一种固件漏洞检测及数据安全治理方法和系统与流程
本发明涉及一种固件漏洞检测及数据安全治理方法和系统,属于数据安全的。
背景技术:
1、随着互联网的快速发展、物联网产业的兴起,智能化时代已经来临,工业互联网将人、机器和数据互相连接,实现了“数据的流通”。工业互联网能够推动工业链、产业链以及价值链的重塑再造,构建全新的制造服务体系。制造服务业主要指面向制造业的生产性服务业,是促进制造业高质量发展和升级的重要支撑。工业互联网在提高生产效率和交付更高质量产品的同时,也带来了一定的安全隐患。工业互联网虽然打破了传统的工业制造模式,但也面临着被攻击入侵的风险,一旦被成功入侵,便可能会造成严重的信息泄露以及经济损失。工业互联网之所以能够被黑客成功入侵,其原因之一便在于基础设备不受企业重视,比如2016年的mirai病毒便是对互联网基础设备进行攻击,进而导致整个工业互联网瘫痪。因此,从基础设备中识别出漏洞,对工业互联网的安全防范具有重要意义。
2、工业互联网设备属于商业产品,其源码难以获取,因此只能从二进制代码层面分析设备固件的漏洞。固件同源漏洞检测是指利用已知漏洞检测其他固件中可能存在的同源漏洞。目前根据已知漏洞进行固件漏洞检测技术分为两种:基于二进制文件层面的粗粒度检测和基于二进制函数层面的细粒度检测。近年来,随着神经网络技术的迅速发展,安全研究人员将神经网络应用到二进制函数相似性检测方向上,取得了较好的成果。gemini 和genius 通过将acfg(属性控制流程图)输入到图嵌入模型中提取二进制函数的语义信息来比较相似性。他们的缺点在于:(1)在构建acfg时,使用专家经验提取函数的特征,会造成大量的语义损失;(2)以acfg为中间表示,提取函数acfg会增加系统的开销;(3)基于孪生神经网络的训练模型,扩展性差,原因在于训练数据是由不同架构组合的函数样本对,随着系统架构的增加,样本对的适配工作也会增加并且随之训练数据也会成倍增长。
3、中国专利文献cn115168856a公开了二进制代码相似性检测方法,虽然也能够跨架构进行二进制代码相似性检测,但是该文献只能在x86,mips以及arm三种架构之间进行检测;如果,它的方案再想对其他架构进行检测,便需要重新训练模型,且模型训练样本对也会成倍增加。
4、中国专利文献cn114500043a公开基于同源性分析的物联网,该文献在计算二进制函数的相似性时,采用人工选取二进制函数特征的方法,该方法会造成二进制函数的语义信息大量损失,进而导致检测的准确率低。且该方案不能进行跨架构检测。
5、另外,随着网络技术的快速发展,各种攻击手段层出不穷,随着时间的推移,cve漏洞数据随时会发生变化,因此,怎样实现固件漏洞数据的实时管理也成为本技术领域重点关注的内容。
技术实现思路
1、针对现有技术的问题,为了检测物联网设备固件中的开源漏洞,基于二进制函数语义相似性公开了一种固件漏洞检测及数据安全治理方法。本发明还可以用于恶意软件分析、版权纠纷等领域。
2、本发明还公开一种实现上述方法的系统,便于用户使用固件漏洞检测以及查询物联网设备的漏洞信息。
3、本发明还公开一种固件漏洞检测及数据安全治理系统的使用方法。
4、本发明详细的技术方案如下:
5、一种固件漏洞检测及数据安全治理方法,其特征在于,包括:
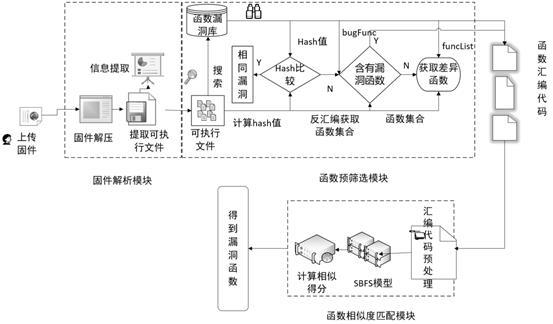
6、(1)固件解析:将待检测的物联网设备固件进行:固件解压、提取可执行文件以及提取可执行文件的相关数据;
7、(2)函数预筛选:将可执行文件通过函数漏洞库、hash计算、反汇编机制以获取可疑漏洞函数;
8、(3)函数相似度匹配:通过检测固件中的可疑漏洞函数是否为已知漏洞函数的同源函数,以此判断,该检测固件中是否包含相应的漏洞。
9、根据本发明优选的,所述方法的步骤(1)固件解析的具体方法包括:
10、(1-1)利用逆向工具binwalk对所述物联网设备固件进行解压得到系统文件;
11、(1-2)在所述系统文件中,对所有文件使用file命令提取可执行文件;
12、(1-3)提取所述可执行文件的相关数据,包括:名字、架构以及版本号。
13、根据本发明优选的,所述方法的步骤(2)函数预筛选中,所述函数漏洞库为函数级cve漏洞数据库;
14、所述函数漏洞库记录漏洞函数的元数据,所述元数据包括:函数名、架构、所在文件以及cve漏洞的基本信息;所述hash计算用于计算可执行文件的hash值;所述反汇编机制用于获取可执行文件的函数;
15、所述函数预筛选的具体方法包括:
16、(2-1)按照可执行文件的相关数据在所述函数漏洞库中检索文件记录,所述可执行文件的相关数据就是所述元数据,将所述可执行文件的hash值和所述文件记录中的hash值进行比较:
17、如果hash值比较结果相同,则可执行文件包含文件记录中的漏洞函数,结束对当前函数的预筛选工作,但是固件中有很多二进制文件,结束对当前二进制文件的函数的预筛选工作后,再开始对下一个二进制文件进行检测;
18、否则,执行步骤(2-2);
19、(2-2)利用二进制代码分析工具对可执行文件进行反汇编机制,以获取可执行文件对应的函数集合:
20、若所述函数集合中包含所述文件记录的漏洞函数,则将所述函数集合中的对应函数标记为可疑漏洞函数;
21、否则,执行步骤(2-3);
22、优选的,所述二进制代码分析工具为angr分析工具;
23、(2-3)将所述可疑漏洞函数作为函数相似度匹配的输入。
24、根据本发明优选的,在步骤(2)中,还包括对所述函数漏洞库的治理方法,包括:在上述函数预筛选中提到的函数级cve漏洞数据库,其治理过程如图3所示,发明将公开的漏洞来源分成固件或者开源软件两部分,一部分是各个厂家公布的固件漏洞,例如d-link路由器厂家公布多个设备出现相同的缓冲区漏洞,该漏洞是由htdocs/cgibin中的main()函数造成的;另一部分是第三方开源组件公布的漏洞,例如openssl(版本1.0.1i之前)的obj_obj2txt函数,该漏洞函数可能会造成堆栈泄露;
25、所述治理方法包括:
26、(2-a)采集公开的漏洞固件或者开源代码;
27、(2-b)对所述开源代码(如图3中已知漏洞的源码组件),利用编译工具(buildroot)将开源代码编译成可执行文件;
28、对所述漏洞固件(如图3中已知漏洞的固件库),利用逆向工具(比如binwalk)对漏洞固件进行解压,得到文件系统;然后从文件系统中找到漏洞所在的可执行文件;
29、(2-c)采集所述可执行文件的基本信息,包括但不限于文件名、架构、hash值;
30、(2-d)提取出可执行文件中的漏洞函数,并转换成函数文本;
31、(2-e)提取的漏洞信息封装成元数据存入数据库中,其中所述漏洞信息是指漏洞函数有漏洞、漏洞的严重程度和信息描述。随着攻击手段的增加,漏洞函数也会随着增加,这就导致实时构建的函数漏洞数据库变得不完善,为此,本发明上述步骤对函数漏洞库进行增加或者修改,以此达到对函数漏洞数据库的治理。
32、根据本发明优选的,所述步骤(2-a)的采集手段包括以下手段中的一种或多种:
33、采用网络爬虫技术爬取公开的漏洞固件或者开源代码;
34、通过厂家发布新的漏洞;
35、通过cve漏洞官方网站发布新的漏洞信息;
36、对原有的漏洞重新定义。
37、根据本发明优选的,在步骤(2-2)中,利用二进制代码分析工具对可执行文件进行反汇编机制时:
38、当没有正确识别出可执行文件对应的函数时,则将文件记录中的函数集合(包括没有漏洞的函数)和可执行文件函数集合的补集作为差异函数,将差异函数标记为可疑漏洞函数。
39、根据本发明优选的,所述步骤(3)函数相似度匹配方法包括:
40、(3-1)将所述可疑漏洞函数进行汇编代码预处理,以得到可疑漏洞函数对应的函数文本;
41、(3-2)所述函数文本作为sbfs模型的输入,得到两个嵌入向量(嵌入向量的生成过程如图4所示);
42、(3-3)使用余弦相似度计算两个嵌入向量的相似得分:
43、如果相似得分大于预设的相似度阈值,则认为可疑漏洞函数为已知漏洞函数的同源函数,进一步,该检测固件中包含相应的漏洞。
44、在上述函数相似度匹配中主要包括汇编代码预处理和sbfs模型,本发明受自然语言处理的启发,将二进制函数汇编代码转换成函数文本,将二进制函数相似度检测任务转换成自然语言文本相似度任务。在类比过程中,本发明发现二进制函数的执行流程不是按照顺序从上到下依次执行的,代码中存在的分支和跳转指令会改变二进制函数的执行流程。其次,开源软件被不同厂家用不同配置(如架构、优化等级、编译器等)编译成二进制文件,给二进制函数相似度检测造成了困难。本发明将二进制汇编代码用中间语言表示消除了指令架构的影响。最后,将二进制代码用中间语言表示形成的代码中包含大量的无意义的词汇,会影响模型的准确性。
45、根据本发明优选的,所述汇编代码预处理包括:函数基本块重排序、vex ir中间表示和无意义词汇的处理;
46、所述函数基本块重排序,用于使函数的基本块按照深度优先遍历的序列排序;
47、与自然语言文本不同,函数执行流程不是顺序执行的,因为函数存在分支和跳转指令,会改变函数的执行顺序,其优点在于能够获取函数最长的执行路径,且避免了文本序列中存在重复的基本块,同时又保障了每个基本块都在函数文本中,所述的序列排序为函数基本块dfs排序;
