基于预执行协议的pre-multiPaxos算法
本发明属于分布式共识算法,具体涉及基于预执行协议的pre-multipaxos算法。
背景技术:
1、paxos算法由leslie lamport最早在1978年提出,是指在允许宕机故障的异步通信网络中,使提案获得最大化通过的分布式共识算法。paxos算法是cft容错的代表性算法之一,该算法致力于保障分布式系统中的各个服务器节点都存储相同顺序的日志。使得一个节点网络中,所有节点在某一个相同的初始状态下,经过一系列操作后,最终所有节点仍然能在一个新的状态达成一致;
2、
3、在paxos算法中,包含三种类型的参与者,分别是提议者(proposer,收到客户端请求,提出命令以表决)、接受者(acceptor,参与投票,选择命令序列)、学习者(learner,不参与投票,接受并执行命令)。
4、根据paxos算法,multi-paxos算法做了两点改进:
5、(1)对于每一个要确定的提案,都将基础paxos算法实例执行一次,形成决议。每个paxos算法实例都对应唯一的实例id;
6、(2)在提议者中选举一个领导人,提案由唯一的领导人提交给接受者。没有提议者竞争,就避免了系统陷入活锁。在系统中,仅有一个领导者有权提交提案,准备阶段就可以跳过,从而提高了效率。
7、预备知识和符号标示
8、函数名()表示节点之间发送的指令或是调用的函数接口。
9、<消息类型,参数……>节点之间发送的消息,包括消息种类与消息参数。
10、在paxos共识算法中,指出只需要达到大多数即可实现一轮共识。这种条件能够成立是在理想条件下,只能保证本轮的共识能够执行,但对于实际运用过程中的paxos算法并不适用。如果一个链中共有2f+1个节点,其中至少f+1个节点处于正确的状态,最多f个节点是错误的。但是在pre-multipaxos共识的过程中,节点不会等待一个指令的共识完成以后再接受新的指令,因为这样会造成极大的延迟。相反,节点会继续接受指令,并执行新的命令。考虑“大多数正确”的临界条件,即f+1个节点处于正确的状态,如果此时原本一个处于正确状态的节点发生了错误,则链上的“大多数正确”的条件就不成立了。此时,正确的f个节点处于正确的状态,f个节点是发生相同的错误,还有1个节点处于另一个错误状态。在这种情况下,则无法顺利实现共识算法,从而必须重新配置整个链上的节点。
11、本发明设计的算法中,链上允许存在的最大拜占庭节点数量为f,但在共识的过程中,需要维护一个共识的安全状态“绝对多数”个节点处于正确状态。
技术实现思路
1、本发明的目的在于提供一种可提高节点执行吞吐率的基于预执行协议的pre-multipaxos算法。
2、本发明提供的基于预执行协议的pre-multipaxos算法,是让节点先预执行接受到的指令,并反馈执行情况,再周期性发起共识,从而增加吞吐率。其中发起共识的周期可以根据应用的需要进行调整,已满足不同的业务环境需求。
3、本发明中,节点由原来的2个变量日志和身份,新增一个变量状态组成;同时为节点的执行日志增加哈希值。通过这样的设置,节点只需要在执行共识的时候,比较需要共识的最后一条日志的哈希值就可以判断执行过程是否出错。
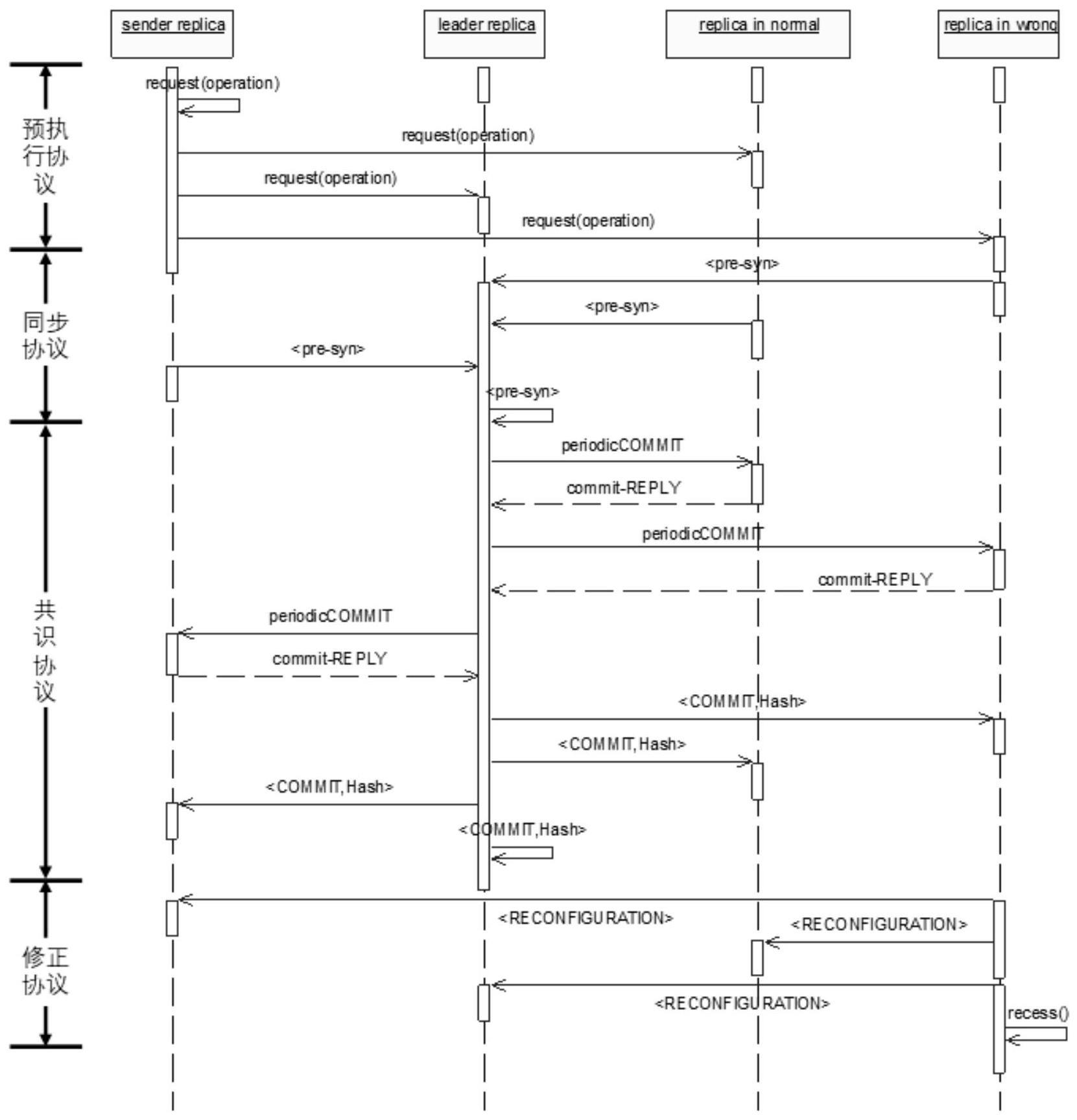
4、本发明中还设计链路协议,包括预执行协议、同步协议、共识协议、修正协议。
5、每一个节点在程序运行期间,经过一系列不同的阶段,并且在不同阶段的节点会专注于一些不同的工作,来满足共识的需要。因此,每一个节点的结构都包含3个变量。
6、状态(status):标明自身所处状态,表明节点当前能接受什么指令。
7、日志(log):记录当前节点按照递增顺序所执行的各项处理。
8、身份(id):标明当前节点的身份,每一个节点都有独一无二的节点身份(id)。
