基于Transformer的目标级别恰可识别失真的预测方法及终端
本发明涉及机器视觉编码领域,尤其涉及的是基于transformer的目标级别恰可识别失真的预测方法及终端。
背景技术:
1、随着人工智能技术的发展,特别是深度学习的发展,推动许多基于机器视觉的应用的落地,如智慧城市、视频监控、自动驾驶和工业自动化等。这些应用通常会产生大量的图像和视频数据。由于带宽的限制,往往需要压缩图像视频数据以便存储和传输。对于基于机器视觉的应用,压缩图像和视频的时候,除了最小化传输比特率之外还要兼顾机器视觉任务性能。然而,传统的图像压缩标准,如jpeg、jpeg 2000,以及最近的视频编码标准,如h.264/avc、h.265/hevc和h.266/vvc都是针对人类视觉的特点进行开发的,其目标是在给定的比特率下将人类视觉系统(human vision system,hvs)感知的失真降到最低。
2、不可避免的是,压缩失真会影响人类感知的视觉质量,随着压缩率的增加,感知质量会下降。由于人类视觉系统的心理和生理上的视觉冗余,并不是每一个失真都能被感知,这就促使人们通过利用视频中的视觉冗余进行感知优化编码。人类视觉系统最重要的视觉特性之一是恰可察觉失真(just noticeable distortion,jnd),它代表了人眼可感知的最小图像变化,已在压缩领域中用来消除人眼的视觉冗余。许多关于恰可察觉失真的主观研究都是为了揭示人类视觉系统的心理和生理视觉机制。然后,人们开发了客观的恰可察觉失真预测模型来预测恰可察觉失真。
3、在基于机器视觉的应用中,失真也会影响基于机器视觉的识别任务的性能。然而,机器视觉模型的感知与人类视觉系统的感知特性明显不同。对于低比特率下的压缩图像和视频,很多机器视觉任务的ai模型甚至会失去提取图像视频的代表性特征的能力,这将可能导致模型性能降低到一个不可接受的程度。随着计算机视觉的发展和基于机器视觉的相关应用数据的增长,越来越多的图像和视频逐渐服务于机器视觉。传统的图像和视频编码标准由于是为人类视觉系统设计的,所以越来越难以服务于机器视觉相关的应用。为了支持智能多媒体分析和应用,人们提出了机器视觉编码(video coding for machine,vcm)的新标准。在2019年7月,动态图像专家组成立了一个新的专家组开展机器视觉编码标准的制定工作,其目标是在保证机器视觉任务的准确性的同时,确保传输的效率。与人类视觉系统中的恰可察觉失真类似,图像或视频也有一个恰可识别失真(just recognizabledistortion,jrd)。恰可识别失真表示的是能明显影响机器视觉任务模型识别性能的最小失真。它在图像或者视频压缩和处理中非常有用,可以在减少传输比特的同时保持视觉任务的预测准确性。
