取的流量数据,显然效率较低。
技术实现思路
1、本发明所要解决的技术问题是提供一种实时流量留存和批量抽取方法,可提高实时流量的存储速度和后续使用时批量抽取的效率,对于留存流量的快速提取分析有重要意义。
2、本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种实时流量留存和批量抽取方法,基于实时采集所获各待分析网络数据流在文件系统中各文件内的存储,根据各待分析网络数据流按预设网络数据流聚合规则划分下各聚合key分别与其所对应各时间标记信息对应组合构成的各个待分析键、以及各个待分析键分别所对应各待分析网络数据流在文件系统中存储地址构成的各个待分析值,按如下步骤a至步骤d,响应包含目标聚合key与目标时间段的目标抽取请求;
3、步骤a.判断各待分析键中是否存在与目标聚合key相同的聚合key、且该聚合key所对应各时间标记信息中存在位于目标时间段中的各时间标记信息的各个待分析键,是则获得各待分析键中与目标聚合key相同的聚合key、且该聚合key所对应位于目标时间段中的各时间标记信息的各个待分析键,并获得该各个待分析键分别所对应的待分析值,作为各个待选值,然后进入步骤b;否则关于目标抽取请求的响应为空;
4、步骤b.筛选各待选值中彼此不同的各待选值,作为各个非重复待选值,并进入步骤c;
5、步骤c.按存储地址升序或降序,针对各个非重复待选值分别所对应存储地址进行排序,并针对该排序中各组相邻、且连续的各存储地址分别进行合并,构成各个目标存储地址,然后进入步骤d;
6、步骤d.由文件系统中读取各目标存储地址中的全部待分析网络数据流,作为各个待选网络数据流,并获得各待选网络数据流分别对应的采集时间,进而获得其中采集时间位于目标时间段内的各个待选网络数据流,作为目标抽取请求的响应。
7、作为本发明的一种优选技术方案:执行步骤a之前,还包括如下操作:
8、操作,以目标时间段开始时间-目标时间段开始时间*5%的结果,作为新目标时间段开始时间,以目标时间段结束时间-目标时间段结束时间*5%的结果,作为新目标时间段结束时间,进而由新目标时间段开始时间、以及新目标时间段结束时间,构成新目标时间段;
9、然后步骤a中,判断各待分析键中是否存在与目标聚合key相同的聚合key、且该聚合key所对应各时间标记信息中存在位于新目标时间段中的各时间标记信息的各个待分析键,是则获得各待分析键中与目标聚合key相同的聚合key、且该聚合key所对应位于新目标时间段中的各时间标记信息的各个待分析键,并获得该各个待分析键分别所对应的待分析值,作为各个待选值,然后进入步骤b;否则关于目标抽取请求的响应为空。
10、作为本发明的一种优选技术方案:所述步骤a中,基于各待分析键按其时间标记信息升序的排序,依次遍历各待分析键,首先判断各待分析键中是否存在时间标记信息大于或等于新目标时间段开始时间的待分析键,是则获得各待分析键中第一个时间标记信息大于或等于新目标时间段开始时间的待分析键,并继续获得该待分析键后时间标记信息小于或等于新目标时间段结束时间的各个待分析键,进而获得该所获各待分析键分别对应的待分析值,作为各个待选值,然后进入步骤b;否则关于目标抽取请求的响应为空。
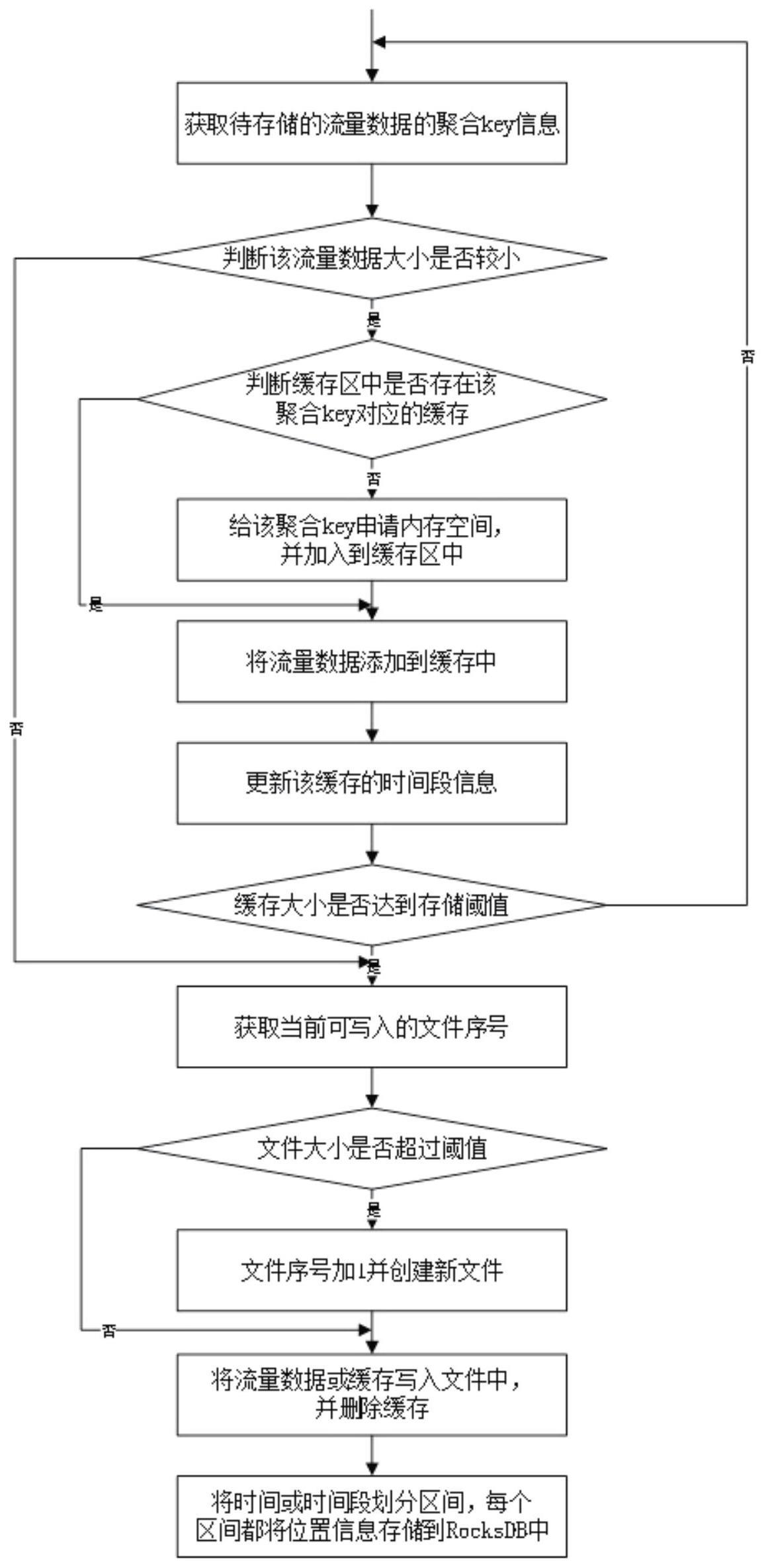
11、作为本发明的一种优选技术方案:实时分别针对各个采集所获待分析网络数据流,按如下步骤i至步骤vii,实现采集所获各待分析网络数据流在文件系统中各文件内的实时存储,并构建各待分析网络数据流按预设网络数据流聚合规则划分下各聚合key分别与其所对应各时间标记信息对应组合成的各个待分析键、以及各个待分析键分别所对应各待分析网络数据流在文件系统中存储地址构成的各个待分析值;