9、(一)关于状态有关概念
10、节点在程序的运行过程的大多数时间里,能正常的接受数据、处理数据,称这状态为一般状态(normal)。
11、当节点在执行修正协议时,该节点状态称为处于修正状态,此处采取共识的原则与一般的paxos算法的原则相同——“大多数”一致性。同时,此时节点将不再接受任何其他指令,并且会将自身的日志状态、信息发送给领导人节点。同样需要注意的是,整个链上的节点并不是每一次共识都会参与。这样的设置主要是为了方便新旧节点随时可以参入或退出链。而且新加入的节点会进入配置状态,它们必定会在下一轮进入修正状态的时候与其他节点达到一致。
12、恢复状态(recovery)以及重配置(reconfiguration)状态,主要用于区块链系统的配置,保证这些状态节点不会造成不必要的共识压力。其中,恢复状态主要发生在某个节点发生宕机,以及其他系统或网络错误时。这样当加入的节点较多的时候,不会对现有区块链系统的共识造成“符合大多数”的压力。重配置状态用于重新配置区块链中的节点,比如某个节点所处的网络状态进行重新配置。这一点要区别于恢复状态,如果直接用恢复状态来进行一次节点的退出以及一次节点的进入,则会导致原本数据对于共识能力的缺失,尤其是当同时出现多个节点需要重配置的时候,极有可能是把多个具有正确状态的节点杀死,相当于自发的发起了一次对链中节点的攻击。
13、(二)关于日志有关概念
14、日志记录的是一连串的由分布式节点执行的操作序列。每一个日志包含三个组成成分:与日志记录有关的哈希值(hash)、日志序列号(seq_num)、日志状态。
15、由于在pre-multipaxos算法下,链上每一个节点之间的交流频率在程序的运行过程中会比一般共识算法副本之间交流的少,因此每一次节点之间进行共识的数据量通常要大得多。为了增加共识的效率,本发明选择利用hash值来实现对以往操作记录的“记忆”,这里对hash算法的要求需要满足伪随机性的要求,即对于相同的输入,生成的结果应该一致。
16、如果:
17、lista,m<operations>=listb,m<operations>
18、则:
19、hash(lista,m<operations>)=hash(listb,m<operations>)
20、其中,lista,m<operations>与listb,m<operations>分别是replicaa和replicab所记录的操作(operations)记录列表,m表示当前考虑的是序列号为m的操作(operations)。
21、这里hash算法需要注意的是:
22、伪随机性,这一点十分重要,必须强调相同的输入应该对应相同的输出,否则算出来的哈希值无法实现对以往数据的“记忆性”。
23、低碰撞概率,但对于碰撞率不要求非常严格,最重要的是满足安全性要求的哈希函数的输出空间。证明如下:
24、即使当hash算法发生碰撞,某一轮执行出现的错误结果且不会被共识机制修复的概率显著。
25、设当进行到第n次共识,链上始终有2f+1个正常节点,则假设剩下的f-1和节点全部发生操作错误,并且在最坏的情况下,发生错误的f-1个节点结果相同,且他们都在同一个输出上发生了碰撞,即:
26、when round=nth:
27、hashquorum,n=hashwrong,n,
28、此时,链中相同hash值大于2f+1,满足链上预执行的安全条件。因此,本轮预执行不会检查出错误。
29、when round=(n+1)th:
30、设发生冲突的平均概率为p,hash值的输出空间为m,碰撞空间为n,则p=n/m。若仅执行一轮就启动了共识协议:
31、
