一种多无人机间数据智能组织与推送方法
本发明属于人工智能,具体涉及一种多无人机间数据智能组织与推送方法。
背景技术:
1、数据智能推送:主要通过各个无人机携带的机载数据库进行数据的组织、管理、传输等操作,在有效数据准确传输的基础上,降低数据传输量,减少后续决策环节的计算负载和时延,高效完成任务。
2、ooda环:属于循环决策的一个概念,指代“观察o—判断o—决策d—行动a”的循环程序。基于观察,获取相关的外部信息,根据感知到的外部威胁,及时调整系统,做出应对决策,并采取相应行动。
3、强化学习:智能体(agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统rls(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,rls必须靠自身的经历进行学习。通过这种方式,rls在行动-评价的环境中获得知识,改进行动方案以适应环境。
4、演员评论家算法:强化学习中的演员评论家算法(actor-critic,ac)是一种结合了策略梯度方法和时序差分的强化学习方法。演员由策略函数完成,旨在学习一种可能得到尽可能高的回报的策略。评论家则由价值函数完成,旨在对演员,即策略函数所生成的每一个动作生成对应的价值应以评价动作的好坏,指导最终算法的优化过程。
5、目前,随着无人机组网技术的不断发展,无人机被广泛应用于各类协同任务场景中。无人机凭借其相对低廉的制造成本与损失成本,在越来越多的领域代替有人机来完成更加复杂的任务。与此同时,无人机负载的种类、传感器精度不断上升,产生的数据量也呈现出指数增长的趋势。在多无人机协同任务场景下,无人机间数据传输的需求大大增加。然而,一般的无人机平台所能搭载的能源、计算、存贮、网络资源等较为有限,需基于任务需求对于原始数据进行组织之后再发送,采用更先进的智能学习的方法加以控制调整。
6、传统基于事件的数据推送是通过专家预设的事件触发数据推送的规则实现。当数据库中数据达到触发规则时,触发相应的事件机制,启动相应的数据推送服务。这种模式往往依赖专家对数据推送规则的人为定义,难以预先、全面地描述各类事件发生后数据推送的选择,因此不适用于处理复杂的多无人机协同任务场景。
7、本发明从无人机协同任务的实际需求出发,主要针对采用文件系统存储数据时出现的存储混乱、数据类型繁杂难以统一调配使用、无人机信道以及存储资源有限,难以实现更高精度以及更快相应速度的问题所展开。
技术实现思路
1、针对现有技术中存在的问题,本发明的目的在于提供一种基于强化学习的数据智能组织与发送方法,主要通过无人机携带的机载数据库进行数据的组织、管理、传输等操作,结合基于强化学习框架优化目标数据组织方式,在有效数据准确传输的基础上,降低数据传输量,减少后续决策环节的计算负载和时延,高效完成多无人机协同任务。本发明能够有效应对无人机机载存储、计算、交互能力上的局限性问题,高效利用现有资源完成预定任务。
