一种低延迟密码算法LLBC的实现方法及系统
本发明属于信息安全中分组密码,具体涉及一种低延迟密码算法llbc的实现方法及系统。
背景技术:
1、分组密码作为主流的信息加密技术,在网络与信息安全领域发挥着重要的作用。为满足资源受限环境下的安全需求,特别是实时、快速响应多场景(终端)的需求(比如实时认证、内存加密、车联网设备及新型电网智能巡检机器人等),轻量级、低延迟密码算法的发明设计应运而生。
2、过去十余年,学术界已经有许多著名的低延迟密码算法的设计实例,比如prince,princev2,mantis,qarma,midori,speedy,scarf,lllwbc和sand。在ches 2012上,学者通过对比多个轻量级分组密码的延迟属性得到结论:在延迟性需求方面,使用密码学性质较优的4比特或3比特s盒通常比大尺寸密码s盒更有优势。在asiacrypt 2012上,一个低延迟分组密码prince被提出。该算法具有64比特数据分组长度和128比特的密钥长度;算法需要迭代12轮。prince通过一个具有反射属性的函数α来达到加解密相似的目的。随后,在prince的基础上,princev2被提出。该密码通过对prince密钥编排和中间的轮函数进行修改,确保更加安全。在princev2的设计文档中还提供了与可调的分组密码mantis,qarma和低能耗的分组密码midori对比,结果表明:prince和princev2仍具有低延迟性优势。实际上,可调分组密码mantis和qarma增加了额外的调柄输入,所以会增加它们花销的电路深度;而midori算法的设计并不是以低延迟属性为设计目标的,尽管它的s盒被精心设计来提供尽量小的延迟。最近,zhang等人在inscrypt2022上提出一种轻量级低延迟分组密码,即lllwbc。lllwbc是基于广义feistel结构而设计,具有64比特的数据分组长度和128比特的密钥长度,算法总轮数为21轮。lllwbc采用了prince密码中的α函数,并通过巧妙的选择轮函数和密钥编排来保证α的反射特性,从而使得lllwbc能够在硬件上高效实现。chen等人在deigns,codes and cryptography 2022上提出的sand是基于feistel结构设计的轻量级分组密码,由于它在轮函数当中采用了类似于比特切片并行的思想使得其成为软硬件平台上实现效率最快的分组密码之一;但由于sand的非线性层采用了较为简单的and-rx运算使得其需要增加多轮迭代来保障整个密码的安全性;比如sand-64和sand-128就分别需要迭代48轮和54轮,这非常不利于算法的延迟。
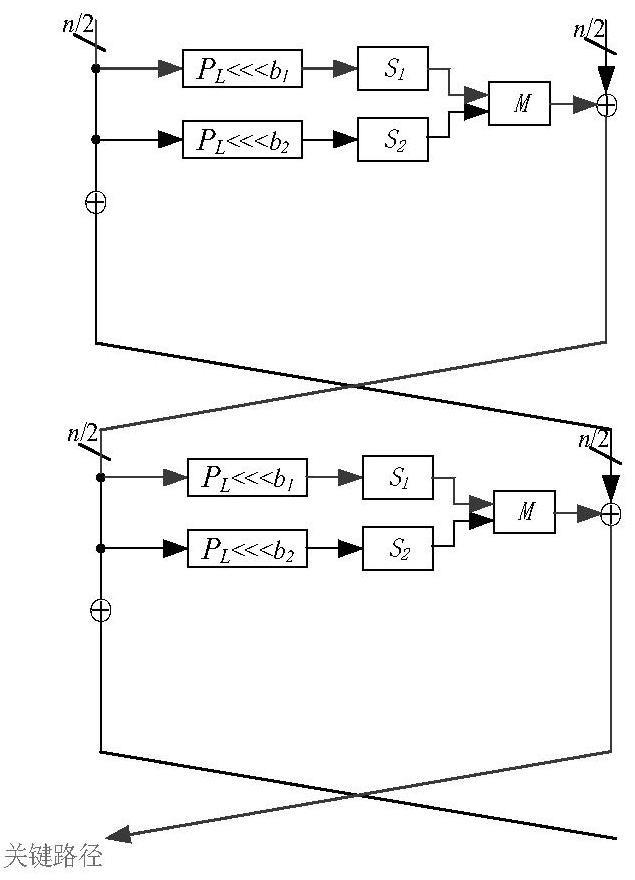
3、在近年的研究中已经出现了在延迟方面比prince更好的密码算法,比如在tches2021上,speedy密码算法被提出。该算法通过使用逻辑门or,and,and inv/not(oai)来构建一个超低延迟的6比特s盒,从而使算法整体的延迟能够比prince更低;又比如scarf密码算法通过采用misty结构并结合speedy的oai门来设计低延迟的6比特s盒,从而使得算法整体的延迟仅仅为prince的一半。
4、然而,纵观已有的研究结果,我们发现这些低延迟密码几乎都是基于spn结构(或广义feistel结构)进行设计,比如prince、mantis、lllwbc等。因此,如何在标准的feistel结构上设计低延迟密码算法是本发明亟需解决的技术问题。
技术实现思路
1、本发明为了解决上述现有技术问题,提供一种低延迟密码算法llbc的实现方法及系统,所述方法采用传统的feistel结构实现低延迟密码算法,将轮运算与传统feistel结构相结合来使得llbc获得具有竞争力的延迟属性,同时解密无需消耗任何硬件资源;其中,通过搜索4比特的s盒中门深度为3且等效门数在20以内的两组s盒进行s1盒置换和s2盒置换,比现有技术中最优的midori密码的4比特s盒更优,基于s1盒和s2盒进行轮运算,实现并行执行策略,使得本发明技术方案提供的密码算法更具超低延时效果。
2、一方面,本发明技术方案提供的一种低延迟密码算法llbc的实现方法,包括以下步骤:
3、步骤1:获取128比特明文作为待加密数据或密文作为待解密数据;
4、步骤2:若是加密运算,利用子密钥对所述待加密数据执行r轮加密运算得到密文;若是解密运算,利用子密钥对所述待解密数据执行r轮解密运算得到明文;
5、其中,按照从高到低的顺序先将所述待加密数据均分为两部分li,ri,每一轮加密运算为:对数据li并列执行循环位移加s1盒置换、循环位移加s2盒置换的结果作为m函数的两个输入得到输出m,再利用输出m、子密钥以及数据ri进行异或运算更新li+1,以及利用数据li、子密钥、轮常数进行异或运算更新ri+1;若当前轮次i并非第r轮,则进入下一轮的加密运算;
6、s1盒和s2盒是通过搜索4比特的s盒中门深度为3且等效门数在20以内的两组s盒;
7、所述解密运算为所述加密运算的逆序执行,且r轮解密运算的子密钥使用顺序与r轮加密运算的子运算的顺序相反。
8、本发明技术方案以遍历搜索4比特的s盒中门深度为3且等效门数在20以内构造出两个s盒,其中,门深度用于衡量延迟标准,因此,构造的两个s盒自身的延迟性能就优于比现有的midori的s盒。其次,如图5所示,本发明引用两个s盒并行进行置换,即两路径并行执行,进而实现了超低延迟。此外,相较于一般在非线性部件都只用一个s盒的现有技术,本发明技术方案的密码算法中使用了两个并行4比特s盒,在做安全性分析时将两个并行4比特s盒桥接起来视为一个超级s盒来做分析,增加密码算法安全性。
9、进一步可选地,s1盒置换和s2盒置换对应的置换表如下:
10、
11、式中,采用了4*4的s盒(16进制),即x为0-f中任意一个数时,根据上表将其替换为下方对应的s(x)值,s1(x)为s1盒置换的输出,s2(x)为s2盒置换的输出。
12、对数据li执行两次循环位移后的数据li1、li2按照所述置换表分别执行s1盒置换、s2盒置换,具体为:
13、将数据li1、li2均划分为十六个4比特,再合并为半字节;
14、利用所述半字节查询所述置换表得到置换结果。
15、进一步可选地,s1盒置换和s2盒置换对应s盒门深度为3,等效门数为18.5。
16、进一步可选地,数据li+1以及ri+1的更新公式如下:
17、
18、
19、式中,rk'i[64]、rki[64]均为当前轮次i的子密钥rki的64比特数据;rci为当前轮次i的轮常数。
20、进一步可选地,所述方法还包括:搜索4比特的s盒中门深度为3且等效门数在20以内的两组s盒,具体如下:
21、s1)寻找到满足双射的所有4比特s盒,并通过quine-mccluskey算法计算每个输出状态位的乘积和sop、负乘积和not-sop得到各自深度,从中筛选出对门深度为3且等效门数在20以内的4比特s盒;
22、其中,sop和not-sop均为数字电路逻辑中的专业术语;即加入了门深度筛选条件,从而筛选出所需的4比特s盒。
23、s2)验证s1中筛选的s盒是否满足额外的密码约束,若均不满足,增加逻辑运算,返回s1;若满足,执行s3;其中,额外的密码约束指代安全性上的约束,譬如差分均匀度和线性逼近等指标,但是不局限于举例的指标。
24、s3)对s2中筛选的s盒进行加密属性检测,进而筛选出本发明所需要的s盒。
25、其中,若存在满足加密属性检测的多个s盒,则优先考虑深度和硬件面积最低的s盒;若s2和s3只存在满足要求的1个s盒,则另外的s盒优先考虑深度或者增加逻辑运算来挑选第二个s盒。两个s盒是不同的,即不使用两个相同的s盒。
26、进一步可选地,所述m函数的执行过程为:
27、a)将s1盒置换和s2盒置换的结果作为m函数的两个输入ml、mr,再执行然后将得到的m'r循环左移b1比特,即m”r=m'r<<<b1;
28、b)先将m”r与ml进行异或运算,即再将m'l进行循环左移b2比特得到m”l=m'l<<<b2;
29、c)先将m'r与m”l进行异或运算,即再将m”'r进行循环左移b1比特得到m””r=m”'r<<<b1;
30、d)将m'l与m””r进行异或运算,即再将m”'l进行循环左移b2比特得到m””l=m”'l<<<b2;
31、e)将m”'r与m””l进行异或运算,即
32、f)最后m”'l与m””'r进行异或运算得到所述输出m,即
33、进一步可选地,r轮加密运算的子密钥对应的编排更新过程如下:
34、首先,将初始密钥k分为两组数据k0,k1,即k=k0||k1;再基于更新函数更新ki;
35、其中,更新函数为:rci为当前轮次i的轮常数,(g4)2(ki+1)表示ki+1在g4函数中运行两次,所述g4函数由循环移位和异或运算所组成;
36、然后,子密钥rki从ki中加载得到,具体如下:
37、若初始密钥k的长度为128比特,
38、若初始密钥k的长度为256比特,
39、本发明技术方案为了使硬件成本和延迟属性最小化,llbc的密钥编排仅通过移位与异或操作来实现,使用移位操作其面积和延迟等硬件开销几乎为零。虽然密钥编排中没有s盒和矩阵不能保证完全扩散属性,但在轮函数中每个分支引入两个不同的密钥编排可以增加密钥恢复攻击的难度。
40、进一步可选地,ki+1在g4函数运行的过程如下:
41、首先,将ki+1均分为四等份:和
42、然后,将k[3]循环左移b3比特后与x[1]进行异或运算的结果赋值给x'[3],即以及将x[2]循环左移b4-bit后与x[0]进行异或运算的结果赋值给x'[2],即以及赋值:x'[1]=x[3],x'[0]=x[2];
43、其中,x'[3],x'[2],x'[1]和x'[0]为ki+1在g4函数运行一次的结果。
44、llbc密钥版本为256比特的更新过程与上述密钥为128比特大致类似,只有以下几部分不同:
45、a)初始密钥k分为两组128比特的数据k0,k1,即k=k0||k1;再基于更新函数更新ki;
46、b)子密钥rki从ki中加载得到,具体如下:
47、
48、只有a)和b)中的细微区别,其余过程与密钥版本128比特的并无差别。
49、第二方面,本发明技术方案还提供一种基于所述低延迟密码算法llbc的实现方法的系统,包括:
50、获取模块,用于获取128比特明文作为待加密数据或密文作为待解密数据;
51、加解密运算模块,用于若是加密运算,利用子密钥对所述待加密数据执行r轮加密运算得到密文;若是解密运算,利用轮密钥对所述待解密数据执行r轮解密运算得到明文;
52、其中,按照从高到低的顺序先将所述待加密数据均分为两部分li,ri,每一轮加密运算为对数据li并列执行循环位移加s1盒置换、循环位移加s2盒置换;再将s1盒置换和s2盒置换的结果作为m函数的两个输入得到输出m,再利用输出m、子密钥以及数据ri进行异或运算更新li+1,以及利用数据li、子密钥、轮常数进行异或运算更新ri+1;若当前轮次i并非第r轮,则进入下一轮的加密运算;
53、s1盒和s2盒是通过搜索4比特的s盒中门深度为3且等效门数在20以内的两组s盒;
54、所述解密运算为所述加密运算的逆序执行,且r轮解密运算的子密钥使用顺序与r轮加密运算的子运算的顺序相反。
55、第三方面,本发明技术方案还提供一种电子终端,至少包括:一个或多个处理器;以及存储了一个或多个计算机程序的存储器;其中,所述处理器调用所述计算机程序以实现:
56、所述低延迟密码算法llbc的实现方法的步骤。
57、第四方面,本发明技术方案还提供一种计算机可读存储介质,存储了计算机程序,所述计算机程序被处理器调用以实现:所述低延迟密码算法llbc的实现方法的步骤。
58、有益效果
59、本发明技术方案提供的低延迟密码算法llbc采用传统的feistel结构实现低延迟加解密,其中,为了弥补feistel结构与substitution-permutation-network(spn)之间在延迟属性上的差距,在4比特的s盒中门深度为3且等效门数在20以内搜索出两组s盒执行每一轮运算的s1盒置换和s2盒置换,实现并行执行策略,使得本发明所述方法在延迟和最大吞吐率这两项指标表现突出。在安全性方面,本发明技术方案的密码算法中使用了两个并行4比特s盒,在做安全性分析时将两个并行4比特s盒桥接起来视为一个超级s盒来做分析,即这两组s盒将引导得到具有良好的差分和线性性质的超级s盒,增加密码算法安全性。因此,这一设计思想为今后基于feistel结构设计的低延迟密码提供了一种新的思路。安全性分析表明llbc对已知的攻击,如差分密码分析、线性密码分析、不可能差分密码分析和零相关密码分析等,可以达到足够的安全裕度。
- 还没有人留言评论。精彩留言会获得点赞!