32、因此,当节点执行出现错误且能混在正确结果中的概率为1/m2。其中3f为区块链网络中的节点总数,在sha-256中,输出空间m=2256。此处的哈希值取整数,所以哈希函数的值域是离散型的。最终发生错误的概率与碰撞冲突产生的概率无关,只需要保证哈希函数的输出值域足够充分以及链中的节点数量足够多,则可认为:
33、当输出空间m与节点数量3f满足显著性要求时:
34、
35、然而,以上证明仅仅是证明了发生碰撞的概率不会影响最终区块链达成一致。但当pre-multipaxos发现错误时,纠错所需要消耗的成本是比multipaxos大得多的,这是预执行算法的缺点。因此为了效率,仍然应尽量选取碰撞概率低的哈希算法。
36、每一条日志的结构如下:
37、 <![cdata[序列号seq_num<sub>n</sub>]]> <![cdata[状态status<sub>n</sub>]]> <![cdata[哈希值hash<sub>n</sub>]]> <![cdata[operation<sub>n</sub>]]>
38、其中,hashn=hash(hashn-1||operationn)。由于哈希值的输入包含了上一条数据的哈希值,因此hashn则包含了{operations|i<n}并且纳入了operationn。当需要检查节点执行是否正确时,只需要比较第n条数据的哈希值是否一致即可。
39、日志状态,一般有三种,分别是预执行状态(preexcuted)、未执行状态(unexcute)和已共识状态(committed)。未执行状态是一个临时的中间状态,表明当前日志仅仅是记入了list<operations>,可能尚未执行,考虑到链上个别操作可能所需要的指令发起地与最后工作的开展存在时间差或者网络通信的不稳定性,接受指令与执行之间存在时间差。预执行状态表示该日志所记录的操作已经被节点顺利执行完毕,但尚未在全链网络内进行共识。已共识状态则表明该日志已经经过了全网的共识并且是正确的记录。
40、(三)关于身份有关概念
41、在程序的运行过程中,根据身份标识选择出领导人,领导人在程序的运行过程中发起共识的请求信息,并且收集、处理共识的反馈。同时在发起共识之前,领导人还需要监视链中执行情况是否仍然满足共识的安全条件。领导人节点相较于其余节点应该是平等的,在区块链中如果有特别地位的节点会削弱链的安全性。因此,pre-multipaxos算法中的领导人额外功能仅限于启动各个节点的共识协议。
42、(四)关于预执行协议
43、预执行协议是指节点会在一段时间或周期内先执行、后共识。当一个用户(可以不是领导人节点)端发起一个执行命令的请求时,pre-muiltipaxos程序会将这个请求向其余所有的节点发送,包含请求发起人、以及每一个接收指令的节点的身份标识id以及请求内容。当一个节点收到了自己所需要执行的操作后,只有处于一般状态的节点才会去执行这个命令,并更新自己的日志记录。
44、(五)关于同步协议
45、在执行的过程,由于各个节点之间并没有交流,虽然这极大的有助于资源的节约,但是也增加了链上数据发生错误的可能性。出于这方面考虑,在预执行的过程中,也会伴随着周期性的同步协议的执行。
46、当程序在运行的过程中,节点会接收到一条操作请求,当节点m完成执行后,会将自己的运行结果返回给身份标识id为v的领导人节点,并发送一条同步信息<pre-syn,m,v,hash>,用于表明自己对于这条消息的执行情况。收到同步信息的领导人节点会统计重复次数最多的hash值是否达到了绝对多数,如果达到了绝对多数,则说明此时的链处于共识的安全状态。
47、在预执行的过程中,如果领导人节点统计结果显示为:则会提前发起一次共识协议,来保障链中正确的节点恢复到“绝对多数”的水平。而若无法正确执行共识,则说明链中的节点已经无法实现共识,无法通过共识算法实现链上数据的一致性,可能是发生了系统性错误,需要人为的进行维修。