2、本发明的技术方案为:
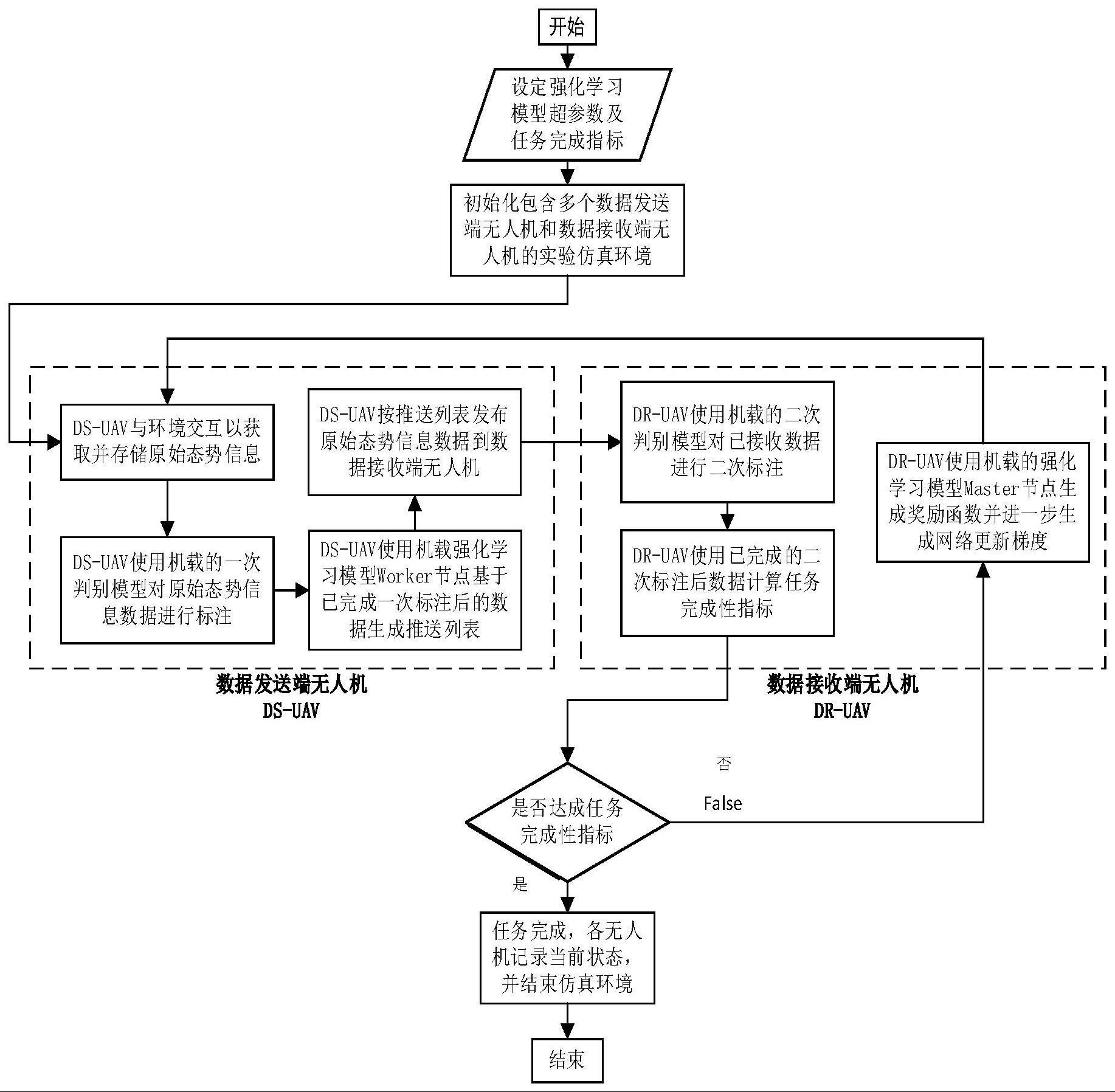
3、一种多无人机间数据智能组织与推送方法,其步骤包括:
4、步骤1):选取多个无人机,将其中至少一无人机作为数据接收端无人机dr-uav,其余无人机作为数据发送端ds-uav无人机;其中数据接收端无人机dr-uav具备同步对接多个数据发送端ds-uav无人机的能力,数据发送端ds-uav无人机具备与其对接的数据接收端无人机dr-uav单线联系的能力;设定强化学习算法的超参数以及任务完成性指标,每一个所述无人机上均配备强化学习算法,所述任务完成性指标为多无人机机群的共同目标;
5、步骤2):初始化数据发送端无人机ds-uav和数据接收端无人机dr-uav的多无人机协同仿真环境,所述多无人机协同仿真环境具备获取数据发送端无人机与数据接收端无人机实时状态的能力;
6、数据发送端无人机ds-uav中的步骤:
7、步骤3):数据发送端无人机ds-uav与所述多无人机协同仿真环境进行交互,存储交互数据作为原始状态信息,然后根据所述原始状态信息形成强化学习算法中的状态空间;
8、步骤4):数据发送端无人机ds-uav使用机载的一次判别模型对所述原始状态信息中的图像数据进行标注,添加图像标注结果至数据存储表中,称为一次判别结果;
9、步骤5):数据发送端无人机ds-uav使用其机载强化学习算法的actor节点,基于步骤4)所述一次判别结果生成推送列表;
10、步骤6):数据发送端无人机ds-uav按照步骤5)所述数据推送列表将待传输数据发送给与其对接的数据接收端无人机dr-uav;
11、数据接收端无人机dr-uav中的步骤:
12、步骤7):数据接收端无人机dr-uav使用机载的二次判别模型对于已接收的数据进行处理,得到二次判别结果;
13、步骤8):数据接收端无人机dr-uav基于该二次判别结果及接收的对应推送数据计算所述任务完成性指标的完成状态;
14、步骤9):由所述任务完成性指标确定当前发送端无人机和接收端无人机协同任务的完成进度情况,进而判断当前任务的是否完成;若当前任务未完成则跳转到步骤10),若当前任务已完成则跳转到步骤12);
15、步骤10):数据接收端无人机dr-uav存储二次判别模型的结果,并基于二次判别结果生成奖励函数;使用其机载的强化学习算法critic节点中的价值网络评判数据发送端无人机推送动作的价值,计算估计优势函数,并基于该优势函数分别计算策略网络和价值网络的反向传播梯度,生成策略网络和价值网络对应的更新梯度;
