基于纠偏编码协作缓存的基站休眠方法、系统、介质、宏基站与流程
本发明涉及无线通信的,特别是涉及一种基于纠偏编码协作缓存的基站休眠方法、系统、介质、宏基站。
背景技术:
1、随着通信技术与应用的飞速发展,“内容化”、“宽带化”与“移动化”已经成为网络发展的主旋律,人们对流量和内容的需求日渐强烈。根据可视化网络指数的预测,到2022年,全球互联网流量将相当于2005年全球互联网容量的127倍,无线和移动设备的流量将占到总ip流量的63%以上。随着网络需求的爆炸性增长,传统以主机为中心的网络架构将难以满足当前对网络服务质量的要求。为此,信息中心网络(information-centricnetworking,icn)作为一种新的网络架构被提出。在信息中心网络中,用户所需的内容信息往往被存储在网络边缘的存储器中。信息中心网络可实现内容与位置分离,网络内置缓存等功能,从而更好满足大规模网络内容分发、移动内容存取、网络流量均衡等需求。信息中心网络作为未来网络的一种重要形态,正引起各国研究者的关注。随着高清晰度视频、虚拟现实、自动驾驶和车联网等先进技术的迅速发展,移动网络中对延迟敏感和计算密集型数据服务的需求以前所未有的速度增长。移动网络应该提供更低的响应延迟和更高的传输速率服务,但这将带来额外的能源消耗。为了应对这些挑战,边缘缓存被认为是下一代通信中的一项重要技术,而边缘缓存正是信息中心网络的最重要的特征。
2、在上述信息中心网络概念的基础上,现有技术提出了将整个文件缓存到网络边缘的方案,用户请求数据并不需要像在传统无线网络一样沿着回程链路通过多跳映射向内容服务器去请求,而是通过根据所需的文件名向所属的基站请求文件,基站的存储器中如果缓存有该文件,则通过出接口将文件返回给用户。若没有则在存储器的兴趣转发表中挂出该文件名,并通过路由器基于转发信息表(forwarding information base,fib)中的信息和路由器中的自适应转发策略向宏基站(macro base station,mbs)转发兴趣包去请求(如果mbs中也没有相应的数据,则向位于核心网的内容生产者转发兴趣包)直到请求到所需文件为止。现有技术中也提出了将文件编码包分布式部署在网络边缘的方案,但是冗余的编码缓存包仍会占用额外的缓存空间,并且文件的编码缓存包数目无法随着用户请求密度的变化调整,简单的进行基站休眠也会影响对用户的服务质量。
