一种面向高性能联邦边缘学习的资源分配和数据选择方法
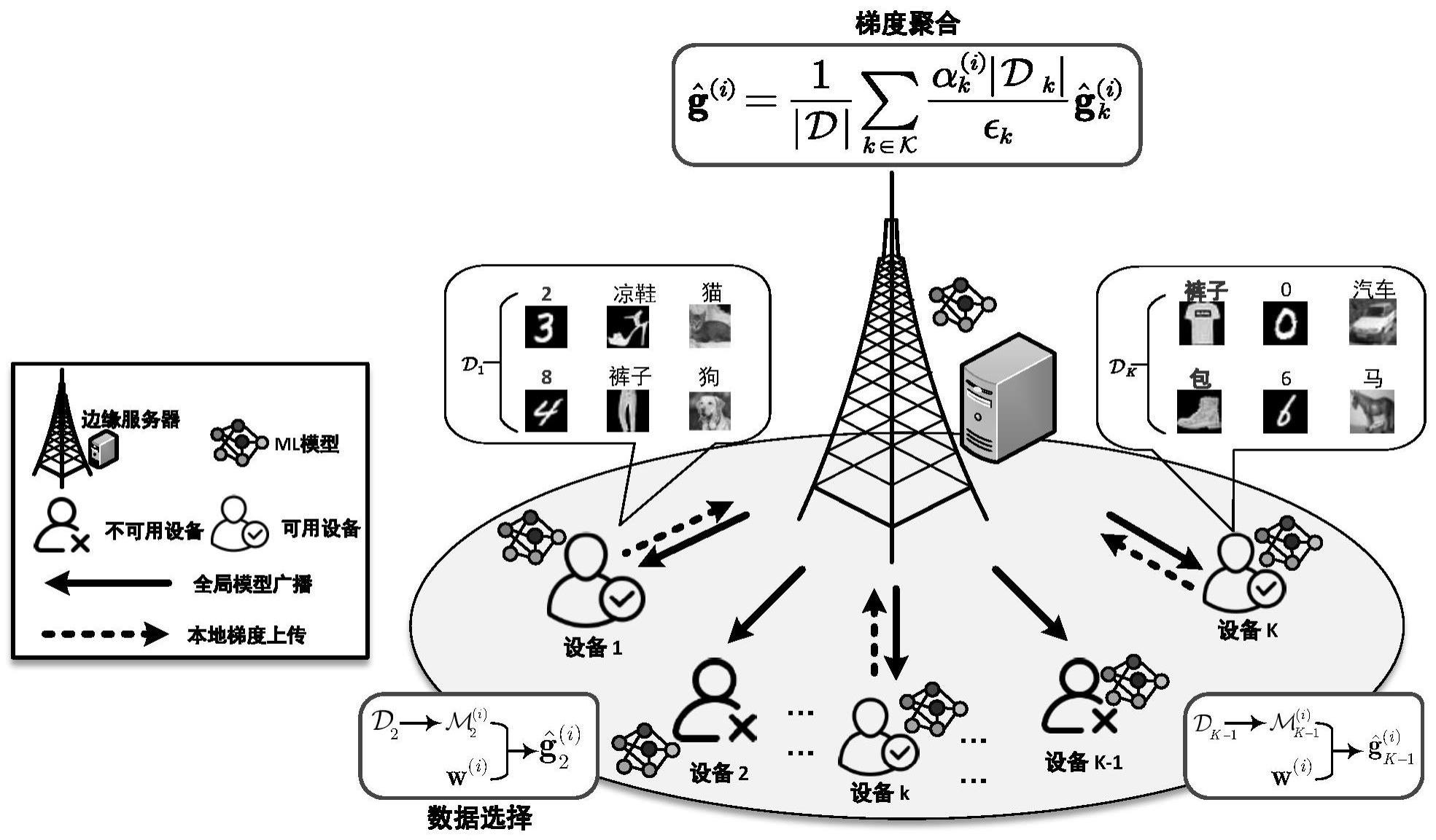
本发明属于机器学习和无线通信,涉及一种面向高性能联邦边缘学习的资源分配和数据选择方法。
背景技术:
1、当前,大量的联网设备将不可避免地在网络边缘产生大量数据,这些数据可以用于扩大机器学习(ml)的应用,例如,用于消费产品设计与推广和科学研究等。传统的ml算法需要将原始数据公开给第三方实体进行模型训练,但这可能会损害数据的隐私。为了解决这一问题,一种称为联邦边缘学习(feel)的位于无线网络边缘的分布式机器学习框架被业界提出,并得到了学术界和产业界的广泛关注。在feel的训练过程中,边缘设备(也称为客户端)需要通过无线信道发送本地的训练结果,例如模型参数或本地梯度,而不是原始数据,从而在参与训练的同时保护其数据隐私。由于网络边缘可用的无线资源(如带宽和时间)受到限制,因此在模型训练时需要为每个设备分配适当的无线资源。此外,在实际操作中,设备所拥有的数据可能会被错误标记,例如,手写的数字“1”可能被标记为“0”,图片“t-shirt”可能被标记为“trouser”。利用这些错误标记的数据训练ml模型将会严重恶化feel的性能,因此,需要在模型训练期间合理选择适当的数据样本。
2、目前已有很多关于feel系统的资源分配的研究,包括通过设计高效的联合设备调度和无线资源分配方案,将所有设备的总能耗降至最低或加速模型训练的收敛;通过联合优化计算资源和通信资源分配,最小化feel系统的训练时间和能量成本的加权和等。在feel系统的研究中,值得关注的是,过高的能量消耗可能会阻碍设备参与模型训练,从而降低feel的性能。因此,有相关研究提出可以通过给予适当奖励给设备以补偿其能量消耗,从而鼓励设备参与模型训练。例如根据所有设备愿意贡献的cpu周期数或可用训练数据样本的数量来奖励设备,贡献越大,奖励越高。
3、上述研究都没有考虑feel系统中是的数据选择设计,所以对应的训练算法可能并不适用于存在错误标记的本地数据的情况。然而,已有研究证明客户端的数据样本质量将直接影响机器学习模型训练的性能,但是当前只有极少研究将feel和数据样本选择结合起来,并且,已有的研究要么忽略了资源分配的问题,要么没有分析模型训练的收敛性,或没有考虑设备可用性对模型训练的影响,所以,亟需一种能同时考虑设备可用性和数据样本选择以及无线资源分配的feel系统训练算法。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种面向高性能联邦边缘学习的资源分配和数据选择方法,解决实际feel系统的资源分配和数据选择问题,为feel系统的实践提供一种设计思路。