16、步骤11):数据接收端无人机dr-uav将机载critic节点生成的策略网络和价值网络的更新梯度传送到当前已完成一轮数据推送过程的数据发送端无人机actor节点中,更新其中的策略网络参数和价值网络参数,然后返回步骤3),开始新一轮数据发送端无人机与环境的交互过程;
17、步骤12):当前任务已完成,保存仿真环境中的数据发送端无人机ds-uav和数据接收端无人机dr-uav当前的状态数据;
18、步骤13)当执行一目标任务时,将目标任务信息发送给各无人机,然后利用步骤3)至步骤12)训练后的数据发送端无人机ds-uav和数据接收端无人机dr-uav直接执行该目标任务。
19、进一步的,所述奖励函数为rt=r2ndt+rdt+rtt+rstort;r2ndt为二次判别模型输出的置信度,rdt为位置变化程度,rtt为时间成本,rstort为数据量成本。
20、进一步的,r2ndt=lbdrt,rtt=-0.1,lbdrt表示二次判别模型输出的置信度;ddst为数据发送端无人机推送位置数据在时刻t+1与时刻t时位置变化距离,λd为设定阈值;表示t时刻状态空间实例在数据库中存储所占用的空间大小。
21、进一步的,所述强化学习算法的超参数包括actor节点的轨迹步长l,以及critic节点对应的策略函数的更新步长ηθ、价值函数的更新步长ηψ、奖励折扣因子γ。
22、本技术主要基于强化学习中的演员评论家模型完成状态数据的智能组织与发送。在本技术的设定场景中,数据发送端无人机会存储各个传感器生成的原始数据,并将各数据的关键信息发布到网络中。数据接收端无人机利用发布订阅机制收集与任务相关的关键数据信息,完成数据接收。
23、本方法是首次在无人机协同探测多任务场景下采用智能算法自适应地进行目标数据推送,现有技术大多是通过预设规则、事件推理的方式,因此本方法在集群任务灵活性、效率、资源占用情况等方面均有突破。
24、由于集群协同任务各无人机探测的目标状态数据是丰富多样的,针对下游任务如何进行数据的智能组织是一个np难问题,难以寻求最优解。本方法基于强化学习中的演员评论家算法进行该问题的求解,通过设置与本问题密切相关的动作空间、奖励函数及其算法超参数等将通用算法适配至本技术的研究目标领域中。
25、本发明的优点如下:
26、本技术提出了一种多无人机间数据智能组织与推送方法,通过下游任务的数据需求对目标数据进行智能组织和推送操作,在有效数据准确传输的基础上,降低数据传输量,减少后续决策环节的计算负载和时延,高效完成协同任务。该方法可以解决传统对数据推送规则的预定模式下,难以预先、全面地描述各类事件发生后数据推送的选择,更适用于处理复杂的多无人机协同任务场景。
- 还没有人留言评论。精彩留言会获得点赞!