48、由于各个replica之间并没有交流,虽然这极大的有助于资源的节约,但是也增加了链上数据发生错误的可能性,并且为了修改错误所消耗的成本也会更高。出于这方面考虑,在预执行的过程中,也会伴随着周期性的同步协议的执行,这与一般paxos的共识算法的区别在于节点不必等待领导人你的回应,没有额外的消息延迟。
49、预执行协议与同步协议是本算法最核心的两个协议,预执行协议和同步协议是交替进行的。预执行协议是节点在收到请求时进行相关的执行操作,而不必考虑整个链的状态。同步协议则作为预执行思路的的安全性补充,考虑整个链的状态,以保证各个节点的执行仍然处于“能够达成最终一致性”的安全状态下运行。
50、(六)关于共识协议
51、在pre-multipaxos共识算法的运行过程中,各个节点执行通常是独立的,除了已经进行过共识的日志部分,所以各个节点对于自己运行的结果是未知的。共识协议有个特点:周期性执行以及领导人节点发起。除了节点中的领导人节点会周期的启动共识协议,当链上有查询请求的时候,也会执行一次共识协议。lamport在paxos共识算法中指出只要正确结果能够达到超过一般,即可实现一轮成功共识。但是这种安全条件能够成立只能保证本轮的共识能够执行,对于pre-multipaxos算法并不适用。我们可以设想这样一种临界情况:如果一个链中共有2f+1个节点,其中f+1个节点处于正确的状态,另外f个节点是发生了执行错误的。在这种情况下,multi-paxos算法会按照“大多数”一致的原则,将图1中的3个绿色节点的执行结果同步到链中的所有节点上,所有节点实现一致性。然而在预执行的思路下,如果本算法依然保留这个设定,则这此时领导人节点会认为在当前链上执行状态下,继续预执行是安全的,这5个节点会继续接受新的指令。此时,如果原本正确的绿色节点发生了错误,那么此时链上则会出现3个不同状态的集合,包含2个基于上一轮指令发生错误的错误节点,1个新出错的节点以及2个处于正确状态下的绿色节点。此时,链上的“大多数正确”的条件就不成立了,对于共识机制而言,他便无法分辨应该将何种执行结果共识到区块链网络中。因此,通过上述证明可以得出一个结论:假设共有2f+1个节点在链上,则链上允许存在的最大拜占庭节点数量为f。但在保证pre-multipaxos算法正确性的前提下,需要维护的安全状态,即个节点出于正确的预执行状态下,或称为绝对多数。
52、(七)关于修正协议
53、修正协议旨在安全的链状态下,让执行出错的节点实现对自身操作记录的修改。在运行的过程中,节点的状态会由于操作的错误产生差异,因此在修正协议中,节点会在发现自身节点状态与“绝对多数”不同的时候,修改自己的错误操作,恢复到正确的状态中,从而确保整个程序在运行维持一个正确的进程。本协议的运行设计与其余共识算法相似:所有的节点会停止执行新的请求以及通知执行操作,同样也不会把自己的日志发送给新的领导人。在新的领导人发送新的消息给其他节点时,尚未实现自身消息同步的节点对于剩余节点链有潜在的共识威胁。但对于执行出错的节点而言,他的原因是多样的。在一般区块链网络中,这种差错可能是由于网络中的路由错误,导致消息收发的遗漏,或者相同的操作以一个错误的顺序被执行。
54、当一个节点“意识”到自己存在错误时,首先会将自身节点的状态设置为修正状态“reconciliation”,在这个状态中,节点会如前文所述的那样停止执行链上的各项操作。然后他会广而告之其它节点,避免其余节点继续向他发送消息,造成处理混乱,同时此时他会向其余节点发送开始共识的请求。
55、需要注意的是,虽然经过共识协议后,领导人节点确定已经处于正确状态,至少第s序列号之前的日志都是正确的,但本发明并没有让节点直接向领导人询问共识。因为:
56、(1)在共识算法中,应尽量避免领导人节点拥有特殊的权限,这种特点会使得链的去中心化特点受到威胁,对于链的安全性是非常大的威胁;
