一种基于机器学习的零信任网络信任评估方法与流程
本发明涉及一种基于机器学习的零信任网络信任评估方法,属于网络安全。
背景技术:
1、随着新一代技术的高速发展,在全新科技态势下的安全风险与攻击事件不断涌现。原有的安全框架,如"边界安全模型"的弊端更加突出。例如,一旦攻击者拿到内网某台主机的访问控制权限,加之现有的防御策略对内网的权限控制并不是非常严格,攻击者就可以通过一系列的操作,实现在内网中的横向移动,最终控制整个网络。这种情况下网络即使采用了完善的边界安全模型,也没有办法抵御攻击。归根到底,是因为安全系统对内网用户的信任。这种情况下催生了一种新的网络安全技术架构——零信任。在零信任的体系下,默认内外网用户,计算机和应用都是不可以信任的,所有访问都需要进行认证和授权,即,任何设备或者用户进入网络都是没有权限的。
2、在零信任网络架构中信任评估引擎作为其核心组件,起着对网络请求及活动的风险进行数值评估的作用,访问控制引擎是基于这个风险评估进行进一步授权决策,以确定是否允许这次访问请求。如何对网络请求及活动进行合理信任评估,是零信任技术落地,首当要解决的问题。
3、在已有的信任评估的文献中,大多采用的是传统的基于访问主体和访问客体之间直接或间接的交互经验进行信任评估的方法。但是,当访问主体与客体之间没有交互经验时,传统的信任评价方法就不那么好用了。同时,也存在用于信任评估的数据不完整、评估过程忽略其他有价值数据的情况,极大地影响了信任评估的准确性。此外,传统的信任评估方法大多通过加权等相关计算对信任因子进行聚合来确定信任,但是,权值的确定是比较困难的,难以保证评价的准确性。
技术实现思路
1、传统的信任评估算法利用直接的历史交互信息和间接的推荐信息来计算信任值,但当访问主体是新人时,这些信息并不存在,这就导致传统的方法变得无效。为克服传统方法的"冷启动"和"零知识"问题,本发明提供一种基于机器学习的零信任网络信任评估方法,利用信任特征,预测访问主体可信分。
2、该方法可用于零信任网络,持续动态对访问主体进行信任评估,得到的可信分将用于后续的访问控制。
3、为解决上述技术问题,本发明所采用的技术方案如下:
4、一种基于机器学习的零信任网络信任评估方法,包括:
5、第一阶段,包括数据预处理和选择性神经网络集成模型的结构设计,这时的集成模型的集中权重为随机定义的向量;
6、第二阶段,使用第一阶段设计的神经网络集成模型,根据粒子群优化算法(pso)的搜索来优化集成权重;
7、第三阶段,使用第二阶段优化后的集成权重,构建优化的选择性神经网络集成模型,使用优化的选择性集成模型来预测访问主体的可信分。
8、上述第一阶段,根据信任分预测问题的要求,设计反向传播神经网络的网络结构和输入输出格式,请求记录在此阶段通过数据归一化技术进行预处理,归一化计算方式如下:
9、
10、其中qmax和qmin分别是第j个信任特征的最小值和最大值,1≤j≤mqij是第i次请求的第j个信任特征值,q′ij是归一化处理后的第i此访问的第j个信任特征值;
