基于神经辐射场的超低带宽视频通话传输系统和方法
本发明涉及一种视频通话传输系统,具体地,涉及一种基于神经辐射场的超低带宽视频通话传输系统和方法。
背景技术:
1、三维数字人重建模型,尤其是数字人脸重建模型,是当下计算机视觉和计算机图形学正火热的研究问题。三维数字人脸对于增强现实ar以及虚拟现实vr等远程呈现应用以及视频编辑(如电影工业中的视觉配音)都是必不可少的。这些应用需要一个对于人脸外貌真实可信的重建,并希望重建模型能够改变视角方向和头部位姿(常见于vr中)以及能够改变表情(例如视觉配音)。以往的人脸重建模型通过显式的几何与材质特征(如反照率albedo与反射率reflectance)来表示人脸(头),但这种方法是十分有难度的,这是因为人的皮肤还会有一些例如次表面散射效应,且眼睛是高度反光的以及头发的几何特征十分复杂且有着很精细的细节,使得这种显示的表示方法效果较差。尽管借助一些多镜头多视角的摄像棚可以比较容易地解决对皮肤表面高质量几何特征的显式重建,但头发部分却通常只是通过检索和细化发型来近似,给人一种很不真实的视觉效果。
2、与此同时,时下对于人像视频通话和视频传输的使用和研究也受到很多人的关注。近几年,人们的生活方式越来越由线下转到线上,线上学习,线上办公,线上娱乐等等,各种各样的云端服务层出不穷,而在这其中视频通话和传输占有很重要的地位:学生的教学转为线上,为了不降低教学质量,需要开启线上多人视频会议来帮助学生更好地学习,线上办公汇报亦是如此,除此之外,疫情所导致的封控和隔离,也只有视频通话能够构建我们与亲人之间“面对面”的沟通桥梁;再如线上娱乐如直播,短视频等,对于人像视频通话和传输也有着大量的需求,其中一些虚拟形象的直播(主播将自己的面部以虚拟形象展现在观众面前,可粗略捕捉其面部表情),则对于视频通话有了更高的要求。
3、更进一步,无论是人像视频通话还是视频传输,都有一个需要考虑的重要问题,即在传输时视频所需要的带宽。另一方面在一些比较特殊的视频传输场景下,如一些带宽极度受到限制的场景,空地通信、水下通信、极地科考、地月通信和空间站通信等等,以及人数足够多的多人超大型线上会议,有着对于足够低带宽的需求。
4、降低视频带宽最为主要的方法就是视频压缩,多年以来人们设计出许多不同的方法来压缩视频,已经有很长的历史,从首次出现帧间压缩的方法,到dct图像压缩,再到首个视频压缩协议h.120,之后首个在商业上成功的数字视频编码标准h.261,再到2020年发布的h.266/vcc标准;各种方法基于视频信息存在时间冗余,空间冗余,编码冗余和视觉冗余的特性,通过去除冗余来实现视频压缩以降低视频传输所需的带宽。这些不断精进的视频压缩方法使得更加高清的视频通话和传输成为了可能,但其在面对上述的特殊情况或许也会捉襟见肘。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种基于神经辐射场的超低带宽视频通话传输系统和方法。
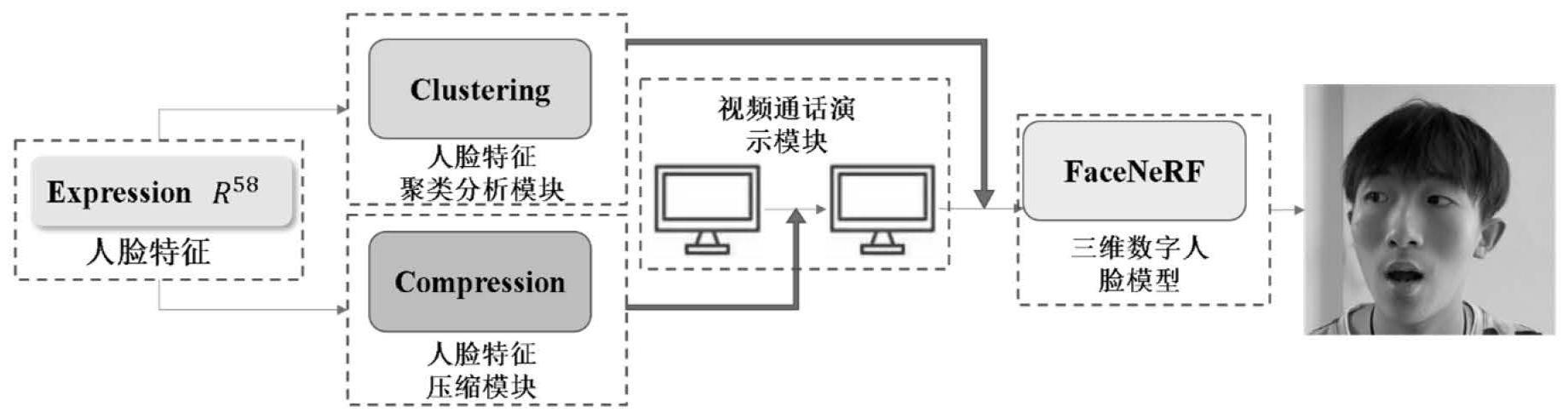
2、根据本发明的一个方面,提供一种基于神经辐射场的超低带宽视频通话传输系统,包括:
3、三维数字人脸重建模块,所述三维数字人脸重建模型能够从输入的人脸图像中提取人脸表情特征;并能够以人脸表情特征为输入隐式地控制人脸表情,实现三维重建;