48、所述vex中间表示:选用vex ir作为二进制函数基本块的中间表示,用于在不改变程序的原始功能和语义的情况下,消除汇编代码在指令架构上存在的差异,从而实现跨架构代码分析。如图5所示,将openssl中的evp_md_do_all_sorted的源代码编译成arm和mips两种架构下的汇编代码,并将汇编代码转换成了中间语言,从图5中可以看出vex ir 代码的主要操作基本相同,其主要差异在于临时寄存器的表示;vex ir代码中存在大量数字常量、运算符、内存地址、临时寄存器以及函数名,这些词汇被vexir随机分配产生,出现的频率极低,很难获得其语义信息。
49、根据本发明优选的,在nlp任务中,在模型训练过程中从未出现的单词在文本中出现时,它被称为oov问题,考虑到oov问题,在所述vex中间表示之后还包括抽象规则,即对vex ir代码中的低频词汇进行标记,其抽象规则以及vex ir经抽象后的效果如图6所示。
50、根据本发明优选的,所述步骤(3)函数相似度匹配方法中,所述sbfs模型是由bert自然语言模型使用mips架构数据集训练得来的,bert自然语言模型对应的全称为bidirectional encoderrepresentations from transformers, 即基于transformer的双向编码器表征,该模型由google ai研究院在2018年提出;bert自然语言模型不同于仅仅获取字词的语义信息的模型,其更专注于获取整个文本的综合语义信息,bert自然语言模型通过无监督学习来获取丰富的文本语义信息特征;bert自然语言模型预训练模型由输入层、编码层和输出层三部分组成,整体架构如图8所示;bert自然语言模型的输入层将输入的句子转化成字向量、文本向量以及位置向量,并且输入的句子以标记符cls开始,两个句子之间用sep隔离,将字向量、文本向量以及位置向量相加作为bert自然语言模型的输入,经过编码层(transform encoder),最终输出句子中各个字词融合了全文语义信息后的向量表示;因此,所述sbfs模型能够充分提取二进制函数的语义信息;本发明使用编译器gccv5.4针对多种架构编译了开源软件源码,并用反汇编机制提取其二进制函数,并通过上述提到的汇编代码预处理将二进制函数转换成自然语言文本,即函数文本,其数据如图7所示;
51、对所述sbfs模型进行训练:
52、选用mips架构下的二进制函数代码作为训练集和评估集,其他架构的数据作为测试集来验证所述sbfs模型跨架构的性能;所述其他架构是指x86,arm等,如图7所示;
53、给定一个二进制函数文本,采用bert的语言掩码模型mlm,在训练过程中,以15%的概率将二进制函数文本的vex ir指令替换成[mask],以迫使bert自然语言模型依赖上下文信息去预测vex ir指令,使vex ir指令的嵌入向量更加准确地表达被替换成[mask]的指令的语义信息;然后将bert自然语言模型输出的函数文本中的所有vex ir指令的嵌入式向量的平均值作为二进制函数文本的嵌入向量。
54、一种实现上述方法的系统,其特征在于,包括:固件解析模块、函数预筛选模块、函数相似度匹配模块和数据治理模块;
55、所述固件解析模块加载有步骤(1)所述的方法步骤;
56、所述函数预筛选模块加载有步骤(2)所述的方法步骤;
57、所述函数相似度匹配模块加载有步骤(2)所述的方法步骤;
58、所述数据治理模块加载有步骤(2)中对所述函数漏洞库的治理方法。
59、本发明还公开一种固件漏洞检测及数据安全治理系统的使用方法,其特征在于,包括:
60、用户登陆所述系统,通过权限分别行使管理员和普通用户功能;
61、通过管理员权限实现对固件漏洞数据管理;
62、通过普通用户权限实现对物联网设备固件漏洞检测、对物联网设备固件漏洞信息查询。
63、本发明的优势在于:
64、1)发明使用自然语言处理模型提取二进制函数的语义信息,不依赖专家知识;其次,本发明能够进行跨架构物联网固件漏洞检测。
65、2)本发明在二进制函数预处理过程中使用vex ir,使本模型具有跨架构的通用性,不再局限于特定的架构对。
66、3)本发明设计一套物联网固件漏洞检测系统以及固件漏洞数据治理系统,基于已知cve漏洞,并对cve漏洞数据库进行管理,定时更新;对于已经检测过的固件,随着cve漏洞数据的变化,也会再次进行检测,保证固件漏洞检测的实时性。
67、4)本发明公布检测到的固件漏洞信息、公布各种物联网设备漏洞的相关信息,以供用户使用。
- 还没有人留言评论。精彩留言会获得点赞!