12、步骤i.按预设网络数据流聚合规则划分,获得待分析网络数据流所对应的聚合key,并判断该待分析网络数据流的数据量是否小于预设流量数据量阈值,是则进入步骤ii,否则进入步骤vii;
13、步骤ii.判断缓存区中是否存在该聚合key对应的缓存,是则直接进入步骤iii;否则创建该聚合key对应的缓存,然后进入步骤iii;
14、步骤iii.将该待分析网络数据流写入缓存区中该聚合key对应的缓存中,并根据该待分析网络数据流的采集时间,更新该聚合key对应缓存中待分析网络数据流的最小采集时间、最大采集时间,然后进入步骤iv;
15、步骤iv.判断缓存区中该聚合key所对应缓存中的数据量是否大于或等于预设缓存数据量阈值,是则按预设区间时间跨度值,针对该聚合key对应缓存中待分析网络数据流的最小采集时间至最大采集时间的跨度进行划分,获得该聚合key对应缓存中待分析网络数据流的各个时间区间,并以该各个时间区间中的开始时间作为各个时间标记信息,由该聚合key分别与各个时间标记信息对应组合构成各个待分析键,然后进入步骤v;否则针对该待分析网络数据流的处理结束;
16、步骤v.获得文件系统中标记为可写入的文件的存储地址,将该聚合key对应缓存中的各待分析网络数据流写入该存储地址的文件中,由该存储地址构成执行顺序相邻步骤iii中所获各个待分析键分别所对应的待分析值,然后删除缓存区中的该聚合key、以及其对应的缓存,并进入步骤vi;
17、步骤vi.判断执行顺序相邻步骤中所写入文件中的数据量是否大于或等于预设文件写入数据量阈值,是则更新该文件的标记为不可写入,然后创建新文件、并定义其标记为可写入,针对该待分析网络数据流的处理结束;否则保持该文件的标记为可写入,针对该待分析网络数据流的处理结束;
18、步骤vii.以该待分析网络数据流的采集时间作为时间标记信息,由该聚合key与该时间标记信息组合构成待分析键,并获得文件系统中标记为可写入的文件的存储地址,将该待分析网络数据流写入该存储地址的文件中,由该存储地址构成该待分析键对应的待分析值,然后返回步骤vi。
19、作为本发明的一种优选技术方案:所述步骤vi中,以文件系统中已存在文件的最大存储地址的下一存储地址,按预设文件最大存储数据量,创建新文件、并定义其标记为可写入。
20、作为本发明的一种优选技术方案:所述构成待分析值的存储地址包括以文件起始存储地址构成文件序号、存储地址偏移量、以及预设文件最大存储数据量。
21、本发明所述一种实时流量留存和批量抽取方法,采用以上技术方案与现有技术相比,具有以下技术效果:
22、本发明所设计一种实时流量留存和批量抽取方法,采用全新设计逻辑,针对网络数据流的留存、以及抽取两个环节,进行前后统一的逻辑调度关系设计,其中,针对留存,引入缓存中继、以及文件系统写入两个环节,获得各待分析网络数据流在文件系统中各文件内的存储,并构建各待分析网络数据流按预设网络数据流聚合规则划分下各聚合key分别与其所对应各时间标记信息对应组合成的各个待分析键、以及各个待分析键分别所对应各待分析网络数据流在文件系统中存储地址构成的各个待分析值,基于此进一步针对目标抽取请求,通过目标聚合key、目标时间段分别与各待分析键、以及对应待分析值的比较,实现对目标抽取请求的响应,如此提高实时流量的存储速度和后续使用时批量抽取的效率,对于留存流量的快速提取分析有重要意义。
- 还没有人留言评论。精彩留言会获得点赞!