基于交互式持续学习的360度全景监控自动巡航方法与流程
1.本发明属于自动巡航技术领域,尤其涉及一种基于交互式持续学习的360度全景监控自动巡航方法。
背景技术:
2.社区是区域性的社会,具有一定的边界和范围,目前城市人口密集,使得城市的社区治理变得非常复杂,伴随着城市的发展,城市的各种生活系统变得非常复杂,尤其是信息化时代,社区的治理伴随着治安防范,社区诈骗,网络纠纷。
3.监控系统往往由图像采集、传输,控制、显示等设备和控制软件构成,由于其能够实时记录和监视现场发生的事件,在城市的大街小巷布满了摄像头系统,从而为维护城市社区的长治久安奠定了基础。
4.360度全景监控目前应用最广泛的是车载系统中自动泊车系统,而全景监控系统应用与智慧安防目前正在逐渐增多,360度全景监控摄像头是能够完全无死角的监控大面积区域,可以取代多台普通的摄像机实现无缝监控。而且360度全景监控的智能化发展也正在进行中,通过在360度视频监控中嵌入智能识别算法,能够对画面中的行人,车辆等行为进行监控、检测和识别,在发生治安问题的时候能够及时发出预警。
5.但是目前的智能化监控设备往往不能实现智能化的自动巡航,在实际应用过程中存在诸多问题,如在出现树叶落下的时候误判为小动物运动,并且在全景监控过程中只能展示单一视口,在非展示视口的情况下,死角范围内发生的事件不可见。
技术实现要素:
6.针对现有技术存在的问题,本发明设计提供了一种基于交互式持续学习的360度全景监控自动巡航方法。
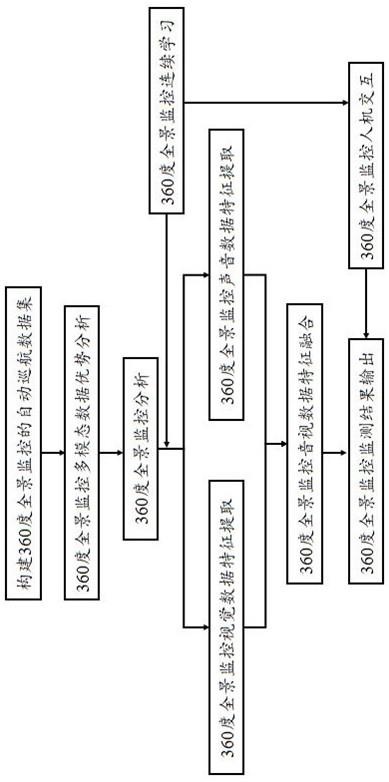
7.为实现上述目的,本发明实现自动巡航的具体过程为:(1)采用world360和asod60k数据集作为360度全景监控的自动巡航数据集;(2)将自动巡航数据集中的视频采用等距投影的方式得到erp图片,通过在erp图片的在不同位置施加不同类型的卷积核提取360度全景监控的视觉数据特征;(3)截取自动巡航初始数据集中视频的声音片段作为音频信号,在音频信号之间采用hanning窗口的方式来加权当前帧的音频信号,再使用一维全卷积网络提取360度全景监控的声音数据特征;(4)将步骤(2)提取的视觉数据特征映射为高维向量,采用音视高维度特征之间相似性度量的方式,将视觉数据特征中与声音数据特征具有高度一致性的特征提取出来,从而加权视觉特征对应区域,得到融合后的音视特征;(5)通过融合后的特征生成视点数据,并基于视点数据生成视口;(6)采用多路监控显示的方式,即每个视点存在一个监控路径,对每个监控路径以小窗的形式显示在显示屏的周围区域,通过不断更新显示内容来显示视点检测的结果,其
中选择视点相应值最高的作为主窗口显示,当出现另一个高视点置信度的时候将会切换到另一个视点继续追踪;在监控指挥权落到管理人员身上的时候,自动切换到管理人员视口,此时,收集鼠标点击位置和方向键,并通过投影的方式显示管理人员视口;(7)采用连续学习的方式持续的更新数据和更新模型,应对不同复杂场景下的360度全景监控场景;(8)使用自动巡航数据集中的训练集作为网络的拟合数据,先将全景视频转化为等距投影的2d图片,并将声音保存为mp3的格式,将音视数据输入到整个网络中,并计算损失函数,损失包含基于平滑后的损失和基于视点坐标的损失两部分;(9)将全景视频数据转为erp数据和mp3数据,并输入到网络中,生成视点数据,并生成视口,在人工点击后,将人工点击的位置作为数据输入到本地数据集,将作为连续学习的训练集,提升网络的性能。
8.作为本发明的进一步技术方案,步骤(2)的具体过程为:在原有卷积核的基础上引入极坐标,假设采用普通卷积核,则相应视觉数据特征的计算方式为:在erp图片中将普通卷积核进行变换得到相应的erp位置计算为,其中,代表不同卷积核提取的特征,(x,y)代表像素的位置坐标,代表像素的极坐标位置,代表普通的卷积核,提取视觉数据特征采用的卷积核,代表卷积核对应erp上的卷积区域。
9.作为本发明的进一步技术方案,步骤(3)得到的声音数据特征为:其中,代表m层1维卷积,其初始化权重来自于soundnet网络,代表将音频信号通过傅里叶变换并加hanning窗转化为声谱图。