3、进入5g时代,随着网络流量和用户设备数目的飞速增长,为了给用户提供良好的覆盖和接入服务质量,超密集网络部署已经成为常态。在超密集网络(ultra densedeployment,udns)中,虽然在网络边缘部署缓存是降低能量消耗的一种重要方法,但过于密集的基站部署会消耗额外的电能。虽然简单地关闭空闲基站可以改善基站能耗,但是此时无法充分利用空闲基站中的缓存内容,从而也会因为无法获得一部分边缘缓存增加系统能耗。
4、为了提高边缘缓存的性能,纠删编码缓存作为一种很有前途的技术在近年来被提出,并因其可恢复特性和良好的鲁棒性受到广泛关注。纠删编码与纠错码、检错码类似,均为线性分组码。纠删编码通过编码可以在造成有限冗余的前提下恢复丢失的数据。然而,只单独部署编码缓存包也会造成基站缓存空间的浪费。
技术实现思路
1、鉴于以上所述现有技术的缺点,本发明的目的在于提供一种基于纠偏编码协作缓存的基站休眠方法、系统、介质、宏基站,基于信息中心网络的文件存储架构和纠删编码技术实现基站休眠,极大地减少了系统能耗。
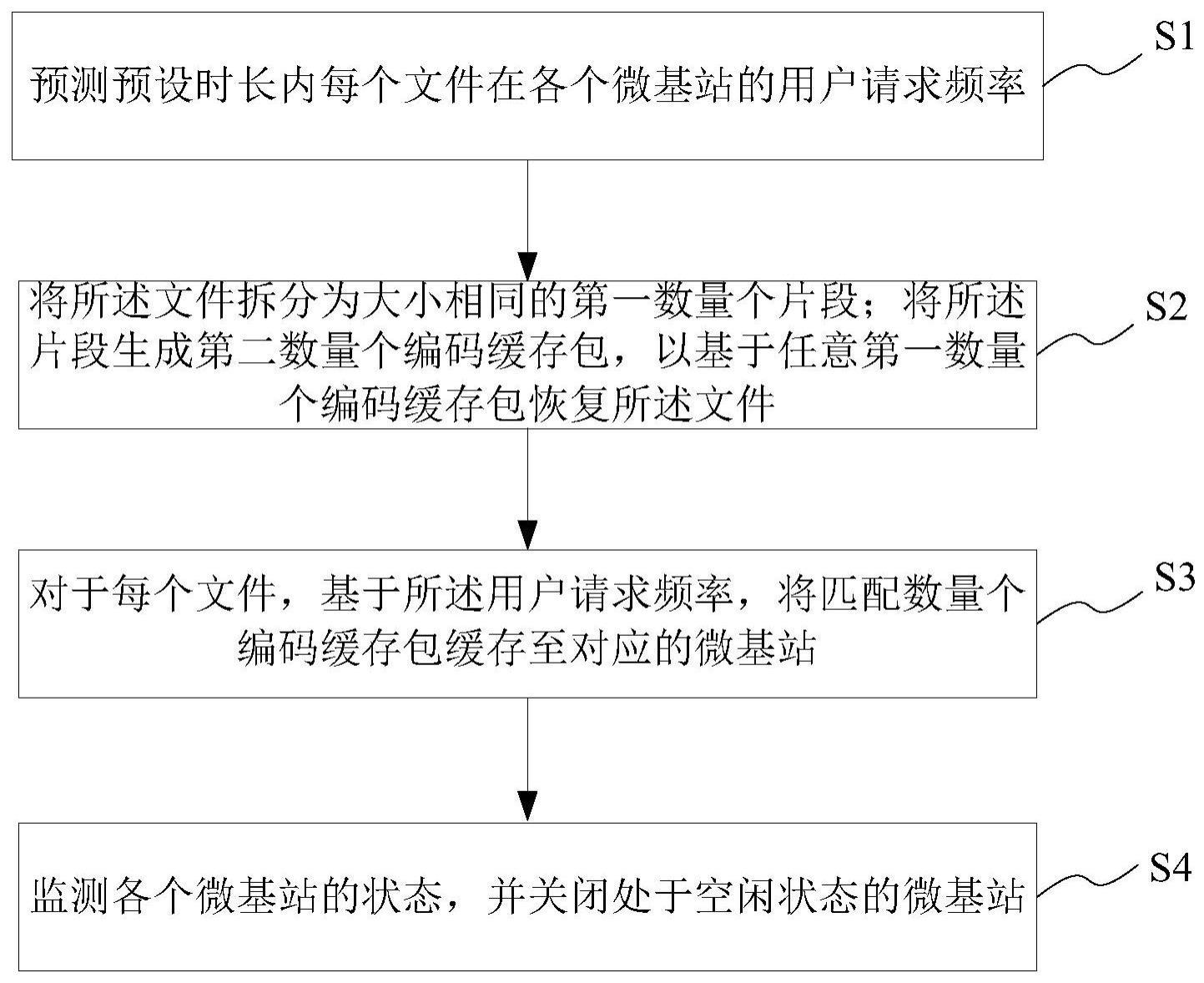
2、第一方面,本发明提供一种基于纠偏编码协作缓存的基站休眠方法,应用于宏基站,所述方法包括以下步骤:预测预设时长内每个文件在各个微基站的用户请求频率;将所述文件拆分为大小相同的第一数量个片段;将所述片段生成第二数量个编码缓存包,以基于任意第一数量个编码缓存包恢复所述文件;其中,所述第二数量大于所述第一数量;对于每个文件,基于所述用户请求频率,将匹配数量个编码缓存包缓存至对应的微基站;监测各个微基站的状态,并关闭处于空闲状态的微基站。
3、在第一方面的一种实现方式中,宏基站预测预设时长内每个文件在各个微基站的用户请求频率包括以下步骤:
4、获取每个文件的流行度;
5、根据预测文件f在各个微基站的所述用户请求频率,其中f表示文件总数,δ表示文件f的流行度的分布值。
6、在第一方面的一种实现方式中,所述编码缓存包采用基于所述片段生成的最大距离可分码。
7、在第一方面的一种实现方式中,所述匹配数量为系统总能耗最小时各个微基站需缓存的编码缓存包数量;所述系统总能耗为缓存能耗、协作传输能耗和沿后向链路请求的能耗的和。
8、在第一方面的一种实现方式中,其特征在于:各个微基站对应的编码缓存包的匹配数量通过以下任一方式获取:
9、基于深度强化学习的dqn网络获取;
10、基于粒子群算法获取。
11、第二方面,本发明提供一种基于纠偏编码协作缓存的基站休眠系统,应用于宏基站,所述系统包括预测模块、编码模块、缓存模块和监测模块;
12、所述预测模块用于预测预设时长内每个文件在各个微基站的用户请求频率;
