音频数据处理方法、装置及电子设备与流程
本技术属于语音处理,尤其涉及一种音频数据处理方法、装置及电子设备。
背景技术:
1、配音是视频制作过程中的一个重要环节。随着人工智能(artificialintelligence,ai)的不断发展,目前出现了基于人工智能的配音方案,具体的:由一个配音人员针对视频中的多个角色进行配音(可以采用相同的音色),再将该配音人员针对每个角色的配音转换为与该角色对应的音色。在具体应用中,可以由一个配音人员为视频中的多个角色甚至所有角色进行配音。基于人工智能的配音方案能够极大地降低人力成本。
2、但是,基于人工智能的配音方案所生成的音频与基于传统配音方案所生成的音频相比,存在较大差距,用户的听觉感受较差。
技术实现思路
1、为了解决上述技术问题或者至少部分地解决上述技术问题,本技术提供一种音频数据处理方法、装置及电子设备。
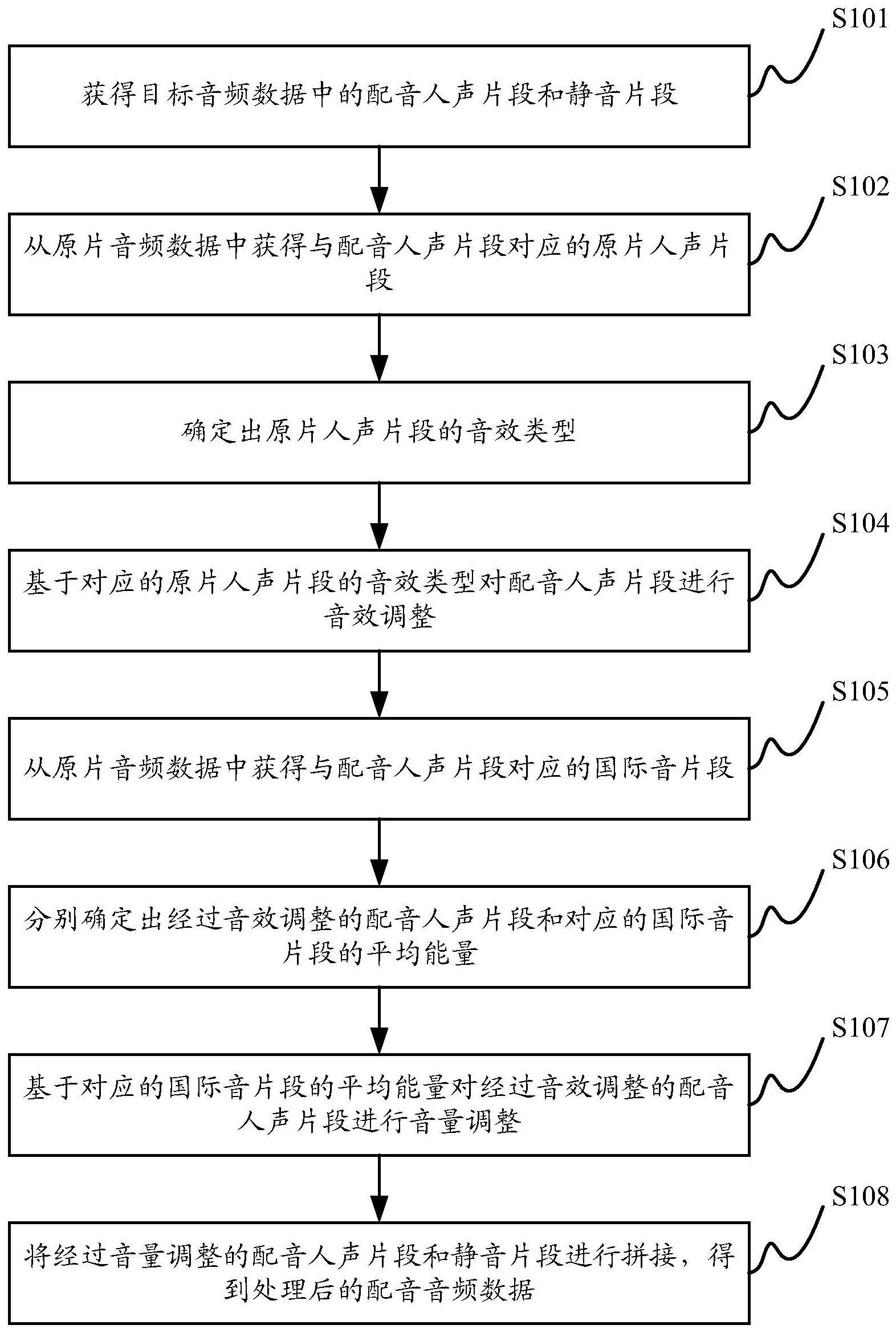
2、第一方面,本技术提供一种音频数据处理方法,应用于电子设备,所述方法包括:
3、获得目标音频数据中的配音人声片段和静音片段;
4、从原片音频数据中获得与所述配音人声片段对应的原片人声片段,其中,所述目标音频数据和所述原片音频数据为同一对象的音频数据,所述原片音频数据为经过后期处理的音频数据;
5、确定出所述原片人声片段的音效类型;
6、基于对应的原片人声片段的音效类型对所述配音人声片段进行音效调整;
7、从所述原片音频数据中获得与所述配音人声片段对应的国际音片段;
8、分别确定出经过音效调整的配音人声片段和对应的国际音片段的平均能量;
9、基于对应的国际音片段的平均能量对所述经过音效调整的配音人声片段进行音量调整,以使得调整后的配音人声片段的平均能量高于对应的国际音片段的平均能量;
10、将经过音量调整的配音人声片段和所述静音片段进行拼接,得到处理后的音频数据。
11、可选的,所述基于对应的原片人声片段的音效类型对所述配音人声片段进行音效调整,包括:
12、获得所述原片人声片段的音效类型对应的参数配置模板,所述参数配置模板包括均衡器参数和/或混响器参数;
13、按照所述参数配置模板中的参数对所述配音人声片段进行调整。
14、可选的,所述基于对应的国际音片段的平均能量对所述经过音效调整的配音人声片段进行音量调整,包括:
15、计算所述国际音片段的平均能量和预设增量的和值;
16、如果所述和值大于或等于能量门限值,则将所述和值作为目标值,如果所述和值小于所述能量门限值,则将所述能量门限值作为目标值;
17、基于所述目标值对所述经过音效调整的配音人声片段进行音量调整。
18、可选的,所述基于对应的国际音片段的平均能量对所述经过音效调整的配音人声片段进行音量调整,还包括:
19、确定出所述原片音频数据中国际音数据的平均能量;
20、将所述原片音频数据中国际音数据的平均能量确定为所述能量门限值。
21、可选的,所述获得目标音频数据中的配音人声片段和静音片段,包括:
22、对所述目标音频数据进行语音活动性检测,以获得配音人声片段和静音片段。
23、可选的,所述从原片音频数据中获得与所述配音人声片段对应的原片人声片段,包括:
24、从所述原片音频数据中获得目标角色的人声时间序列,所述目标角色为所述配音人声片段对应的角色;
25、对所述目标角色的人声时间序列进行语音活动性检测,以获得所述目标角色的原片人声片段集合;
