基于深度强化学习的V2V通信多车辆任务卸载方法与流程
:本发明涉及v2v通信的多车辆任务卸载领域,特别涉及一种基于深度强化学习的v2v通信多车辆任务卸载方法。
背景技术
0、
背景技术:
1、随着车联网的快速发展,传统的mec技术已经无法满足任务卸载的需求,特别是在自动驾驶等车联网应用,对任务卸载提出了低时延高可靠性的需求。任务卸载方向从mec逐渐转向了v2v。
2、车辆对车辆(v2v)通信是车辆之间在有效的通信范围内直接进行信息的交互,能够极大的减轻基站的负担,满足车联网应用低时延高可靠性的需求,同时v2v也极大的提高了周边空闲计算资源的资源利用率。为了满足v2v通信系统低延迟、高可靠性的通信要求,有必要研究并提出更合理有效的任务卸载和增强方案。
3、传统的v2v通信任务卸载算法没有考虑到车联网动态变化的特性,但是由于车辆的快速移动会导致网络拓扑不断发生变化,交通的不可预测性更是v2v通信技术的一大难题,不考虑实际车联网场景的动态变化过程,就不能优化长期的系统性能。v2v通信对时延和可靠性提出了更为严苛的要求,但是大部分v2v通信任务卸载算法无法权衡好通信时延和功耗两者的关系。近期的一项研究考虑了将深度强化学习算法与车联网的动态环境相结合,但延迟和可靠性的优化有待提高。特别是,仍然有许多计算资源没有得到利用,造成了资源的巨大浪费。
技术实现思路
0、
技术实现要素:
1、本发明所要解决的技术问题是,在存在中继车辆的情况下面向v2v通信的任务卸载方法,该方法能够在保证任务卸载成功率的同时,对于传输时延与功耗之间的权衡,也有着更好的性能。
2、本发明是通过如下技术方案实现的:
3、一种基于深度强化学习的v2v通信多车辆任务卸载方法,该方法包括以下步骤:
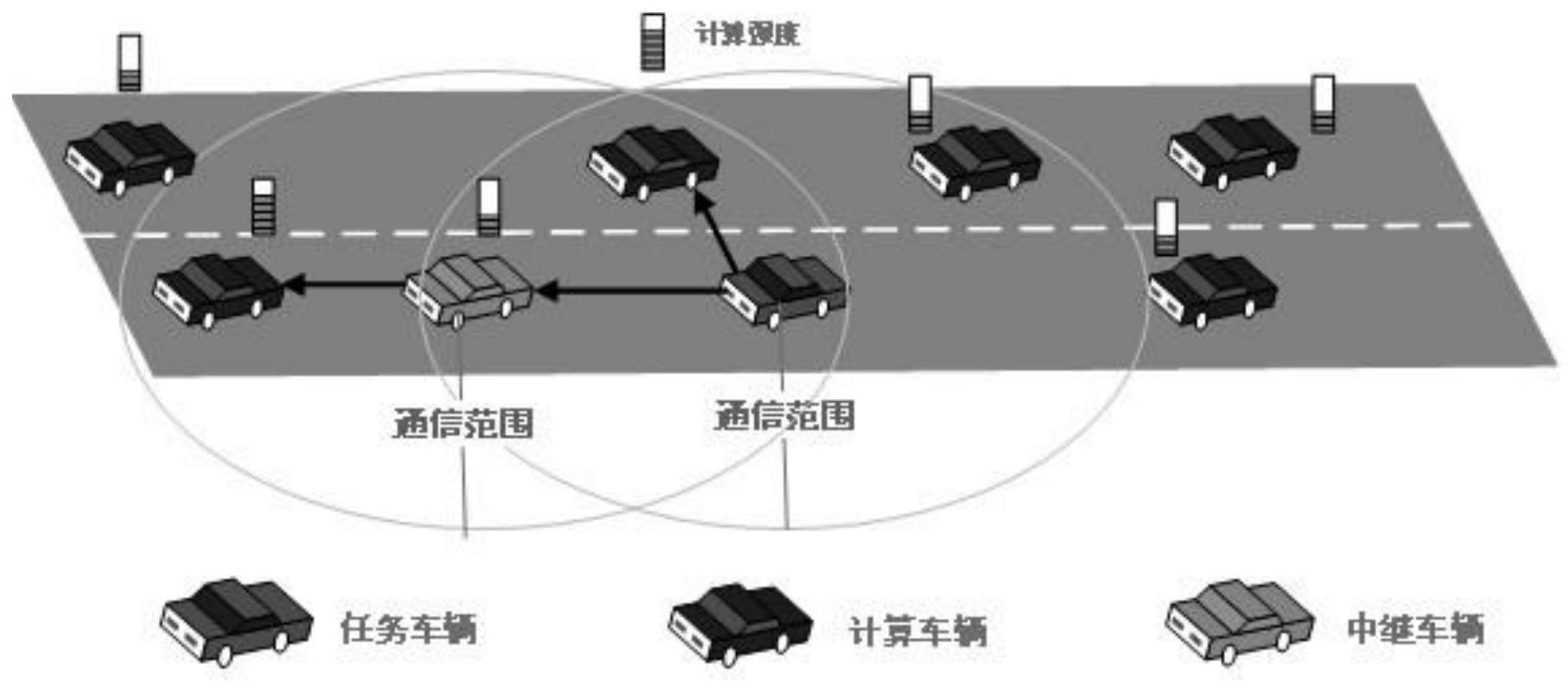
4、(1)v2v的多车辆任务卸载可以将任务车辆hv的计算任务卸载给周边的多辆具有计算资源的远车rv,同时可以利用中继车辆rev进行多跳来传输任务;
5、(2)分别计算得到单跳v2v任务卸载的传输时延和利用中继车辆的多跳v2v任务卸载的传输时延;
6、(3)计算利用中继车辆的多跳v2v任务卸载的传输中断概率;
7、(4)根据步骤(2)计算得到的传输时延以及步骤(3)得到的传输中断概率,在保证任务卸载传输成功率的同时,对任务车辆卸载过程的功率和传输时延进行优化;
8、(5)根据步骤(4)的优化目标,运用深度强化学习ddpg算法解决优化问题。
9、其中,所述步骤(1)是指在每个时刻任务车辆都有一个大小为xt的任务通过算法计算拆分为多个子任务,通过pc5接口卸载给一辆或者多辆计算车辆计算,也可以通过中继车辆卸载给通信范围外的计算车辆。
10、步骤(2)中,任务车辆可以根据任务量和计算车辆的计算资源和信道状态,计算得到单跳v2v任务卸载的传输时延和利用中继车辆的多跳v2v任务卸载的传输时延。
11、不选中中继车辆的单跳v2v任务卸载,传输时延表示为:
12、
13、其中,
14、xt表示在t时刻生成的任务数据大小;
