用于超浅交换机缓冲区的数据中心网络传输控制方法
本发明属于数据中心网络传输控制或拥塞控制领域,具体涉及用于超浅交换机缓冲区的数据中心网络传输控制方法。
背景技术:
1、数据中心网络的链路速度在过去十年中从10gbps快速地增长到100gbps,但交换机缓冲区扩展速度却非常缓慢,导致其为每gbps提供的缓冲区降低了数十倍,给传输控制方法的设计带来了困难。一方面,越来越多延迟敏感的小流在几个往返时延(round-triptime,rtt)内完成,使得线速启动流量以最优化延迟变得必要;另一方面,由于可用的交换机缓冲区受限,吞吐敏感的大流需要可靠的传输协议来减少因缓冲区溢出带来的丢包,实现高吞吐率。
2、传统的数据中心网络传输控制方法(例如dctcp,dcqcn和timely)难以解决以上问题。原因在于其设计方案是反应式的,即对来自网络的拥塞信号(如ecn,延迟等)做出反应并相应迭代更新发送速率。这些反应式的传输控制方法的收敛时间往往较长,需要多个rtt才能收敛到最优速率,性能往往不佳。因此,主动式传输控制方法(例如phost,ndp,expresspass,homa等)成为一种很有前景的替代方案,其中链路带宽由接收端或中央控制器以信用包(credit packet)的方式预先分配,发送端根据接收到信用包发送相应的计划数据包(scheduled packet),以主动预防拥塞来达到低延迟和高吞吐。经过大量验证,主动式传输控制方法可以保持相当低的丢包率和交换机缓存队列长度,可以适应于高速链路,浅缓冲区交换机的数据中心网络。
3、但现有主动式传输控制方法在第一个rtt等待信用阶段(pre-credit phase)无法计算可用带宽,导致发送过少或过多的非计划数据包(unschedu led packet),难以同时达到低延迟和高吞吐。例如,在等待信用阶段不发送数据,虽然可以提高吐敏感的大流的吞吐率,但会导致带宽被浪费从而增加延迟;若线速发送一个bdp(bandwidth-product-delay)的数据包以最小化延迟,但会带来大量丢包,使得吞吐率下降;尽管最新的方法aeolus在交换机选择性丢弃多余的非计划数据包,但同样无法预知空闲带宽,导致难以同时达到低延迟和高吞吐率。因此,设计一个适用于超浅交换机缓冲区的数据中心网络,同时满足低延迟和高吞吐率的传输控制方法非常重要。
技术实现思路
1、针对现有的数据中心网络传输方法难以在超浅交换机缓冲区下同时达到低延迟和高吞吐的问题,本发明旨在设计一种可高效且准确计算空闲带宽的机制,在最大化带宽利用率的同时降低丢包率。
2、为了达到上述发明目的,本发明采用的技术方案为:
3、用于超浅交换机缓冲区的数据中心网络传输控制方法,包括如下步骤:
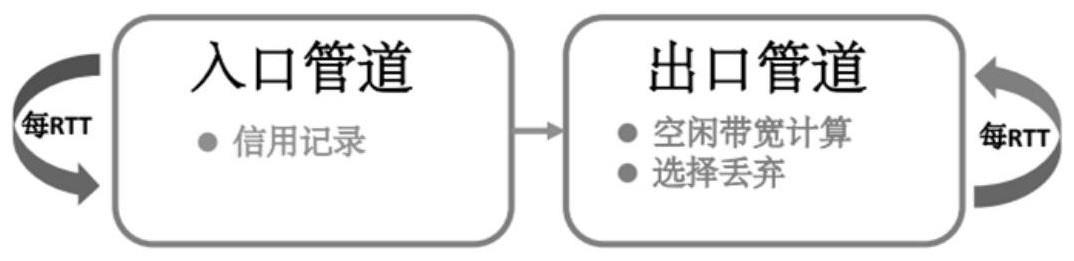
4、所述方法基于网络发送端、接收端和交换机;所述交换机包括控制入口管道和出口管道;其中:
5、所述入口管道用于记录记录当前的rtt内信用的模式并将记录的值在当前rtt结束时传递给出口管道;其中:所述rtt表示网络往返延迟;
6、所述出口管道用于记录所述入口管道输出的信用模式推测和计算可利用空闲带宽并根据计算的可利用空闲带宽选择丢弃或是接收到达交换机的非计划数据包。
7、进一步,所述出口管道用于记录所述入口管道输出的信用模式推测和计算可利用空闲带宽过程:
8、当上一rtt收到的信用数据包数目,即c=0时,这意味着没有信用数据包被记录,网络中所有流量都处于等待信用阶段,缓冲区可以非计划数据包完全占据;