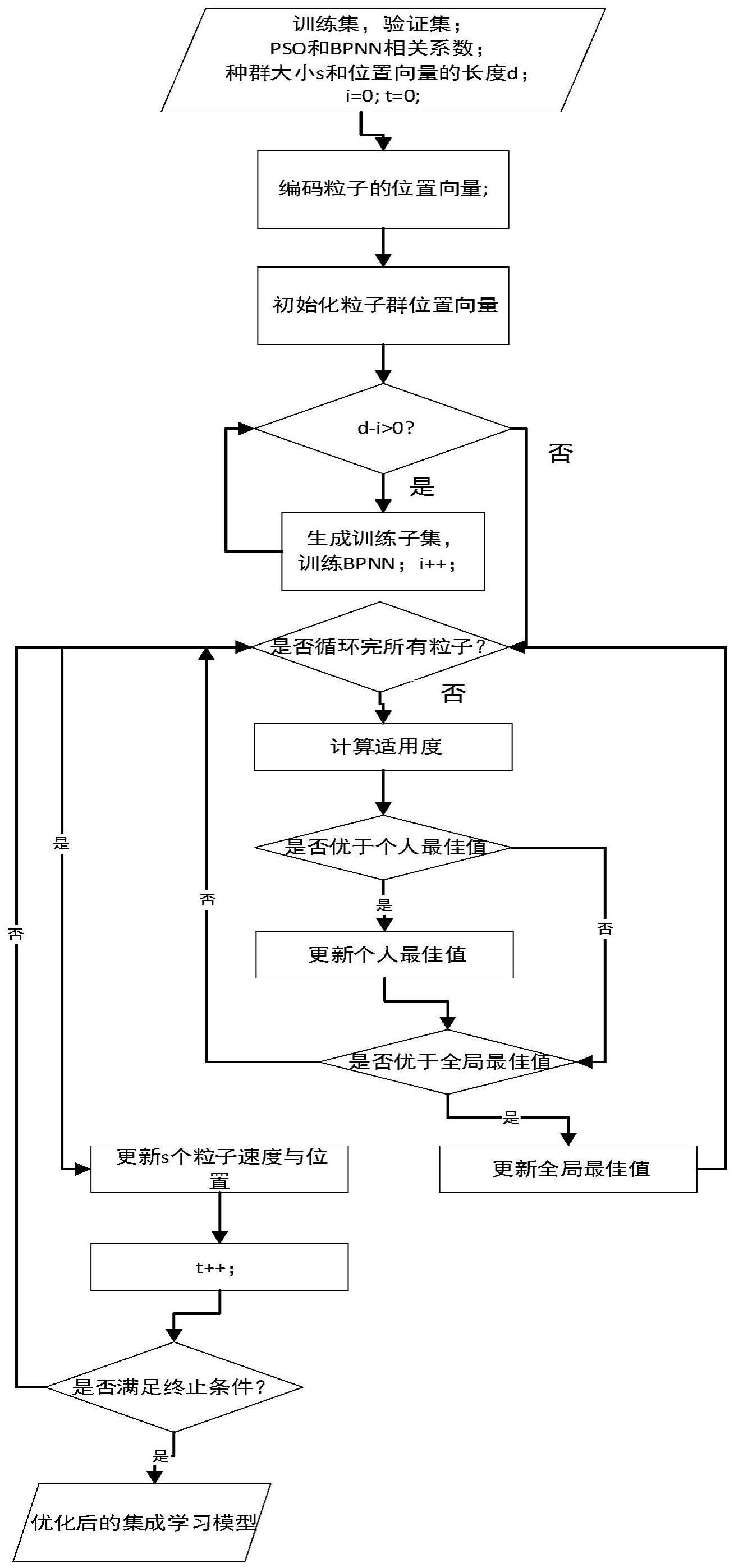
11、将第i次访问主体的请求记录记为如下形式:
12、exami=((qi1,qi2,...,qim),yi)
13、其中,m为信任特征的数量,yi为第i次请求的信任分qij,1≤j≤m,是第i次请求的第j个信任特征值;
14、d={exam1,exam2,...,examn}为请求记录集合,将请求记录集合分为三个子集,分别是,训练集,训练集通过随机抽样继续分为d个训练子集,用来训练每个反向传播神经网络;验证集,用于指导基于粒子群优化算法的选择性神经网络集成模型搜索最优聚合权向量;测试集,用于评估信任分预测模型性能;
15、将每个归一化后的样本(q′i1,q′i2,...,q′im)用作基本反向传播神经网络(bpnn)的输入,输出是相应访问主体的信任分;对于d个归一化训练子集,分别用来训练d个反向传播神经网络,用粒子群优化算法中的粒子表示集成权向量,对d个反向传播神经网络的预测结果进行集成。
16、第一阶段的d个反向传播神经网络的预测结果的集成作为第二阶段的输入,第二阶段的目的是用粒子群优化算法来优化d个反向传播神经网络的集成权重,第二阶段,包括如下步骤:
17、步骤201,将当前选择性神经网络集成模型的权重映射到粒子群优化算法中粒子的位置向量,并随机地初始化s个粒子的位置向量;
18、步骤202,使用自举策略从完整训练集中采样d个训练子集,对于每个训练子集,使用反向传播训练人工神经网络,粒子的迭代次数t初始化为0;
19、步骤203,将每个粒子pk,(k=1,2,...,s)的位置向量解码为选择性神经网络集成学习模型的权重,通过集成分别由训练子集训练的d个基本反向传播神经网络来生成选择性神经网络集成学习模型;
20、粒子群优化算法中的粒子pk=(pk1,pk2,...,pkd),表示选择性反向传播神经网络(bpnn)集合的权重,其中,d是反向传播神经网络的数目,s是种群大小,1≦k≦s;
21、计算验证集上的预测误差作为每个粒子的适应度,利用验证集优化集成学习模型;
22、
23、
24、fitness(pk)为适用度函数,其度量的是验证集上的预测误差,n为验证集内样本的个数,(pk1,pk2,...,pkd)为粒子的位置向量,为选择性神经网络集成学习预测的信任分,ri为真实信任分,为反向传播神经网络学习器预测的信任分;
25、步骤204,使用每个粒子的适用度来更新个人最佳值pbestk和全局最佳值gbest,如果该适用度好于个人最佳粒子的适应度,则将位置向量指定为个人最佳;如果该适用度好于全局最佳粒子的适用度,则将当前位置向量指定为全局最佳;
26、步骤205,已经评估了所有的粒子的适用值后,根据下列等式更新种群中的每个粒子的速度向量和位置向量:
27、使用vk和pk分别表示第k个粒子的速度和位置,优化过程根据粒子自身的个人最佳记录和全局最佳动态调整粒子的速度;
28、vk(t+1)=λvk(k)+c1r1k(pbestk-pk(t))+c2r2k(gbest-pk(t))