2、为达到上述目的,本发明提供如下技术方案:
3、一种面向高性能联邦边缘学习的资源分配和数据选择方法,具体包括以下步骤:
4、s1:构建存在数据样本标签错误和部分设备不可用的feel网络,其中feel表示联邦边缘学习;
5、s2:构建适用于步骤s1构建的feel网络的feel算法,在满足可用设备成功上传本地梯度等约束条件下,建立联合通信资源分配和数据样本选择的优化问题p1;
6、s3:将不能在服务器端求解的原始优化问题等效转换为能在服务器端求解的优化问题p2;
7、s4:将转换后的问题p2等效分解为资源分配子问题p3和数据选择子问题p4,基于匹配理论、凸凹过程和梯度投影等方法分别求解资源分配子问题p3和数据选择子问题p4;
8、s5:采用低复杂度算法,获得存在数据样本标签错误和部分设备不可用的feel场景下的联合资源分配和数据选择方法。
9、进一步,步骤s1中,构建的feel网络包括一个依附于bs的边缘服务器和k个单天线边缘设备,所有的边缘设备用集合表示;对于边缘设备集合中的任意设备k,拥有本地数据集其中,表示第j个d维数据样本,表示数据样本xj的标签;另外,定义集合表示存储在所有边缘设备的总数据集。
10、进一步,步骤s2中,建立的联合通信资源分配和数据样本选择的优化问题p1的数学模型为:
11、
12、
13、其中,针对noma通信系统中的资源分配协议和边缘设备的可用性特点,c1~c4表示资源块分配的约束条件,c5~c6是传输功率分配的约束条件,c7~c8表示边缘设备数据样本选择的约束条件,每个边缘设备选中的数据样本集合一定是其本地数据集合的子集,并且为了保证设备的参与度,每个边缘设备选中的数据样本子集不能是空集;λ∈[0,1]表示一个权重系数,用于权衡feel系统的训练性能和训练成本;表示所有边缘设备的净成本,表示与数据样本选择相关的优化项,表示数据样本选择设计,表示在第i轮训练时边缘设备k从中选择的数据样本集合;和分别表示资源块分配和传输功率分配的设计参数,n表示网络中资源块数量,q表示每个资源块最多能被q个边缘设备同时占用,q≥1;表示设备k的最大传输功率;表示在第i轮训练时边缘设备k的数据传输速率;αk∈{0,1}表示边缘设备k的可用性,其中αk=1表示边缘设备k可以上传本地梯度;l和t分别表示本地梯度的大小和上传梯度的时间。