26、基于所述配音人声片段的起始时刻和结束时刻,在所述目标角色的原片人声片段集合中获得对应的原片人声片段。
27、可选的,所述从所述原片音频数据中获得目标角色的人声时间序列,包括:
28、从所述原片音频数据中获得人声数据;
29、对所述人声数据进行分割聚类,以得到所述目标角色的人声时间序列。
30、可选的,所述从原片音频数据中获得人声数据,包括:
31、在所述原片音频数据包括对话音轨数据的情况下,获得所述对话轨数据作为人声数据;
32、在所述原片音频数据未包含对话音轨数据的情况下,对所述原片音频数据进行盲源分离处理,以得到人声数据。
33、可选的,所述从原片音频数据中获得与所述配音人声片段对应的国际音片段,包括:
34、从所述原片音频数据中获得国际音数据;
35、获得所述配音人声片段的起始时刻和结束时刻,从所述国际音数据中获得位于所述起始时刻和结束时刻之间的国际音片段。
36、第二方面,本技术提供一种音频数据处理装置,包括:
37、第一音频数据处理模块,用于获得目标音频数据中的配音人声片段和静音片段;
38、第二音频数据处理模块,用于从原片音频数据中获得与所述配音人声片段对应的原片人声片段,其中,所述目标音频数据和所述原片音频数据为同一对象的音频数据,所述原片音频数据为经过后期处理的音频数据;
39、音效类型确定单元,用于确定出所述原片人声片段的音效类型;
40、音效调整模块,用于基于对应的原片人声片段的音效类型对所述配音人声片段进行音效调整;
41、国际音片段获取模块,用于从所述原片音频数据中获得与所述配音人声片段对应的国际音片段;
42、平均能量获取模块,用于分别确定出经过音效调整的配音人声片段和对应的国际音片段的平均能量;
43、音量调整模块,用于基于对应的国际音片段的平均能量对所述经过音效调整的配音人声片段进行音量调整,以使得调整后的配音人声片段的平均能量高于对应的国际音片段的平均能量;
44、拼接模块,用于将经过音量调整的配音人声片段和所述静音片段进行拼接,得到处理后的音频数据。
45、第三方面,本技术提供一种电子设备,包括处理器和存储器;
46、所述存储器,用于存储程序;
47、所述处理器,用于执行所述程序,实现上述任意一个方法的各个步骤。
48、由此可见,本技术的有益效果为:
49、本技术公开的音频数据处理方法、装置及电子设备,获得目标音频数据中的配音人声片段和静音片段,从原片音频数据中获得与配音人声片段对应的原片人声片段和国际音片段,之后确定出原片人声片段的音效类型,基于对应的原片人声片段的音效类型对配音人声片段进行音效调整,分别确定出经过音效调整的配音人声片段和对应的国际音片段的平均能量,基于对应的国际音片段的平均能量对经过音效调整的配音人声片段进行音量调整,以使得调整后的配音人声片段的平均能量高于国际音片段的平均能量,之后将经过音量调整的配音人声片段和静音片段进行拼接,得到处理后的音频数据。本技术公开的技术方案,参考原片音频(人声具有与场景匹配的音效)对目标音频中人声的音效和音量进行自适应调整,这使得处理后的音频数据中的人声具有与场景匹配的音效,并且处理后的音频数据中的人声的音量大于国际音的音量,这使得用户在观看视频的过程中能够清楚地听到配音中的人声,且人声的音效与场景匹配,从而带给用户更好的听感。
- 还没有人留言评论。精彩留言会获得点赞!