10.作为本发明的进一步技术方案,步骤(4)的具体过程为:其中,代表矩阵间的相似性度量,代表将矩阵进行特征尺寸转化操作,和代表将特征转化到高维度特征,得到融合后的音视特征为:代表将特征转化到高维度特征,得到融合后的音视特征为:为融合后的音视特征,代表视觉数据特征,代表将特征转化到高维度特征,代表softmax函数归一化,代表将矩阵进行特征尺寸转化操作。
11.作为本发明的进一步技术方案,步骤(5)视点的生成采用两种方式,一种为生成视点坐标位置,另一种为生成视点的平滑后的区域:
其中,代表将位置的坐标值进行高斯平滑,从而生成视点区域,代表生成的视点坐标位置,代表网络输出,为融合后的音视特征,为卷积层操作;得到视点位置后,将视点逆投影到球面上,然后二次投影到视口fov上:其中,代表球面投影,代表投影为视口。
12.与现有技术相比,本发明的有益效果是:通过多模态信息自动生成监控内容,相对于单一源头的监控来说更加鲁棒,而且本发明的技术方案更加智能化,能够将监控内容自动展示,并能时刻调整监控内容,在调整监控的基础上,模型能够实现持续学习,来提升模型的性能,相对于传统模型来说,由于模型具有自进化的能力,能够克服现实场景中复杂情况。
附图说明
13.图1为本发明实现自动巡航的流程框架示意图。
14.图2为本发明实现自动巡航的网络结构图。
具体实施方式
15.下面结合附图并通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
16.实施例:本实施例采用如图1所示的流程和图2所示的网络实现自动巡航,具体包括如下步骤:(1)构建360度全景监控的自动巡航数据集采用360度视点预测数据集作为初始数据集,360度全景视点数据集在标注的过程中,收集感兴趣区域作为标注,基于感兴趣区域能够实现360度全景监控视口的自动生成,本实施例采用数据集world360和asod60k数据集作为自动巡航数据集;(2)360度全景监控多模态数据优势分析目前,对于多模态数据的处理越来越多,主要原因是相对于单一模态数据,多模态数据能够蕴含更多的数据信息,通过多模态数据协同处理,能够克服单一模态中,某个模态失效导致的错误问题,同时,多模态信息能够将模型的性能提升到最大化,因为模态之间数据协同处理能够将每个模态中错误的信息过滤掉,因此,本实施例在360度全景监控中采用多模态的方式;(3)360度全景监控分析目前360度全景监控相关的研究较少,主要原因是360度全景监控的摄像头在成像的时候需要将不同角度的拍摄内容图片组合到一张图中,而在组合的过程中,摄像头需要组合成为球形的内容,然而,目前的深度学习模型为基于2d图像的输入,导致无法直接将3d
的球形内容输入到网络中,需要预先处理好深度学习网络要求的数据形式才能加载预训练模型;(4)360度全景监控视觉数据特征提取为提取视觉特征数据,同时节省网络运行所需要的运行成本,本实施例将全景视频采用等距投影的方式生成erp图片,在erp图片的不同位置具有不同的失真程度基础上,在不同位置施加不同类型的卷积核,不同位置的卷积核主要通过标准卷积核变换的方式,即在原有卷积核的基础上引入极坐标,假设采用普通卷积核,则相应视觉数据特征的计算方式为:但是,erp图片中,每个位置的像素并不是均匀分布,因此,本实施例将普通卷积核进行变换得到而相应的erp位置计算为,其中,代表不同卷积核提取的特征,(x,y)代表像素的位置坐标,代表像素的极坐标位置,代表普通的卷积核,代表本实施例中采用的卷积核,代表卷积核对应erp上的卷积区域;(5)360度全景监控声音数据特征提取对于全景监控声音的处理,由于传统的预处理过程将会耗费大量的时间,本实施例摒弃了传统将声音信号转化为频谱图的方式,采用将声音数据直接输入声音波形,然后使用1d全卷积网络的方式,其中为了将音频信号和视频信号对应,采用将音频信号截取为声音片段,音频片段并不是孤立的信息,而是音频为持续一段时间的信号,在音频信号之间采用hanning窗口()的方式来加权当前帧的音频信号,从而保证音频充分被利用,同时为加快音频信号处理网络的速度,采用加载预训练模型的方式来初始化网络初始权重,并将soundnet网络的模型作为音频高层语义特征提取模型:其中,代表m层1维卷积,其初始化权重来自于soundnet网络,代表输出的声音数据特征,代表将音频信号通过傅里叶变换并加hanning窗转化为声谱图;(6) 360度全景监控音视数据特征融合为提取音视上下文信息,将视觉数据特征映射为高维向量,采用音视高维度特征之间相似性度量的方式,将视觉数据特征中与具有高度一致性的特征提取出来,从而加权视觉特征对应区域,通过这种方式能够保证音视融合后的特征起到两方面的作用,一方面通过音频信息能够将视觉特征中不相关的信息滤除掉;另一方面视觉信息能够将音频信息中的背景信息滤除掉:
其中,代表矩阵间的相似性度量,代表将矩阵进行reshape(特征尺寸转化)操作,和代表将特征转化到高维度特征,得到融合后的音视特征为:代表将特征转化到高维度特征,得到融合后的音视特征为:为融合后的音视特征,代表矩阵间的相似性度量,代表视觉特征,代表将特征转化到高维度特征,代表softmax函数归一化,代表将矩阵进行reshape(特征尺寸转化)操作;(7)360度全景监控监测结果输出通过步骤(6)得到融合后的音视特征后,通过融合后的特征生成视点数据,从而基于视点生成视口,其中视点的生成采用两种方式,一种为生成视点坐标位置,另一种为生成视点的平滑后的区域:其中,代表将位置的坐标值进行高斯平滑,从而生成视点区域,代表生成的视点坐标位置,代表网络输出,为融合后的音视特征,为卷积层操作;得到视点位置后,将视点逆投影到球面上,然后二次投影到视口fov上:其中,代表球面投影,代表投影为视口;(8)360度全景监控人机交互360度全景监控虽然能够在大多数情况下实现自动巡航,当出现新的情况的时候,监控能够实现自动跟踪并将跟踪的数据保存。在监控指挥权落到管理人员身上的时候,需要自动切换到管理人员视口,此时,收集鼠标点击位置,甚至是方向键,并通过投影的方式显示管理人员视口:其中,代表人工点击鼠标或者移动方向键产生的坐标位置,代表人工产生的视口,代表投影;由于监控中可能存在多个视点区域,本实施例采用多路path()监控显示的方式,即每个视点存在一个监控路径,对每个路径以小窗的形式显示在显示屏的周围区域,通过不断更新显示内容来显示视点检测的结果。而选择视点相应置信度最高的作为主窗口显示,当出现另一个高视点置信度的时候将会切换到另一个视点继续追踪:其中,代表视点的置信度,即视点的区域响应值,为保证不会因为视点值
变化太快导致窗口切换太快,本实施例采用10帧作为判定标准,即连续10帧都出现新的窗口视点有更高的响应值,才切换窗口;(9)360度全景监控连续学习作为城市中的社区监控系统,虽然在大多数时候是保持稳定不变的状态,但是,当有新情况的时候,模型如果不能及时做出判别将会导致出现险情,如出现新的外来人口,但是监控网络模型更新需要人工标注,无疑会增加系统的复杂度,如果将新的情况作为新数据,直接将原有深度学习模型微调的话,会导致模型出现灾难性遗忘问题,为解决上述问题,本实施例采用连续学习的方式,通过持续的更新数据和更新模型的方式,使提出的模型能够应对不同复杂场景下的360度全景监控场景,先基于已有训练数据,训练360度全景监控分类模型,360度全景监控分类模型有两个分支,分别为学习分支和记忆分支,当新数据训练的时候,记忆分支将会冻结,仅训练学习分支,且双分支为并行卷积,不会增加网络的参数量;(10)网络训练先将全景视频转化为等距投影的2d图片,并将声音保存为mp3的格式,将音视数据输入到网络中,并计算损失函数,损失包含基于平滑后的损失和基于视点坐标的损失两部分,损失函数采用bcewithlogists_loss和kl_loss,训练结束后将模型保存到本地;(11)网络测试将全景视频数据转为erp数据和mp3数据,并输入到网络中,生成视点数据fixation,并生成视口,在人工点击后,将人工点击的位置作为数据输入到本地数据集,将作为连续学习的训练集,提升网络的性能。
17.本实施例提出了一种新型的交互式持续学习的360度全景监控自动巡航方法,能够实现监控的智能化,针对传统监控设备中的盲区问题,本实施例的技术方案能够实现无盲区,且能够实现自动切换视角,在有人工干预的时候,能够将设备控制权交给人工,并根据人工调节的结果实现模型自动提升。
18.本文中未详细描述的网络结构、函数和算法均为本领域通用技术。
19.需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的,因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1