9、当上一rtt收到的信用数据包数目减去当前rtt收到的机会数据包数目小于数据队列空余位置数目时,即c-s<e,获得当前数据队列中的空闲位置接可以接收所有未到达的计划数据包,即空余带宽绝对足够。
10、进一步,所述出口管道根据计算的可利用空闲带宽选择丢弃或是接收到达交换机的非计划数包过程:
11、在当前rtt数据队列中机会数据包最大数目小于上一rtt信用队列最大的长度,即smax<cmax时;保留cmax个位置;
12、在交换机数据队列总长度减去当前rtt收到的非机会数据包数目小于或等于计划数据包的最大队列累积长度cmax,即l-u≤cmax,如果在smax达到其最大值之前保留更小的空间,则尾部计划数据包将在smax处由于拥塞而被丢弃;预留cmax个位置是保证最小化数据包丢失的选择;
13、在当前rtt数据队列中机会数据包最大数目大于或等于上一rtt信用队列最大的长度,即smax≥cmax,保留上一rtt收到的信用队列平均长度,即在上一rtt收到的信用队列平均长度,即cavg个位置;允许非计划数据包可以充分利用空闲带宽,同时保护计划数据包。
14、有益效果
15、本发明通过在交换机在入、出口管道分别计算可用带宽和选择性丢弃非计划书举报,高效地利用网络空闲带宽来降低流量完成时间(flow completion time,fct),同时保证可控情况下不丢失计划数据包来提高吞吐率(goodput)。
16、本方法在大规模仿真集群上与最前沿的主动式传输控制方法aeolus做对比。其中aeolus分别采用不同的选择性丢弃阈值(d=4,6,8个数据包)。集群网络拓扑是数据中心网络最常用的叶脊拓扑,包括144个服务器,9个叶交换机,4个脊交换机。链路带宽均为100gbps;链路延迟为1微秒;交换机数据队列最大长度为8个数据包。应用层流量采用cachefollower,websearch和datamining真实的工作负载;流量按照泊松过程随机启动流来生成,并控制流的到达时间间隔以达到所需的网络负载(0.1至0.9)。
17、图4,5和6为分别在cachefollower,websearch和datamining负载下的实验结果图。图中展示了标准化后的流量延迟和吞吐率。总体上,schef可以达到近乎最优的延迟,同时能保证高吞吐率,而aeolus使用各种丢弃阈值都无法同时达到低延迟和高吞吐。
18、在流量延迟的表现上,schef时的表现优于aeolus在d=4和6的结果,而与aeolusd=8之间只有很小的差距(d=8延迟最小,但吞吐率最低)。如在cachefollower负载下,与d=4和6相比,schef将流量的平均/90th/99th的fct分别减少最多23%/40%/31%和7%/32%/27%。这些结果直接验证了schef在利用剩余空闲带宽方面比在aeolus使用固定阈值更有效。schef在datamining负载的性能与aeolusd=8相当,差距非常很小(~7%)。原因是该负载中的小流相对较小,仅需较少的带宽,因此更适用于schef可靠的交换机设计。
19、在总体吞吐率的表现上,schef可以达到或高于d=4的吞吐率(d=4吞吐率最高,但延迟表现最差)。如在datamining负载下与aeolusd=4相比,schef的吞吐率提高了高达13%,其他两个工作负载的也仅仅只有4%。原因有两方面。首先,因为工作负载更偏斜,平均流大小相对较大,更容易经历吞吐量损失,因此datamining工作负载为schef留下了更多的优化空间。其次,由于本技术的交换机设计消除了aeolus通过计算和在每个rtt中保留足够的带宽所做的权衡,因此有效地保护了计划数据包,以保持较高的吞吐量。
- 还没有人留言评论。精彩留言会获得点赞!