15、yt表示卸载任务后反馈结果的数据量大小;
16、表示hv和rvn的上行传输速率;
17、表示hv和rvn的下行传输速率;
18、ωt表示rv的计算强度;
19、ft,n表示t时段处理hv任务所分配的cpu频率,其中ft,n∈[0,fn];
20、fn是rvn的最大cpu频率;
21、具体的hv和rvn的上行传输速率和下行传输速率表示如下:
22、
23、
24、其中,是每个时刻分配的传输功率,w是信道带宽,σ2是噪声功率,p是rvn反馈结果所给定的固定发射功率,无线信道状态表示的是hv到rvn之间在时刻t的状态,与是任务卸载给rvn时的干扰。
25、任务车辆通过中继多跳传输到rvn的任务卸载传输时延表示为:
26、
27、其中,
28、dup(t,z)是第z跳下的上行无线信道传输时延,是传输的任务量大小比上第z跳的上行传输速率表示如下:
29、
30、ddown(t,e)是第e跳下的下行无线信道传输时延,是传输的任务量大小比上第e跳的上行传输速率表示如下:
31、
32、dcom(t,n)是任务传输到计算车辆rv时,在计算车辆rv上的计算时延,表示如下:
33、
34、步骤(3)中,通过中继车辆的多跳进行任务传输存在中断概率,车辆获取多跳链路之间的距离计算得到端对端的中断概率,方法如下:
35、(4.1)对于通过中继车辆rev的多跳v2v任务卸载,车辆到车辆中断概率定义为车辆到车辆信噪比低于设置的限定值即信噪比阈值的概率,车辆到车辆的中断概率表示为:
36、
37、(4.2)在v2v通道中接收到的信号幅度遵循威布尔分布,威布尔衰落下接收信噪比fsnr(a)表示为:
38、
39、其中c代表的是威布尔衰落参数,γ表示的是伽马函数,snreq是平均信噪比,表示如下:
40、
41、(4.3)根据(4.1)和(4.2)可得到车辆到车辆的中断概率表示为:
42、
43、(4.3)端对端的中断概率poutsum表示为:
44、
45、其中,
46、z表示通信过程中有z条链路;
47、li表示第i跳链路两端之间的距离;
48、pout(li)是通信过程中第i跳的中断概率。
49、步骤(4)中,在每个时刻,为了考虑时延与功耗的权衡,提出以最小化当前时刻卸载过程的整体消耗的优化问题:
50、
51、同时满足约束条件:
52、dmax(t,n)≤dth
53、
54、ζ1,ζ1∈[0,1],ζ1+ζ1=1
55、其中,
56、dth表示时延的阈值约束;
57、pmax表示功耗的阈值约束;
58、dmax(t,n)表示选择多车时最大的传输时延;
59、ζ1,ζ2分别表示时延与功耗的权重。
60、在连续状态下分配传输功率中,基于ddpg的算法在车载网络中共同分配任务数据量和传输功率,步骤(5)的ddpg任务卸载算法如下:
61、(5.1)在ddpg算法中,智能体能够通过与环境相互作用生成了一个信息集(s(t),a(t),r(s(t),a(t)),s(t+1)),再存储信息到经验回放缓冲区,然后从缓冲区随机抽取一小部分样本来训练神经网络,这样可以降低样本间的相关性,并且提高学习效率。因此定义了网络模型中的状态空间,动作空间和奖励函数。
