基于深度强化学习的无线传感网络路由算法的自适应选择方法
本发明属于通信,更为具体地讲,涉及一种基于深度强化学习的无线传感网络路由算法的自适应选择方法。
背景技术:
1、无线传感网络(wireless sensor network,wsn)作为物联网(internet ofthings,iot)的重要组成部分,主要负责收集数据,并将传感数据转发到核心网进行进一步处理。无线传感网络中的传感器节点通常被部署在无人看管的地方,由电池供电自主运行,用来执行具有一定性能要求的任务,例如实时数据收集等。由于用户期望更多的数据和更快的收集速度,因此,能量效率和服务质量(quality of service,qos)都是无线传感网络中的关键指标。
2、在无线传感网络中,传感器节点的能量主要消耗在无线通信过程中。为了提高能量效率和延长网络存活时间,一系列考虑能量指标的路由算法被提出,例如ear、mldr和ebrp等。另一方面,随着视频和图片传感器的发展,新兴的应用对相应的业务传输提出了很高的qos要求。为了确保qos流量的快速转发,一系列考虑qos指标的路由算法被提出,例如speed、ear+等。
3、由于能量效率和qos的优化方向不一致,大多数算法倾向于优化单个目标,而在另一个目标上表现较差。例如,能量感知路由为了追求更高的节点能量效率,倾向于选择剩余能量多的节点进行中继,更均匀地消耗网络中各个传感器节点的能量。然而,这会导致在高能量节点处发生拥塞,进而导致丢包率和端到端时延增加。
4、在无线传感网络中,路由决策是基于当前的系统状态(例如传感器节点的剩余能量和排队状态)做出的。同时,通过决策数据包的汇聚路径,路由决策也会影响新的系统状态。因此,系统状态是动态变化的,这对路由算法的设计提出了很高的适应性要求。
5、现有方法无法兼顾多个优化目标和无法快速适应不断变化的环境,也就无法实现能量效率和qos指标的双重优化。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于深度强化学习的无线传感网络路由算法的自适应选择方法,通过自适应地选择路由算法,响应系统状态的动态变化,以实现能量效率和qos指标的双重优化。
2、为了实现上述发明目的,本发明基于深度强化学习的无线传感网络路由算法的自适应选择方法,其特征在于,包括以下步骤:
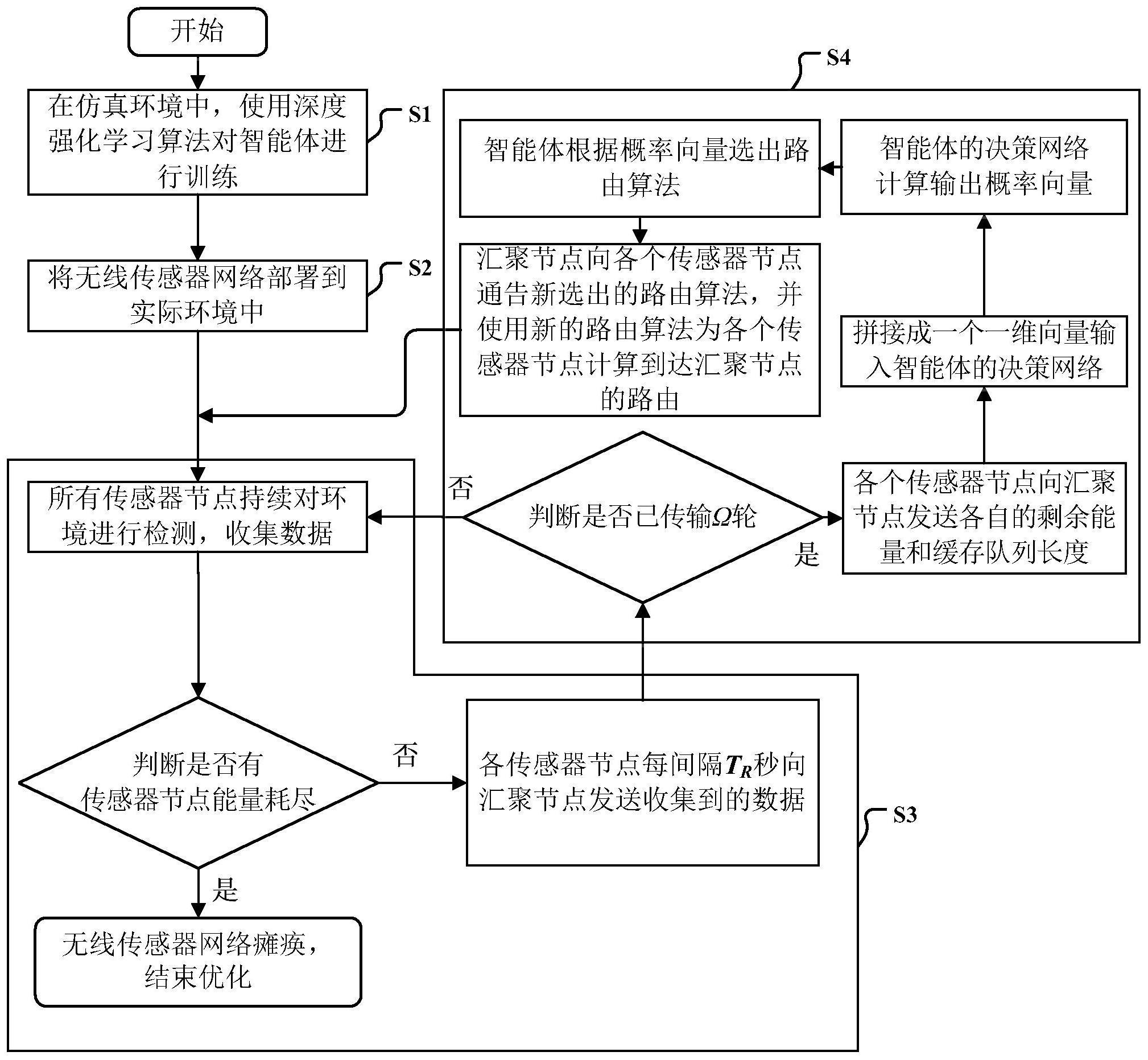
3、(1)、在仿真环境中,使用深度强化学习算法对智能体进行训练
4、根据实际部署,在仿真环境中建立一个由a个电池供电的传感器节点n1,…,na以及一个连接电源的汇聚节点n0构成的无线传感网络,其中,汇聚节点n0位于原点处,按照实际环境部署位置,在仿真环境中部署各个传感器节点ni,i=1,…,a以及汇聚节点n0;
5、对于传感器节点ni,定义其邻居集合为在传感器节点ni通信范围的所有其它节点的集合,所述的其它节点为传感器节点或汇聚节点n0;