4、视频通话演示模块,所述视频通话演示模块展示实时的视频通话过程,其包括服务器发送端和客户接收端,所述服务器发送端利用所述三维数字人脸重建模块采集的人脸表情特征传输至客户接收端;
5、人脸特征压缩模块,所述人脸特征压缩模块与所述服务器发送端连接,将传输的人脸表情特征进行压缩;
6、人脸特征聚类分析模块,所述人脸特征聚类分析模块与所述客户接收端连接,对接收的经所述人脸特征压缩模块压缩后的人脸表情特征进行聚类分析、利用所述三维数字人脸重建模块进行采样预渲染和结果替代,实现视频通话的实时性。
7、优选地,所述三维数字人脸重建模块具有将输入的人脸图像与人脸表情特征一一对应的特质,实现人脸表情特征替代人脸图像传输,用于降低带宽;
8、所述人脸特征压缩模块对传输的人脸表情特征进行再次用于降低传输带宽的压缩;
9、所述人脸特征聚类分析模块对所述客户接收端对接收到的人脸表情特征进行渲染再呈现的过程实现实时性。
10、优选地,所述三维数字人脸重建模型,包括:
11、面部追踪单元,所述面部追踪单元估计给定人脸图像中的人脸位姿和人脸表情特征;
12、提取背景单元,所述提取背景单元解耦给定人脸图像中的人脸与背景,分别得到目标人脸与背景;
13、动态神经辐射场单元,所述动态神经辐射场单元动态隐式地表示以所述目标人脸为主体的场景;
14、人脸立体渲染单元,所述人脸立体渲染单元对所述动态神经辐射场单元表示的目标人脸为主体的场景渲染生成人脸图像;
15、其中,所述面部追踪单元提取的所述人脸位姿和人脸表情特征作为所述动态神经辐射场单元的部分输入;
16、所述提取背景单元提取的所述目标人脸和背景,用于所述人脸立体渲染单元在训练阶段对损失的计算和测试阶段人脸图像的生成。
17、优选地,所述动态神经辐射场单元将所述面部追踪单元获得的所述人脸位姿p、人脸表情特征δ以及可学习隐码γ共同作为条件参数进行限制,使用一个多层感知机mlp表示人脸的动态神经辐射场单元dθ;
18、其中,所述多层感知机mlp,其输入包括五类参数,分别为:一个由(x,y,z)组成的三维空间中某点的位置p、一个由(θ,φ)组成二维的视角方向人头位姿p、人脸表情特征δ以及可学习隐码γ;其输出为三维空间中该点对应的体素密度σ,以及该点与视角方向相关的辐射颜色rgb,即dθ(x,y,z,θ,φ;p,δ,γ)=(rgb,σ)。
19、优选地,所述辐射颜色rgb和体素密度σ为所述动态神经辐射场单元dθ的网络结果,其获取过程,包括:
20、将所述面部追踪单元获取的人脸表情特征δ和人脸位姿p经过嵌入网络和注意网络处理,得到处理结果;
21、将所述处理结果结合所述隐码获得编码后的特征;
22、将所述编码后的特征输入到8个依序排列的256通道数的全连接层网络;
23、将三维空间中某点的位置p作为第五个256通道数的全连接层网络的输入;
24、所有全连接层网络皆使用relu作为激活函数,最后一个全连接层网络输出体素密度σ和一个256维的特征向量;将所述256维的特征向量与所述视角方向结合,输入到一个128通道的全连接层输出辐射颜色rgb像素值。
25、优选地,所述嵌入网络和注意网络,分别对人脸表情特征进行加窗嵌入和平滑处理;所述可学习隐码γ补偿调和在所述面部追踪单元中人脸表情特征和人脸位姿中的误差。
26、优选地,所述人脸立体渲染单元模拟相机射线穿过每帧人脸图像的每个像素的采样过程,对经过所述动态神经辐射场单元得到的体素密度σ和辐射颜色rgb进行累积,得到最终图像像素点值g,包括:
27、在已知一条相机射线相机中心为c,视角方向为且最近边界和最远边界分别为znear和zfar的情况下,所估计的像素点值c表示为:
28、其中rgbθ(·)和σθ(·)是通过所述的动态神经辐射场模型dθ在相机射线上对应一点以头部位姿p,表情特征δ和可学习隐码γ计算得到的,t(t)代表了沿相机射线从znear到t的累积透射率,表示为:
29、优选地,所述的人脸特征聚类分析模块,包括:
30、人脸特征采集单元,所述人脸特征采集单元对多个不同主体分别进行人脸视频采集,并获取所有人脸表情特征整合到一起;
31、聚类分析单元,所述聚类分析单元对所述人脸特征采集单元得到的人脸表情特征进行k-means聚类分析,计算每类人脸表情特征点到其聚类中心的距离,并求和对比,最终确定最佳的聚类数目;
32、采样和预渲染单元,所述采样和预渲染单元对所述聚类分析后的每一类人脸特征点按比例进行采样,并通过三维数字人脸重建模型对采样点进行预渲染,得到渲染结果存储下来;
33、结果替代单元,将所述传输来的目标人脸特征与聚类采样得到的人脸特征进行比较,选取距离最近的特征的预渲染结果,近似地代替当前传输来的人脸特征的渲染结果。
34、优选地,所述的人脸特征压缩模块,包括:
35、残差编码压缩单元,所述残差编码压缩单元对人脸表情特征进行残差编码压缩;
36、dct编码压缩单元,所述dct编码压缩单元对人脸表情特征进行dct编码压缩;
37、所述视频通话演示模块中,所述服务器发送端通过python中socket库构建,与客户接收端相连,用于向客户接收端发送目标人脸表情特征;所述客户接收端通过python中socket库构建,与所述服务器发送端相连,用于接收传输来的人脸表情特征,并进行渲染结果展示。
38、根据本发明的第二个方面,提供一种基于神经辐射场的超低带宽视频通话传输方法,采用上述的基于神经辐射场的超低带宽视频通话传输系统,包括:
39、提取图像中的人脸表情特征;
40、对所述人脸表情特征进行压缩;
41、将压缩后的人脸表情特征从服务器发送端发送至客户接收端;
42、在所述客户接收端对接收到的人脸特征进行聚类分析和采样预渲染结果替代实现视频通话的实时性。
43、与现有技术相比,本发明实施例具有如下至少一种有益效果:
44、本发明实施例提供一种基于神经辐射场的超低带宽视频通话系统和方法,通过三维重建模型中实现人脸重建模型,并根据模型将人脸表情特征与人脸图像一一对应的特性,由原本的人脸视频的传输转为人脸特征的传输,并通过聚类分析和特征压缩,最终实现了超低带宽近乎实时的人脸视频通话传输效果;
45、本发明实施例提供的动态神经辐射场,通过隐式的方式对以人脸为主体的三维场景进行表示,而非采用显式的重建方式,能够对场景的光照以及其他细节有更好的重建效果,同时具有无限分辨率渲染的有点;在原始神经辐射场的基础上,使用人脸表情特征和人脸位姿作为条件输入,从而实现了动态地控制重建人脸表情和人脸朝向,最终实现了高拟真度的人脸重建;
46、本发明实施例提供的人脸特征压缩模块,考虑到了向量形式的人脸表情特征其表示仍有冗余,采用了无损熵编码和残差量化编码等压缩方式对用于传输的人脸表情特征进行进一步的压缩,从而进一步降低了传输的带宽;
47、本发明实施例提供的人脸特征聚类分析模块,首次考虑到人脸表情在通话时随时间分布的聚类特性,并以此为依据,构建视频通话人脸表情特征数据库,进一步地通过采样和预渲染结果替代的方式,最终满足了实时视频通话传输的需求。
- 还没有人留言评论。精彩留言会获得点赞!