62、在每次的学习过程中,智能体能够从当前环境中获取状态输入,ddpg网络模型中的状态空间定义为:
63、
64、e(t)={d(t),υ(t),z(t),h(t),l(t)}
65、其中,
66、d(t)表示缓冲区前端需要卸载的任务数据量的大小,
67、υ(t)表示任务车辆即主车周边具有计算资源的车辆集合,z(t)表示周边车辆能够分配去进行任务卸载的计算资源大小,
68、h(t)表示无线信道状态,
69、l(t)表示车辆之间距离大小,
70、将之前学习到的前φ次状态信息作为当前的状态信息。
71、智能体的动作是通过车载终端设备分配任务数据量大小和传输功率大小,动作空间定义为:
72、
73、其中代表着可以分配的传输功率的大小取值范围,代表着被选取的具有计算资源车辆的序号。
74、同时任务数据量的大小需要满足:
75、
76、当环境执行动作,智能体得到相应的奖励或者惩罚,在这里的车辆卸载研究中,将目标函数中ζ2记作α,则ζ1记作1-α,奖励函数定义为:
77、
78、其中α表示传输功率的权重,表示任务卸载时延大于时延的阈值,得到负奖励,表示任务卸载时延在时延限定范围内,得到正奖励。
79、同时总奖励需要满足:
80、
81、(5.2)为了学习分配策略,需要训练基于ddpg的算法,具体算法流程如下:
82、(5.2.1)初始化策略网络、动作网络和缓冲区,并为动作的学习初始化一个随机过程ω;
83、(5.2.2)对于学习更新的每个时段,观察v2v任务卸载初始的环境状态s(1);
84、(5.2.3)再对于每个时段的每一帧生成一个动作a(t)=μ(s(t)|θμ)+ω(t)来决策当前选中车分配的任务量大小与传输功率;
85、(5.2.4)执行动作a(t),然后得到相应的奖励r(s(t),a(t)),从环境中更新观察到新的状态s(t+1);
86、(5.2.5)将信息集(s(t),a(t),r(s(t),a(t)),s(t+1)),存储到经验回放缓冲区;
87、(5.2.6)从经验回放缓冲区随机抽取一小部分样本来更新策略网络:
88、
89、其中y(i)表示目标值,即y(i)=r(s(i),a(i))+γq′(s(i+1),μ′(s(i+1)θμ′)|θq′),q表示评价网络,q′表示目标评价网络,μ′表示目标策略网络。θq,θq′,θμ′分别表示对应网络的参数;
90、(5.2.7)在评价网络的协同下,策略网络使用策略梯度来更新参数:
91、
92、(5.2.8)目标网络使用较小的常数τ来软更新参数:
93、θq′=τθq+(1-τ)θq′
94、θμ′=τθμ+(1-τ)θμ。
95、本发明采用以上技术方案与现有技术相比,具有以下技术效果:与其他权衡通信时延和功耗两者的任务卸载方案相比,该算法能够在保证任务卸载成功率的同时,对于传输时延与功耗之间的权衡,也有着更好的性能。
- 还没有人留言评论。精彩留言会获得点赞!