6、所有传感器节点ni,i=1,…,a,每tr秒进行一轮数据传输,即每个传感器节点ni,i=1,…,a收集tr秒数据后,将收集到的数据通过多跳路由发送给汇聚节点n0;每个传感器节点ni,i=1,…,a的最大缓存空间为l,传输带宽为w,当传感器节点正在发送数据时,新到达的数据包将会被存储在它的缓存队列中,等待传感器节点空闲时再进行中继,而超出缓存空间的数据包则会被直接丢弃;
7、有b个可选的路由算法m1,…,mb,定义全部路由算法集合为汇聚节点n0上部署一个用于选择路由算法的智能体,每经过ω轮传输进行一次路由算法决策;
8、使用基于演员-评论家(actor-critic)的深度强化学习算法对智能体进行训练:
9、1.1)、在[1,b]范围内随机生成一个整数j,选择路由算法mj作为路由算法,并根据各个传感器节点ni,i=1,...,a的邻居集合计算出每个传感器节点ni,i=1,...,a到达汇聚节点n0的路由;
10、1.2)、根据传感器节点ni,i=1,...,a部署位置,将邻居信息和路由信息写入各个传感器节点ni,i=1,...,a的配置文件中;
11、1.3)、将各个传感器节点ni,i=1,...,a的位置信息写入汇聚节点n0,对于传感器节点ni,其位置信息为:以汇聚节点n0为原点建立的二维直角坐标系下,传感器节点ni的横纵坐标
12、1.4)、各个传感器节点ni,i=1,...,a持续对环境进行检测并收集数据,每间隔tr秒按照路由信息向汇聚节点n0发送收集到的数据;
13、1.5)、无线传感网络每进行ω轮传输,智能体将会决策出新的路由算法。对于第k次决策,具体的决策过程如下:
14、1.5.1)、各个传感器节点ni,i=1,...,a向汇聚节点n0发送各自的剩余能量和缓存队列长度
15、1.5.2)、汇聚节点n0对每个传感器节点ni,i=1,...,a的剩余能量缓存队列长度和位置坐标利用每一维的最大值进行归一化处理:
16、
17、
18、
19、其中,e为传感器节点的能量最大值,l为缓存队列长度的最大值即最大缓存空间,h、v为横纵坐标最大值;
20、将归一化后的剩余能量、缓存队列长度和位置坐标拼接成一个一维向量输入智能体的决策网络;
21、1.5.3)、智能体的决策网络计算输出概率向量其中,表示在第k次决策中选择路由算法mb的概率,b=1,…,b;
22、1.5.4)、在(0,1]范围内随机生成一个浮点数,浮点数位于概率向量的概率累积分布函数的第s个区间,选择路由算法ms作为新的路由算法;
23、1.5.5)、汇聚节点n0将智能体新决策出的路由算法通告给各个传感器节点ni,i=1,...,a,然后在整个无线传感网络中使用新的路由算法,为各个传感器节点ni,i=1,...,a计算到达汇聚节点n0的路由;
24、1.6)、不断执行步骤1.4)到步骤1.5),直到至少一个传感器节点能量耗尽,此时无线传感器网络瘫痪,然后对智能体的决策网络进行参数更新:将智能体的决策网络作为演员网络,路由算法决策时刻的一维向量作为演员网络、评论家网络的输入,采用基于演员-评论家(actor-critic)的深度强化学习算法进行训练,训练过程中使用的奖励函数rk根据无线传感器网络的路由性能指标:传感器节点能量消耗、平均端到端时延和丢包率进行计算,具体计算公式为:
25、
26、
27、
28、其中,表示第k次路由算法决策与第k+1次路由算法决策之间,所有传感器节点消耗的总能量,表示第k次路由算法决策与第k+1次路由算法决策之间,汇聚节点收到的所有数据包的平均端到端时延,表示第k次路由算法决策与第k+1次路由算法决策之间的丢包率;ε、dmmin和dmax是用于归一化的常数;是反映能量效率指标的奖励值,是反映qos指标的奖励值,ω是奖励值和奖励值这两部分奖励值的权重系数,根据特定的应用场景和用户偏好进行设置,对于qos应用,ω设置得偏小一些,对于非qos应用,ω设置得偏大一些;
29、1.7)、将各个传感器节点ni,i=1,...,a的能量恢复为100%,重复步骤1.1)到步骤1.6),不断对演员和评论家网络进行网络权重的更新,直至收敛;
30、(2)、将无线传感器网络部署到实际环境中
31、按照步骤1.1)-1.3)的方法进行处理,然后根据各个传感器节点ni,i=1,...,a以及汇聚节点n0的部署位置在实际环境中进行部署,其中,汇聚节点n0上部署一智能体,其决策网络为步骤(1)训练获得的智能体的决策网络;
32、(3)、所有传感器节点ni,i=1,...,a持续对环境进行检测并收集数据,并且每间隔tr秒按照路由信息向汇聚节点n0发送收集到的数据;
33、(4)、传感器节点ni,i=1,...,a每进行ω轮传输,汇聚节点n0上的智能体按照步骤1.5)的方法决策出新的路由算法,为各个传感器节点ni,i=1,...,a计算到达汇聚节点n0的路由。
34、本发明的发明目的是这样实现的:
35、本发明基于深度强化学习的无线传感网络路由算法的自适应选择方法包括仿真环境中使用深度强化学习算法对智能体进行训练以及在实际环境中利用汇聚节点n0上智能体的决策网络决策出新的路由算法两个部分。具体为在执行无线传感网络数据收集的过程中,部署在汇聚节点上的智能体将各个传感器节点的位置、剩余能量和缓存队列长度归一化后输入决策网络,对路由算法进行决策;考虑到传感器节点能量受限,新决策出的路由算法,由能量和计算资源充裕的汇聚节点告知网络中的各个传感器节点。考虑到由于转发的数据量不同,传感器节点的能量消耗速率和排队状态也不同,所以路由算法决策采用在线的方式,在节点状态的相对变化达到一定程度后,智能体将再次进行决策,选择新的路由算法。
36、同时,本发明基于深度强化学习的无线传感网络路由算法的自适应选择方法还具有以下有益效果:
37、1、本发明设计了一种路由算法的自适应选择方案,能够智能地选择不同的路由算法,快速响应系统状态的动态变化;
38、2、本发明设计了从网络部署到网络瘫痪过程中的在线决策方案,能够随着传感器的能量和排队状态变化,为其提供适时的路由算法调整,实现能量效率和qos的双重优化;
39、3、本发明运用深度强化学习方法解决路由算法的自适应选择问题,与单一路由算法相比,在网络存活时间、平均端到端时延和丢包率等指标上可以获得更好的性能;
40、4、本发明对可选的路由算法并无特别限制,具有很强的可扩展性。
- 还没有人留言评论。精彩留言会获得点赞!