57、(2)修正协议的运行过程并不只会发生在共识协议启动之后。当有客户获得授权在共识启动之前,访问了尚未进行共识的日志,尽管希望实际运用中能尽量避免这种情况。但是本文设计的预执行存在的共识滞后性的缺点,因此不得不考虑到偶尔对于时效性的需求。
58、当节点已经确认收到了正确的list<operations>,就会执行算法里的回撤功能,用来实现自身执行结果的回撤以及新列表的合并。
59、本发明提供的基于预执行思路的pre-multipaxos算法,整个过程参见图2所示,具体步骤如下:
60、(一)处于一般状态的节点收到请求时,节点更新自身日志:首先将接收到命令存放在更大的序列号里,随后计算当前序列号日志的哈希值;当一个节点收到自己所需要执行的操作后,只有当节点处于一般状态时,他才会去执行这个命令,并更新自己的日志记录,记录更新完毕后就立马执行;如果执行没有返回错误,则将当前日志记录的状态设置为预执行状态;
61、(二)在在运行过程中,节点接收到一条操作请求,假如当节点m完成执行后,将自己的运行结果返回给身份标识为v的领导人节点,并发送一条同步信息<pre-syn,m,v,hash>,用于表明自己对于这条消息的执行情况;收到同步信息的领导人节点统计重复次数最多的哈希值是否达到了绝对多数;如果达到了绝对多数,则说明此时的链处于预执行的安全状态。
62、具体而言,在预执行的过程中,如果领导人节点统计结果显示为:
63、(1)如果则说明哈希值相同的节点大于绝对多数,则不需要进行任何操作,链中的节点可以继续“预执行”;
64、(2)如果此时链上数据虽然仍能正常实现共识,但应执行一次共识协议,保障链中正确的节点恢复到“绝对多数”的水平;
65、(3)如果f+1≥(list<hash>.max),则说明链中处于正确状态的节点已经低于半数,无法通过共识算法实现链上数据的一致性。
66、(三)每经历一个固定周期,可以是固定的运行时间或者领导人节点每执行k次操作,领导人节点发起一次共识协议的运行请求给所有节点,<periodiccommit,v,s>,其中v表示的是当前领导人的身份id,s表示本轮共识需要共识的最大日志序列号seq_num。如果收到消息的节点所认可的领导人节点不是v(说明此时节点认可的领导人不是最新的),或者节点所处的状态不是一般状态,则接收到共识消息的节点就忽略这个消息,而不参与共识。其余的节点则会在收到这个消息的时候,向领导人节点反馈自己的执行情况<commit-reply,v,s,hashs>,其中v是领导人的身份标识,hashs是节点自身日志执行到序列号s的哈希值。
67、(四)此时,领导人节点收到至少f+1个相同的commit-reply,包括它自身的hashs。此时能够匹配生成的hashquorum,s,则领导人此时就掌握了正确执行后的哈希值。如果与领导人自身匹配,领导人就把所有的日志序列号不大于s的操作序列从预执行(preexcuted)状态设置为已共识(committed)状态。同时,领导人把共识的结果广播给链中的所有节点,包括之前无法参与本轮共识的节点,如前文论述的刚进入链的新增节点以及自身认可的领导人是往届选举出的领导人的节点。
68、领导人节点生成消息<commit,v,s,hashquorum,s>并发送给所有节点。需要注意的是,领导人并不会去统计commit-reply的发送来源,也不会把自身的哈希值发送给任何人。因为,此时领导人的唯一目的是找到链中执行的正确结果,而不必去关心谁对谁错。发生错误的节点应该是自己去纠正错误。其次,领导人自身也可能存在执行错误的情况,所以将自己的哈希值发出去没有任何意义。