4、由于恰可识别失真的高度重要性和应用前景,人们提出了一些关于研究恰可识别失真的机制、数据集和预测模型的工作。lin等人证明了恰可察觉失真在机器视觉的图像分类中是存在的,并将其命名为深度机器视觉恰可察觉失真(deep machine vision-jnd,dmv-jnd)。然后,他们还提出了一个带有类激活图(class activate map)的dmv-jnd图像生成模型,以约束dmv-jnd图像的变化及其空间分布,同时将相对分类精度保持在一个较高的水平。然而,dmv-jnd只保证了分类结果与原始图像的分类结果相比保持不变,可以通过进一步扩展完善dmv-jnd的定义来改善其上限。tian等人提出了一个用于人脸识别的恰可察觉失真数据集。他们结合通道注意和自监督,提出了一个面向人脸识别的恰可察觉失真预测框架,以预测相应的恰可察觉失真图像。在压缩图像时,他们根据峰值信噪比psnr值和预测的恰可察觉失真图像,从压缩的图像中选择压缩所用的量化参数(quantizerparameterm,qp)。然而,由于psnr值是面向人类视觉的客观指标,所以该量化参数qp预测方法对机器视觉来说是不合适的。基于用户满意度比率(satisfied user ratio,sur),zhang等人提出了一个基于深度学习的模型来预测压缩图像或视频帧的满意机器比率(satisfied machine ratio,smr),然后通过简单的阈值计算得出恰可识别失真。zhang等人建立了一个面向目标检测的恰可识别失真数据集,并提出了一个基于集成学习的框架来预测有参考条件下的恰可识别失真。考虑到恰可识别失真数据集的类不平衡问题,他们将预测恰可识别失真的多分类任务转化为多个二元分类的集成。该集成框架可以根据多个基于vgg-19的二分类器的输出来确定预测的恰可识别失真。然而,它只能从9个qp中预测恰可识别失真。而在最新的编码标准vvc中,可供压缩选择的qp是64个(0-63)。也就是说,该集成框架预测的恰可识别失真不够精细化,存在进一步提升的空间。
5、因此,现有技术还有待改进。
技术实现思路
1、本发明要解决的技术问题在于,针对现有技术缺陷,本发明提供一种基于transformer的目标级别恰可识别失真的预测方法及终端,以解决传统的集成框架预测的恰可识别失真不够精细化的技术问题。
2、本发明解决技术问题所采用的技术方案如下:
3、第一方面,本发明提供一种基于transformer的目标级别恰可识别失真的预测方法,包括:
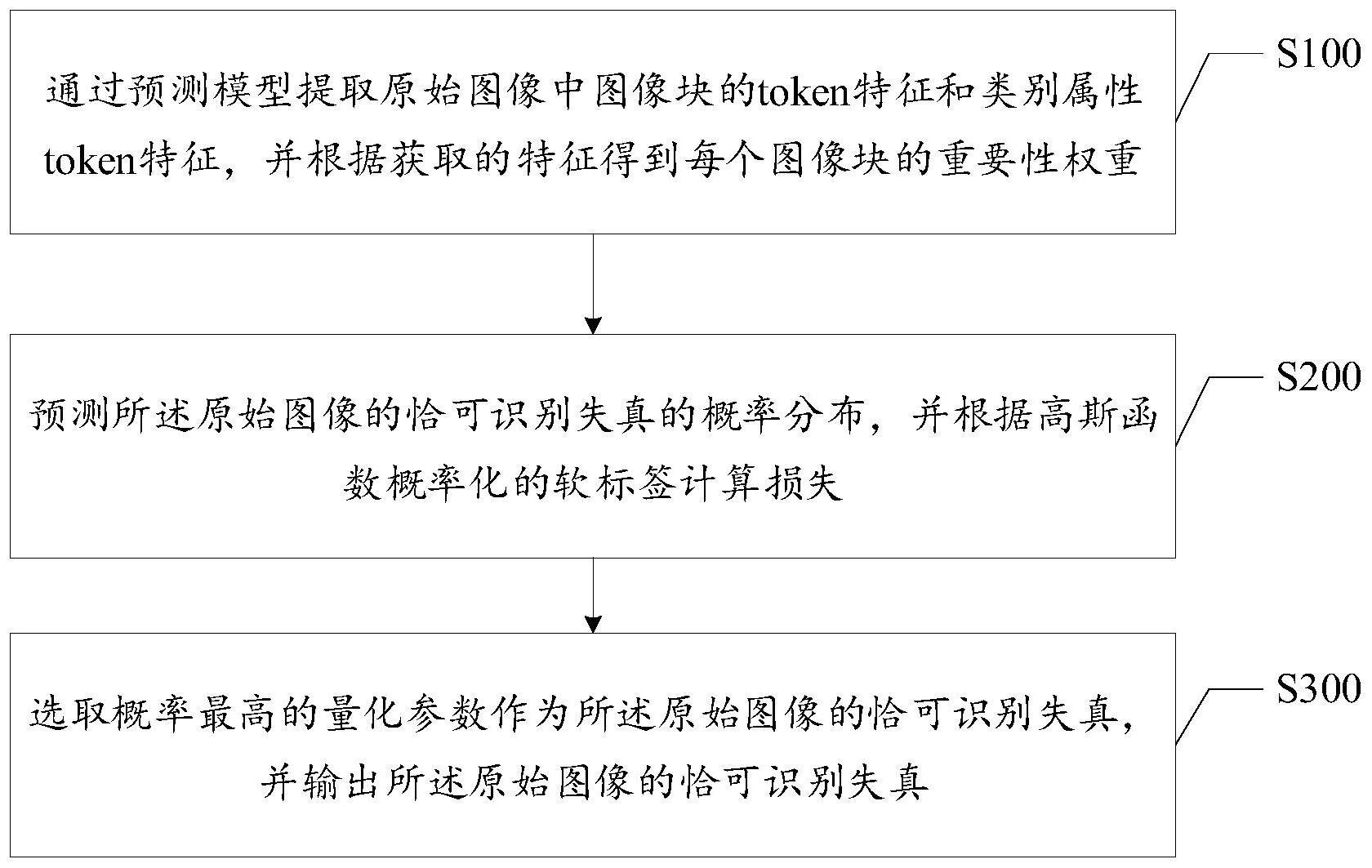
4、通过预测模型提取原始图像中图像块的token特征和类别属性token特征,并根据获取的特征得到每个图像块的重要性权重;
5、预测所述原始图像的恰可识别失真的概率分布,并根据高斯函数概率化的软标签计算损失;
6、选取概率最高的量化参数作为所述原始图像的恰可识别失真,并输出所述原始图像的恰可识别失真。
7、在一种实现方式中,所述通过预测模型提取原始图像中图像块的token特征和类别属性token特征,包括:
8、建立一个用于目标检测的恰可识别失真图像数据集;其中,所述恰可识别失真图像数据集包括若干张原始图像;
9、其中,若干张所述原始图像对应多种物体类别,且每一张所述原始图像对应64个不同的量化参数的压缩图像。
10、在一种实现方式中,所述预测模型包括:token提取网络、主干网络、块重要性度量模块和高斯函数概率化的软标签模块。