13、所述编码模块用于将所述文件拆分为大小相同的第一数量个片段;将所述片段生成最大距离可分码格式的第二数量个编码缓存包,以基于任意第一数量个编码缓存包恢复所述文件;其中,所述第二数量大于所述第一数量;
14、所述缓存模块用于对于每个文件,基于所述用户请求频率,将匹配数量个编码缓存包缓存至对应的微基站;
15、所述监测模块用于监测各个微基站的状态,并关闭处于空闲状态的微基站。
16、第三方面,本发明提供一种存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述的基于纠偏编码协作缓存的基站休眠方法。
17、第四方面,本发明提供一种宏基站,包括:处理器及存储器;
18、所述存储器用于存储计算机程序;
19、所述处理器用于执行所述存储器存储的计算机程序,以使所述宏基站执行上述的基于纠偏编码协作缓存的基站休眠方法。
20、第五方面,本发明提供一种基于纠偏编码协作缓存的基站休眠系统,包括上述的宏基站和多个微基站;
21、当用户向某一微基站请求某一文件时,所述微基站在缓存中查找所述文件的编码缓存包,所述编码缓存包的数量为n;
22、当n大于等于第一数量时,所述微基站将所述编码缓存包提供至所述用户,以使所述用户基于所述编码缓存包恢复所述文件;
23、当所述编码缓存包的数量小于所述第一数量时,所述用户向其他微基站请求编码缓存包,直至请求到的编码缓存包的数量与n的和等于所述第一数量,以使所述用户基于请求到的所有编码缓存包恢复所述文件;
24、当向所有微基站请求的编码缓存包的数量小于所述第一数量时,所述用户通过所述微基站、所述宏基站向内容服务器请求编码缓存包,直至请求到的编码缓存包的数量与n的和等于所述第一数量,以使所述用户基于请求到的所有编码缓存包恢复所述文件。
25、如上所述,本发明的基于纠偏编码协作缓存的基站休眠方法、系统、介质、宏基站,具有以下有益效果:
26、(1)基于信息中心网络的文件存储架构和纠删编码技术实现基站休眠,极大地减少了系统能耗;
27、(2)通过在微基站侧部署编码缓存包,即使关闭部分空闲微基站也可以依靠在活跃基站中存储的编码缓存包将完整内容复原出来,有效解决简单关闭微基站造成的被关闭微基站内的文件不能被请求的问题,同时可以减少编码缓存带来的缓存冗余;
28、(3)通过预测文件流行度以及各个基站的用户请求个数,优化每个微基站的编码缓存包个数以及制定相应的基站休眠策略,从而极大地减少微基站能耗。
- 还没有人留言评论。精彩留言会获得点赞!