14、进一步,步骤s2中,所有边缘设备的净成本表示为:
15、
16、其中,ccom(ρ(i),p(i))表示本地梯度成功上传到边缘服务器的通信成本,表示为其中ck表示设备k每消耗一单位能量的训练成本;
17、ccmp表示所有边缘设备执行本地计算的累积净成本,表示为其中ck表示边缘设备k每单位能耗的成本;表示边缘设备k计算所有本地数据样本的梯度所消耗的能量,表示为其中κ是与计算芯片能力相关的能耗参数,fk表示计算需要的cpu周期数量,fk表示设备k的cpu频率;
18、表示集合中所有边缘设备可以得到的总奖励,表示为其中qk表示边缘设备k的每个数据样本奖励。
19、进一步,步骤s3具体包括引入新的优化变量δ(i),将优化问题p1中有关数据样本选择的约束条件等效转换为如下约束条件:
20、
21、
22、进而得到如下优化问题:
23、
24、其中,δ(δ(i))和的具体表达式分别如下:
25、
26、
27、其中,表示用户设备k可以上传本地梯度的概率,qk表示边缘设备k的每个数据样本奖励。
28、进一步,步骤s4具体包括:根据优化问题p2的结构特性和数学性质,将p2等效分解成两个子问题:资源分配子问题p3和数据选择子问题p4,求得p2的低复杂度次优解;首先基于匹配理论和凸凹过程求解资源分配子问题p3,得到资源分配策略(ρ*(i),p*(i)),然后基于优化问题p3的资源分配策略,利用梯度投影方法求得数据选择子问题p4的松弛形式低复杂度次优解最后将松弛解投影到优化问题p4的可行域δ*(i)中,最终得到优化问题p2的低复杂度次优解(δ*(i),ρ*(i),p*(i))。
29、进一步,步骤s5具体包括:首先边缘服务器广播全局模型到边缘服务器,边缘服务器计算本地数据样本梯度范数平方并上传计算结果,然后边缘服务器利用本发明所提方法选择恰当的数据样本并合理分配通信资源,接着边缘设备根据联合资源分配和数据选择策略进行本地梯度计算并上传本地梯度,最后边缘服务器聚合本地梯度并更新全局模型;上述过程一直迭代,直到feel网络训练模型收敛为止。
30、本发明的有益效果在于:本发明考虑到参与feel的边缘设备可能无法参与本地梯度上传和/或边缘设备的本地数据样本可能存在标签错误对feel的性能影响,更具现实意义;此外,本发明提出的低复杂度次优算法在各种网络设置下均显著优于考虑的其他代表性基线方案。
31、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!