定位声源自适应方法、系统、电子设备及存储介质与流程
本发明涉及音频处理,具体涉及一种定位声源自适应方法、系统、电子设备及存储介质。
背景技术:
1、会议话筒是会议系统中的基本发言单元,现有会议话筒主要通过手动调节话筒杆,保证会议话筒对准发言人,采集发言人的声音,传递信号给音箱以实现系统扩声,但在实际场景应用中,不同用户的高矮是不一致的,用户在会议中并不总是僵硬的保持一种体态(前倾,后仰,站立),用户个体差异加上体态变化会导致声源位置发生不同幅度的改变,声源位置的变动影响话筒拾音效果,降低会议效率与信息传递,静态固定角度的会议话筒难以应对会议中用户的真实需求,现有会议话筒与人的距离一般保持在80-100cm,频繁的调节影响用户使用体验。
技术实现思路
1、针对所述缺陷,本发明实施例公开了一种定位声源自适应方法、系统、电子设备及存储介质,解决不同用户在实际会议中因体态差异及变化产生的声源位置变动,导致声音采集丢失或效率不高的问题,以实现精准高效的动态声音采集,达到同会议各个发言声均衡。
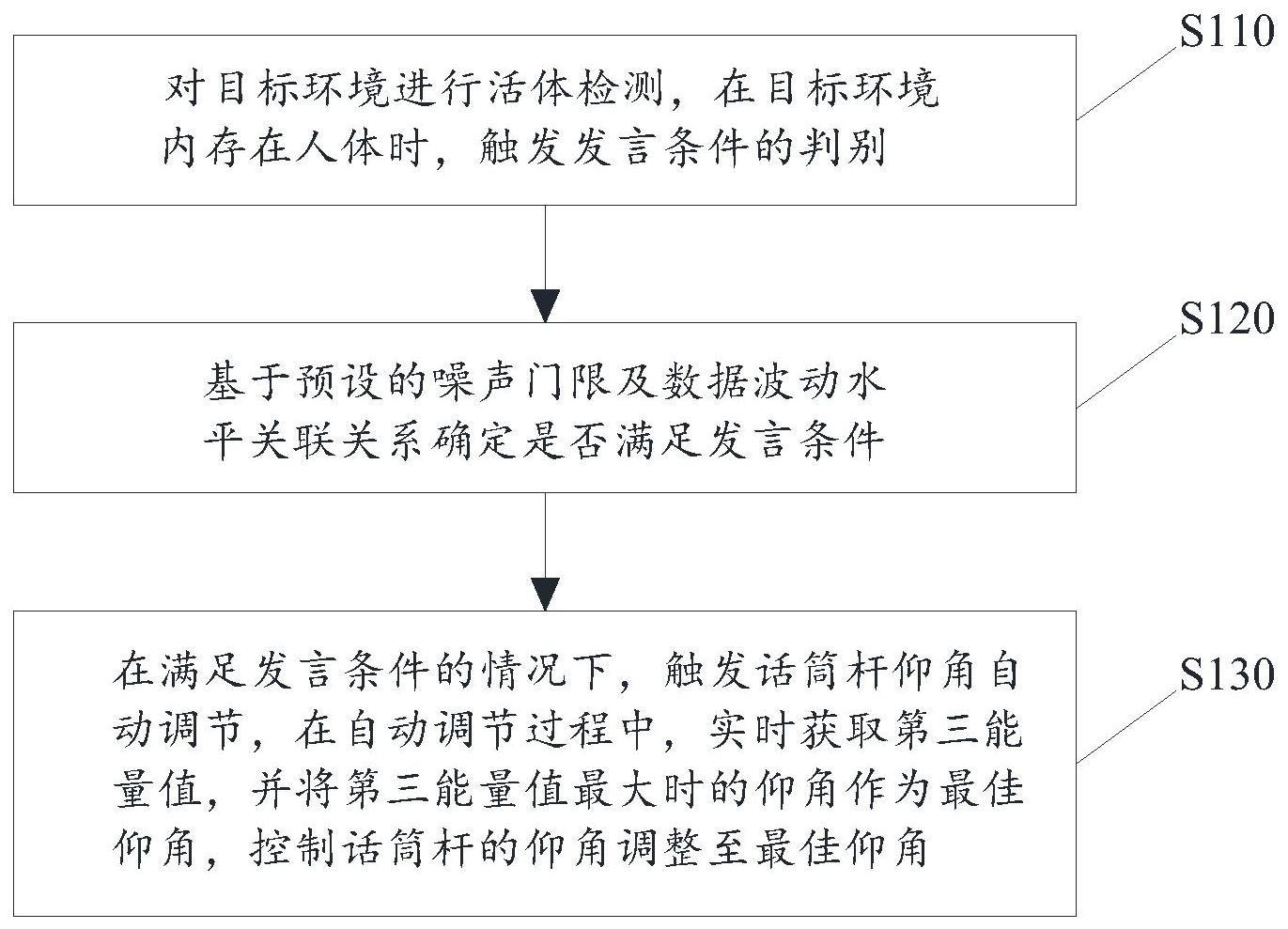
2、本发明实施例第一方面公开一种定位声源自适应方法,所述方法包括:
3、基于预设的噪声门限及数据波动水平关联关系确定是否满足发言条件;
4、在满足发言条件的情况下,触发话筒杆仰角自动调节,在所述自动调节过程中,实时获取第三能量值,并将所述第三能量值最大时的仰角作为最佳仰角,控制所述话筒杆的仰角调整至所述最佳仰角。
5、作为一种可选的实施方式,在本发明实施例第一方面中,基于预设的噪声门限及数据波动水平关联关系确定是否满足发言条件,包括:
6、选取多个样本,获取所述多个样本的第一能量值;
7、基于所述第一能量值确定噪声门限和数据波动水平;
8、建立所述噪声门限和所述数据波动水平的关联关系;
9、根据所述关联关系确定是否满足发言条件。
10、作为一种可选的实施方式,在本发明实施例第一方面中,建立所述噪声门限和所述数据波动水平的关联关系,包括:
11、实时采集每个样本的第一音频数据,并在预设采样率下将所述第一音频数据转换成第一数字信号;
12、获取每一帧第一数字信号的均方根,记为每一帧音频数据的第一能量值;
13、确定每个样本在采集周期内的多个第一能量值的平均值和方差,将所述多个第一能量值的平均值作为噪声门限,将所述多个第一能量值的方差作为数据波动水平;
14、以每个样本的噪声门限和数据波动水平之间的关联性组成噪声门限和数据波动水平之间的关联关系。
15、作为一种可选的实施方式,在本发明实施例第一方面中,基于预设的噪声门限及数据波动水平关联关系确定是否满足发言条件,包括:
16、实时采集目标环境下的第二音频数据,并在预设采样率下将所述第二音频数据转换成第二数字信号;
17、获取每一帧第二数字信号的均方根,记为每一帧第二音频数据的第二能量值;
18、确定在采集周期内的多个第二能量值的平均值和方差,将所述多个第二能量值的平均值作为噪声值,将所述多个第二能量值的方差作为数据波动值;
19、确定所述噪声值对应的目标噪声门限,当所述数据波动值满足目标数据波动水平时,则所述目标环境满足发言条件,所述目标数据波动水平为基于预设的噪声门限及数据波动水平关联关系确定的所述目标噪声门限对应的数据波动水平。
20、作为一种可选的实施方式,在本发明实施例第一方面中,所述基于预设的噪声门限及数据波动水平关联关系确定是否满足发言条件,之前还包括:
21、对目标环境进行活体检测,在所述目标环境内存在人体时,触发所述发言条件的判别;
22、或/和,触发话筒杆仰角自动调节的时间间隔不小于预设时长。
23、作为一种可选的实施方式,在本发明实施例第一方面中,在所述自动调节过程中,实时获取第三能量值,并将所述第三能量值最大时的仰角作为最佳仰角,控制所述话筒杆的仰角调整至所述最佳仰角,包括:
24、在所述话筒杆仰角从第一仰角自动调节到第二仰角时,实时采集调节过程中的第三音频数据,并在预设采样率下将所述第三音频数据转换成第三数字信号;
25、获取所有第三数字信号的均方根,记为第二仰角对应的第三能量值;
26、确定所述话筒杆仰角调节到所有仰角位的第三能量值,并将所述第三能量值最大时的仰角位记为最佳仰角;
27、控制所述话筒杆调整至所述最佳仰角。
28、本发明实施例第二方面公开一种定位声源自适应系统,其包括:处理器、编解码器、驱动机构以及角度检测机构,其中:
29、所述编解码器用于采集音频数据,并将所述音频数据转换成数字信号后发送给所述处理器;
30、所述角度检测机构用于采集话筒杆的仰角,并将采集的所述采集话筒杆的仰角发送给处理;
31、所述处理器用于基于预设的噪声门限及数据波动水平关联关系确定是否满足发言条件;并在满足发言条件的情况下,触发驱动机构调节话筒杆的仰角,在所述驱动机构调节话筒杆的过程中,所述处理器还实时获取第三能量值,将所述第三能量值最大时的仰角作为最佳仰角,并通过所述驱动机构控制所述话筒杆的仰角调整至所述最佳仰角。
32、作为一种可选的实施方式,在本发明实施例第二方面中,所述定位声源自适应系统还包括活体检测机构,所述活体检测机构用于对目标环境进行活体检测,并将所述活体检测信号发送给处理器,所述处理器根据所述活体检测信号触发所述发言条件的判别,所述活体检测机构为红外检测机构;
33、或/和,
34、所述驱动机构为步进电机;
35、或/和,
36、所述角度检测机构为六轴陀螺仪。
37、本发明实施例第三方面公开一种电子设备,包括:存储有可执行程序代码的存储器;与所述存储器耦合的处理器;所述处理器调用所述存储器中存储的所述可执行程序代码,用于执行本发明实施例第一方面公开的一种定位声源自适应方法。
38、本发明实施例第四方面公开一种计算机可读存储介质,其存储计算机程序,其中,所述计算机程序使得计算机执行本发明实施例第一方面公开的一种定位声源自适应方法。
39、本发明实施例第五方面公开一种计算机程序产品,当所述计算机程序产品在计算机上运行时,使得所述计算机执行本发明实施例第一方面公开的一种定位声源自适应方法。
40、本发明实施例第六方面公开一种应用发布平台,所述应用发布平台用于发布计算机程序产品,其中,当所述计算机程序产品在计算机上运行时,使得所述计算机执行本发明实施例第一方面公开的一种定位声源自适应方法。
41、与现有技术相比,本发明实施例具有以下有益效果:
42、本发明实施例中,本发明通过预设的噪声门限及数据波动水平之间的关联关系确定是否有人在发言,进而在发言中基于第三能量值自动调节话筒杆,从而可以减少因调节会议话筒角度而带来的干扰,提高会议效率,保持与会人员注意力,改善会议话筒使用体验,相比被动的提升话筒音量,自适应调节在不增大话筒增益的情况下,可以提高了链路信噪比,一定程度抑制了啸叫产生,提高了传声增益。
- 还没有人留言评论。精彩留言会获得点赞!