69、(五)当其余节点收到这条消息<commit,v,s,hashquorum,s>,他们也对比自身的hashs。如果hashs=hashquorum,s,节点则把所有log序列号小于s的日志状态从预执行(preexcuted)状态设置为已共识(committed)状态。如果节点收到的commit消息出现了不匹配的日志哈希值,那么它会启动修正协议,来修改自己的操作日志。
70、(六)当一个节点“意识”到自己存在错误时,首先将自身节点的状态设置为修正状态(reconciliation),在这个状态中,节点如前文所述的那样停止执行链上的各项操作。然后他会广而告之其它节点,避免其余节点继续向他发送消息,造成处理混乱,同时此时他会向其余节点发送修正的请求消息。需要特别强调的是,如果让领导人来统计正确的list<operations>,然后再让出错的节点去访问领导人节点,这样做的确能保证更高的效率。但是做是不安全的。因为:在共识算法中,应尽量避免领导人节点拥有特殊的权限,这种特点会使得链的去中心化特点受到威胁,对于链的安全性是非常大的威胁。
71、修正协议的运行过程并不只会发生在共识协议启动之后。当有客户获得授权在共识启动之前,就访问了尚未进行共识的日志,此时就需要提前判断一下这个日志的可靠性。尽管本发明设计初衷希望实际运用中能尽量避免这种情况。但是本文设计的预执行存在的共识滞后性的缺点,因此不得不考虑到偶尔对于时效性的需求。
72、(七)因此,节点向链上所有目前处于一般状态(normal)的节点发送启动修正协议的消息<initiate-reconfiguration,n,sa,sb>,其中n是发送消息的节点的身份id,sa是节点n自身的日志中,已经处于committed状态的最大日志序列号,sb则是在本轮实现共识的最大日志序列号。随后,收到消息的节点会将自己的日志的hashb发送给节点n。当节点收到达到f+1个,即“多数正确”的hashb后,便会停止接受消息,开始更改自己的操作日志,执行。需要注意的是,这里同步协议不同,没有采取“绝对多数”。因为这里就只是利用的一轮共识正确即可,不需要考虑在现有状态下一直执行共识,与multi-paxos算法一致。当节点已经确认收到了正确的list<operations>,就会执行算法里的recess(fromnum,tonum,list<operations>)功能,用来实现自身执行结果的回撤以及新列表的合并。
73、(1)节点n会回撤日志序列号处于fromnum和tonum之间的日志,来接受来自其余节点的日志;
74、(2)节点n(replica n)对于收到的日志,只会保留最大的处于已共识状态下的日志序列号。不同一般状态下的节点作出的回答可能存在完成共识的先后次序。因此,即使对于个别延迟的节点而言,对应的hashb所在日志状态可能还是预执行状态,但也不会影响节点n对于收集到的最大序列号的采纳,始终接受链中最大的已共识状态下的日志;
75、(3)此时节点的最大序列号,设为seq_nummax,应满足seq_nummax≤tonum,若seq_nummax<tonum,节点n会检验序列号为seq_nummax+1日志是否仍然满足“大多数”(这里只需要满足“大多数”是因为此处不需要考虑共识)。如果是,则会将该条日志复制到自身log中,并将状态设为未执行状态,并立马尝试执行,成功则记入预执行状态。以上操作会重复至seq_num=tonum或者出现第一个不为大多数的日志时停止;
76、(4)如果停止的时候seq_num<tonum,则说明此时的日志并没有完全生成完全。此时节点则会把原日志剩余日志保留下来,等待下一轮共识。
77、至此,链上所有的节点在预执行协议和同步协议之下,完成了一段时间内的命令执行;同时通过共识协议和修正协议,所有的节点已经在此时实现了所有节点达成一致的要求。
- 还没有人留言评论。精彩留言会获得点赞!