音频数据的处理方法、装置、电子设备及存储介质与流程
本技术涉及音频处理,特别是涉及一种音频数据的处理方法、装置、电子设备及存储介质。
背景技术:
1、当下,随着互联网的普及和高速发展,网络音视频应用已经逐步融入到人们的生活中。例如,网络直播通过互联网网络系统,可以使得观众在不同的终端设备上收听、收看同一个音视频节目,主播之间可以通过连线的方式进行音频互动,给人们带来丰富的视听娱乐体验。
2、相关技术中,当多个主播共同参与音频互动时,一般是通过各自的音频采集设备采集到各自的音频数据,经过线性叠加的混音处理后得到最终的音频数据,并在观众客户端中进行播放输出声音。而实际应用中发现,由于各个主播的音频处理过程是相对独立的,可能存在某个对象(如主播a)在表演歌曲演唱时,连线互动的其他对象(如主播b)发出干扰的声音,且由于主播b侧一般只能听到连线的其他对象的声音,故往往并不知道自己干扰了表演,导致在观众客户端呈现出的直播效果较差,影响视听娱乐体验。
技术实现思路
1、本技术实施例提供了一种音频数据的处理方法、装置、电子设备及存储介质,能够识别并减弱干扰声音的幅度,从而提高音频互动内容的呈现效果,改善视听娱乐体验。
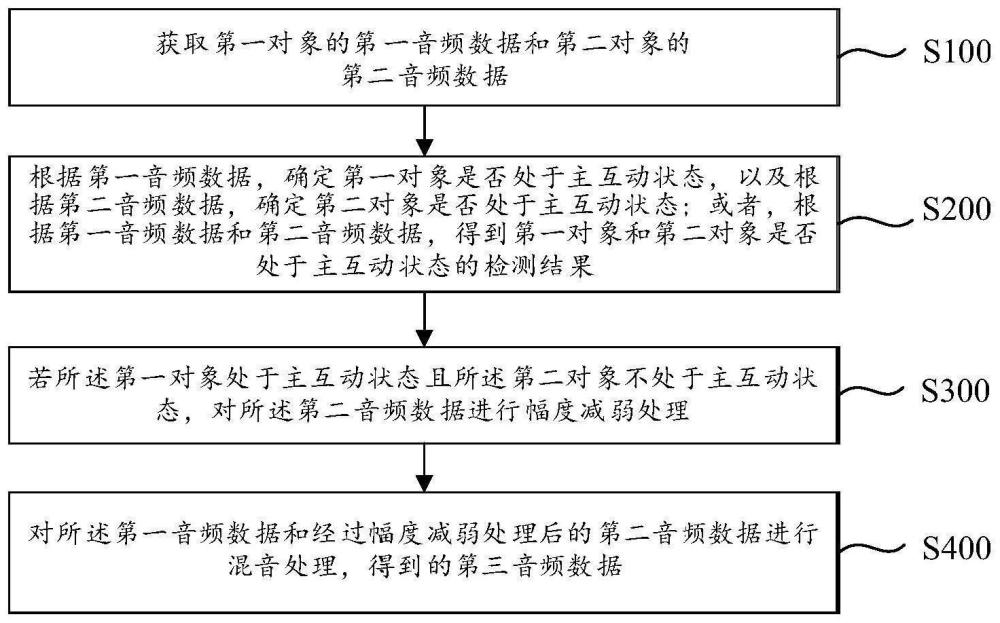
2、本技术实施例的一方面提供了一种音频数据的处理方法,包括以下步骤:获取第一对象的第一音频数据和第二对象的第二音频数据;其中,所述第一对象和所述第二对象之间存在音频互动关系;根据所述第一音频数据,确定所述第一对象是否处于主互动状态,以及根据所述第二音频数据,确定所述第二对象是否处于主互动状态;或者,根据所述第一音频数据和所述第二音频数据,得到所述第一对象和所述第二对象是否处于主互动状态的检测结果;若所述第一对象处于主互动状态且所述第二对象不处于主互动状态,对所述第二音频数据进行幅度减弱处理;对所述第一音频数据和经过幅度减弱处理后的第二音频数据进行混音处理,得到第三音频数据。
3、可选地,本技术实施例中的音频数据的处理方法,根据所述第一音频数据,确定所述第一对象是否处于主互动状态,以及根据所述第二音频数据,确定所述第二对象是否处于主互动状态;或者,根据所述第一音频数据和所述第二音频数据,得到所述第一对象和所述第二对象是否处于主互动状态的检测结果,包括:
4、将所述第一音频数据输入到训练好的第一状态识别模型中;
5、通过所述第一状态识别模型对所述第一音频数据进行处理,得到第一预测结果;所述第一预测结果用于表征所述第一对象是否处于主互动状态;
6、将所述第二音频数据输入到训练好的所述第一状态识别模型中;
7、通过所述第一状态识别模型对所述第二音频数据进行处理,得到第二预测结果;所述第二预测结果用于表征所述第二对象是否处于主互动状态。
8、可选地,本技术实施例中的音频数据的处理方法,所述通过所述第一状态识别模型对所述第一音频数据进行处理,得到第一预测结果,包括:
9、通过第一状态识别模型对所述第一音频数据进行特征提取,得到第一特征数据;
10、根据所述第一特征数据,通过所述第一状态识别模型进行预测得到所述第一预测结果。
11、可选地,本技术实施例中的音频数据的处理方法,所述根据所述第一特征数据,通过所述第一状态识别模型进行预测得到所述第一预测结果,包括:
12、根据所述第一特征数据,通过所述第一状态识别模型确定第一概率值;所述第一概率值用于表征第一对象处于主互动状态的概率;
13、若所述第一概率值小于或者等于第一阈值,确定所述第一预测结果为第一对象不处于主互动状态,或者,若所述第一概率值大于所述第一阈值,确定所述第一预测结果为第一对象处于主互动状态。
14、可选地,本技术实施例中的音频数据的处理方法,所述第一状态识别模型通过以下步骤训练得到:
15、获取批量样本对象的样本音频数据和所述样本音频数据对应的状态标签;所述状态标签用于表征所述样本对象是否处于主互动状态的真实结果;
16、将所述样本音频数据输入到初始化的第一状态识别模型中,通过所述第一状态识别模型对所述样本音频数据进行处理,得到第三预测结果;所述第三预测结果用于表征所述样本对象是否处于主互动状态;
17、根据所述第三预测结果和所述状态标签,确定训练的损失值;
18、根据所述损失值对所述第一状态识别模型的参数进行更新,得到训练好的第一状态识别模型。
19、可选地,本技术实施例中的音频数据的处理方法,所述根据所述第一音频数据,确定所述第一对象是否处于主互动状态,以及根据所述第二音频数据,确定所述第二对象是否处于主互动状态;或者,根据所述第一音频数据和所述第二音频数据,得到所述第一对象和所述第二对象是否处于主互动状态的检测结果,包括:
20、将所述第一音频数据和所述第二音频数据输入到训练好的第二状态识别模型中,提取所述第一音频数据的第一特征数据和所述第二音频数据的第二特征数据;
21、对所述第一特征数据和所述第二特征数据进行特征融合,得到第三特征数据;
22、根据所述第三特征数据,通过所述第二状态识别模型进行预测,得到第一预测结果和第二预测结果;其中,所述第一预测结果用于表征所述第一对象是否处于主互动状态;所述第二预测结果用于表征所述第二对象是否处于主互动状态。
23、可选地,本技术实施例中的音频数据的处理方法,根据所述第一音频数据,检测所述第一对象是否处于主互动状态,包括:
24、检测所述第一音频数据中是否存在歌曲片段;
25、若所述第一音频数据中存在歌曲片段,确定所述第一对象处于主互动状态,或者,若所述第一音频数据中不存在歌曲片段,确定所述第一对象不处于主互动状态。
26、可选地,本技术实施例中的音频数据的处理方法,所述检测所述第一音频数据中是否存在歌曲片段,包括:
27、在预先建立的歌曲匹配资源库中,对所述第一音频数据进行相似度匹配;所述歌曲匹配资源库中包括若干歌曲音频数据;
28、若所述第一音频数据和任意所述歌曲音频数据之间的相似度大于或者等于第二阈值,确定所述第一音频数据中存在歌曲片段,或者,若所述第一音频数据和所有所述歌曲音频数据之间的相似度小于所述第二阈值,确定所述第一音频数据中不存在歌曲片段。
29、可选地,本技术实施例中的音频数据的处理方法,根据所述第一音频数据,检测所述第一对象是否处于主互动状态,包括:
30、获取所述第一对象对应的图像数据;
31、将所述第一音频数据和所述图像数据输入到训练好的第三状态识别模型中,提取所述第一音频数据的第一特征数据和所述图像数据的第四特征数据;
32、对所述第一特征数据和所述第四特征数据进行特征融合,得到第五特征数据;
33、根据所述第五特征数据,通过所述第三状态识别模型进行预测,得到第一预测结果;其中,所述第一预测结果用于表征所述第一对象是否处于主互动状态。
34、可选地,本技术实施例中的音频数据的处理方法,所述对所述第二音频数据进行幅度减弱处理,包括:
35、若所述第二音频数据的音频幅度小于或者等于第三阈值,将所述第二音频数据的音频幅度降低为0;
36、或者,若所述第二音频数据的音频幅度大于所述第三阈值且小于第四阈值,将所述第二音频数据的音频幅度按预设比例进行幅度减弱处理;
37、或者,若所述第二音频数据的音频幅度大于或者等于所述第四阈值,将所述第二音频数据的音频幅度限定为目标幅度值;所述目标幅度值等于所述第四阈值和所述预设比例的乘积;
38、其中,所述第三阈值小于所述第四阈值。
39、可选地,本技术实施例中的音频数据的处理方法,该方法还包括以下步骤:
40、若所述第一对象不处于主互动状态且所述第二对象处于主互动状态,对所述第一音频数据进行幅度减弱处理;