29、pk(t+1)=pk(t)+vk(t+1)
30、其中,λ是惯性权重,用于控制上一代速度对当前代速度的影响,取值和迭代次数相关;参数c1和c2为学习因子,分别反映个人最佳pbestk和全局最佳gbest对粒子速度的影响;参数r1k和r2k是范围在[0,1]中的随机数,t是当前的迭代次数;
31、
32、其中,tmax是最大迭代次数,t是当前迭代次数,λmax和λmin是最大和最小权重,分别设置为0.95和0.25;
33、步骤206,迭代次数加1,当满足终止条件时,整个优化过程结束。
34、第二阶段中,步骤202使用反向传播训练神经网络的详细过程如下:
35、步骤a,模型确定,根据输入和输出向量确定输入层单元数量n1、隐藏层层数m、隐藏层单元数量n2和输出层单元数量n3,将输入层作为第0层,隐藏层为1到m层,输出层为m+1层,设置输入层单元数量为13,隐藏层数为2,隐藏层的单元数量为14,输出层的单元数量为1;
36、第n层输出向量表示为则第n层的第i个单元的计算公式为:
37、
38、g(z)为激活函数,为第n层第i个单元的特征参数向量,为第n层第i个单元的偏置值,为第n-1层输出向量,输出层的输出为预测信任分a[m+1];
39、步骤b,模型编译,设置损失函数,第j个样本的损失函数为:
40、
41、代价函数为:
42、
43、sum为训练子集中的样本数量,是第j个样本的预测信任分,yj是第j个样本的真实信任分,是特征参数向量,是偏置值向量;
44、步骤c,模型训练,通过反向传播更新权值,通过以下方法,使得代价函数值最小(jmin),
45、重复{
46、
47、
48、}直到收敛。使用第二阶段优化后选择性集成权值,建立最终的选择性神经网络集成学习模型,上述第三阶段是将测试集中的每一个请求记录作为模型的输入,模型输出即为预测的信任分。
49、上述方法适用于零信任网络架构。
50、上述采用选择性集成学习,在选择性神经网络集成模型中,使用反向传播神经网络(bpnn)作为基本分类器。d个基学习器被选择性的集成在一起用来预测访问请求活动的信任分。由于不同的基学习器具有不同的学习能力,通过设置不同的权重来选择性地将它们组合起来,以使学习能力达到最强。这些权重是在验证集的指导下使用pso搜索算法获得的,即采用粒子群优化算法(pso)获得最优聚合权向量。
51、本发明未提及的技术均参照现有技术。
52、本发明基于机器学习的零信任网络信任评估方法,适用于零信任网络架构的信任评估方法,该方法采用选择性集成学习,其中使用反向传播神经网络(bpnn)作为基本分类器,采用粒子群优化算法(pso)获得最优聚合权向量,实现对访问主体可信分的预测,具有更高的鲁棒性;采用模糊线性回归的方法,选择用户和设备的相关属性作为信任特征,然后,使用训练数据集建立模糊线性回归方程来表达信任特征和可信分之间的函数关系,输入为数值数据,模型的输出是模糊数据;解决了“零知识”和“冷启动”问题,拥有更好的准确性。
- 还没有人留言评论。精彩留言会获得点赞!