11、在一种实现方式中,所述通过预测模型提取原始图像中图像块的token特征和类别属性token特征,并根据获取的特征得到每个图像块的重要性权重,包括:
12、将所述原始图像分别输入所述token提取网络和所述主干网络;
13、通过所述token提取网络提取所输入的原始图像上每个图像块的token特征和具备类别属性的class token特征;
14、将得到的token特征,输入到所述块重要性度量模块,计算每个图像块的token权重,并通过所述主干网络在所输入的原始图像中添加每个图像块的token权重进行加权计算,得到每个图像块与所述原始图像的类别属性的相关性参数。
15、在一种实现方式中,所述计算每个图像块的token权重,并通过所述主干网络在所输入的原始图像中添加每个图像块的token权重进行加权计算,得到每个图像块与所述原始图像的类别属性的相关性参数,包括:
16、通过所述块重要性度量模块计算所述token提取网络提取的图像块的token特征和所述class token特征之间的余弦相似性,得到每个图像块与原图像类别属性的相关性参数。
17、在一种实现方式中,所述预测原始图像的恰可识别失真的概率分布,并根据高斯函数概率化的软标签计算损失,包括:
18、将高斯函数概率化的软标签作为真实标签分布,与所述主干网络预测的类别概率计算交叉熵损失,调整所述主干网络的参数。
19、在一种实现方式中,所述token提取网络和所述主干网络的transformer编码器的个数均为n。
20、在一种实现方式中,所述原始图像在每个量化参数类别的概率分布服从以下高斯分布:
21、
22、其中,m为目标图像的真实恰可识别失真;
23、σ为标准差;
24、x为量化参数,取值范围为0到63的所有整数。
25、第二方面,本发明提供一种计算机终端,包括:处理器以及存储器,所述存储器存储有基于transformer的目标级别恰可识别失真的预测程序,所述基于transformer的目标级别恰可识别失真的预测程序被所述处理器执行时用于实现如第一方面所述的基于transformer的目标级别恰可识别失真的预测方法的操作。
26、第三方面,本发明提供一种计算机可读存储介质,所述计算机可读存储介质存储有基于transformer的目标级别恰可识别失真的预测程序,所述基于transformer的目标级别恰可识别失真的预测程序被处理器执行时用于实现如第一方面所述的基于transformer的目标级别恰可识别失真的预测方法的操作。
27、本发明采用上述技术方案具有以下效果:
28、本发明通过预测模型提取原始图像中图像块的token特征和类别属性token特征,并根据获取的特征得到每个图像块的重要性权重,可以预测原始图像的恰可识别失真的概率分布,并根据高斯函数概率化的软标签计算损失;以及通过选取概率最高的量化参数作为原始图像的恰可识别失真,可以输出原始图像的恰可识别失真;本发明所提的基于transformer的恰可识别失真预测模型可以预测出更加准确和精细化的恰可识别失真。
- 还没有人留言评论。精彩留言会获得点赞!