41、或者,若所述第一对象处于主互动状态且所述第二对象不处于主互动状态,对所述第一音频数据进行幅度增强处理;
42、或者,若所述第一对象不处于主互动状态且所述第二对象处于主互动状态,对所述第二音频数据进行幅度增强处理。
43、另一方面,本技术实施例提供了一种音频数据的处理装置,包括:
44、获取单元,用于获取第一对象的第一音频数据和第二对象的第二音频数据;其中,所述第一对象和所述第二对象之间存在音频互动;
45、检测单元,用于根据所述第一音频数据,确定所述第一对象是否处于主互动状态,以及根据所述第二音频数据,确定所述第二对象是否处于主互动状态;或者,根据所述第一音频数据和所述第二音频数据,得到所述第一对象和所述第二对象是否处于主互动状态的检测结果;
46、处理单元,用于若所述第一对象处于主互动状态且所述第二对象不处于主互动状态,对所述第二音频数据进行幅度减弱处理;
47、生成单元,用于对所述第一音频数据和经过幅度减弱处理后的第二音频数据进行混音处理,得到第三音频数据。
48、可选地,本技术实施例中的音频数据的处理装置,检测单元还包括:
49、第一子单元,用于将所述第一音频数据输入到训练好的第一状态识别模型中;
50、第二子单元,用于通过所述第一状态识别模型对所述第一音频数据进行处理,得到第一预测结果;所述第一预测结果用于表征所述第一对象是否处于主互动状态;
51、第三子单元,用于将所述第二音频数据输入到训练好的所述第一状态识别模型中;
52、第四子单元,用于通过所述第一状态识别模型对所述第二音频数据进行处理,得到第二预测结果;所述第二预测结果用于表征所述第二对象是否处于主互动状态。
53、可选地,本技术实施例中的音频数据的处理装置,第二子单元还用于通过第一状态识别模型对所述第一音频数据进行特征提取,得到第一特征数据;根据所述第一特征数据,通过所述第一状态识别模型进行预测得到所述第一预测结果。
54、可选地,本技术实施例中的音频数据的处理装置,第二子单元还用于根据所述第一特征数据,通过所述第一状态识别模型确定第一概率值;所述第一概率值用于表征第一对象处于主互动状态的概率;若所述第一概率值小于或者等于第一阈值,确定所述第一预测结果为第一对象不处于主互动状态,或者,若所述第一概率值大于所述第一阈值,确定所述第一预测结果为第一对象处于主互动状态。
55、可选地,本技术实施例中的音频数据的处理装置,还包括第一训练单元,所述第一训练单元用于训练第一状态识别模型,所述第一训练单元用于获取批量样本对象的样本音频数据和所述样本音频数据对应的状态标签;所述状态标签用于表征所述样本对象是否处于主互动状态的真实结果;将所述样本音频数据输入到初始化的第一状态识别模型中,通过所述第一状态识别模型对所述样本音频数据进行处理,得到第三预测结果;所述第三预测结果用于表征所述样本对象是否处于主互动状态;根据所述第三预测结果和所述状态标签,确定训练的损失值;根据所述损失值对所述第一状态识别模型的参数进行更新,得到训练好的第一状态识别模型。
56、可选地,本技术实施例中的音频数据的处理装置,检测单元还用于将所述第一音频数据和所述第二音频数据输入到训练好的第二状态识别模型中,提取所述第一音频数据的第一特征数据和所述第二音频数据的第二特征数据;对所述第一特征数据和所述第二特征数据进行特征融合,得到第三特征数据;根据所述第三特征数据,通过所述第二状态识别模型进行预测,得到第一预测结果和第二预测结果;其中,所述第一预测结果用于表征所述第一对象是否处于主互动状态;所述第二预测结果用于表征所述第二对象是否处于主互动状态。
57、可选地,本技术实施例中的音频数据的处理装置,检测单元还包括:
58、第五子单元,用于检测所述第一音频数据中是否存在歌曲片段;
59、第六子单元,用于若所述第一音频数据中存在歌曲片段,确定所述第一对象处于主互动状态,或者,若所述第一音频数据中不存在歌曲片段,确定所述第一对象不处于主互动状态。
60、可选地,本技术实施例中的音频数据的处理装置,第五子单元还用于在预先建立的歌曲匹配资源库中,对所述第一音频数据进行相似度匹配;所述歌曲匹配资源库中包括若干歌曲音频数据;若所述第一音频数据和任意所述歌曲音频数据之间的相似度大于或者等于第二阈值,确定所述第一音频数据中存在歌曲片段,或者,若所述第一音频数据和所有所述歌曲音频数据之间的相似度小于所述第二阈值,确定所述第一音频数据中不存在歌曲片段。
61、可选地,本技术实施例中的音频数据的处理装置,检测单元还用于获取所述第一对象对应的图像数据;将所述第一音频数据和所述图像数据输入到训练好的第三状态识别模型中,提取所述第一音频数据的第一特征数据和所述图像数据的第四特征数据;对所述第一特征数据和所述第四特征数据进行特征融合,得到第五特征数据;根据所述第五特征数据,通过所述第三状态识别模型进行预测,得到第一预测结果;其中,所述第一预测结果用于表征所述第一对象是否处于主互动状态。
62、可选地,本技术实施例中的音频数据的处理装置,处理单元还用于若所述第二音频数据的音频幅度小于或者等于第三阈值,将所述第二音频数据的音频幅度降低为0;或者,若所述第二音频数据的音频幅度大于所述第三阈值且小于第四阈值,将所述第二音频数据的音频幅度按预设比例进行幅度减弱处理;或者,若所述第二音频数据的音频幅度大于或者等于所述第四阈值,将所述第二音频数据的音频幅度限定为目标幅度值;所述目标幅度值等于所述第四阈值和所述预设比例的乘积;其中,所述第三阈值小于所述第四阈值。
63、可选地,本技术实施例中的音频数据的处理装置,处理单元还用于若所述第一对象不处于主互动状态且所述第二对象处于主互动状态,对所述第一音频数据进行幅度减弱处理;或者,若所述第一对象处于主互动状态且所述第二对象不处于主互动状态,对所述第一音频数据进行幅度增强处理;或者,若所述第一对象不处于主互动状态且所述第二对象处于主互动状态,对所述第二音频数据进行幅度增强处理。
64、另一方面,本技术实施例提供了一种电子设备,包括处理器以及存储器;
65、所述存储器用于存储程序;
66、所述处理器执行所述程序实现前面的方法。
67、另一方面,本技术实施例提供了一种计算机可读存储介质,所述存储介质存储有程序,所述程序被处理器执行实现前面的方法。
68、本技术实施例还公开了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器可以从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行前面的方法。
69、本技术实施例至少包括以下有益效果:本技术提供一种音频数据的处理方法,该方法应用于音频互动内容的呈现场景,在该场景下,包括有存在音频互动关系的第一对象和第二对象,在二者交互时,获取第一对象的第一音频数据和第二对象的第二音频数据,基于这些音频数据,可以检测出第一对象和第二对象是否处于主互动状态。当第一对象处于主互动状态,且第二对象不处于主互动状态时,可以对第二音频数据进行幅度减弱处理,降低第二对象可能产生的干扰声音的影响,然后再对第一音频数据和经过幅度减弱处理后的第二音频数据进行混音处理,得到第三音频数据。如此,基于音频数据的检测识别,能够高效、准确地区分出各个对象所处的互动状态,可使得第三音频数据中不处于主互动状态的对象所产生的声音得到有效抑制,从而提高呈现出的音频互动内容的质量,改善视听娱乐体验。
- 还没有人留言评论。精彩留言会获得点赞!