基于深度生成模型和聚类欠采样的网络入侵检测方法
本发明属于网络入侵检测领域,涉及基于深度生成模型和聚类欠采样的网络入侵检测方法。
背景技术:
1、随着计算机互联网技术的快速发展,互联网开始渗入人类社会的方方面面,网络流量呈现指数级别的增长,其中复杂多样的网络攻击严重威胁到基于互联网建立的能源、医疗、通信和金融等方面的国家网络安全。早期的安全防护手段如访问控制技术、防火墙技术、流量控制技术等随着攻击技术的多样化以及网络规模的扩大已经无法满足当前的需求,例如防火墙技术不能防范网络内部用户的恶意行为并且无法抵抗新型未设置策略的攻击漏洞,属于被动防护策略。网络入侵检测技术通过对网络通讯进行监视,发现可疑行为时可以触发报警信号或者关停网络,因此具有很好的应用前景,网络入侵检测技术也被认为是防火墙之后的第二道安全防线。
2、网络入侵检测技术可以及时地发现并报告被授权的或其他的异常情况,但在实际的网络活动中,正常的流量和行为中占绝对主导地位,异常行为的数量较少,这就造成了入侵检测数据集类别极其不平衡的问题。当使用机器学习算法对不平衡数据集进行分类检测时,不仅训练难度很大,而且以最小化经验风险作为训练目标会使分类模型倾向于多数类,并导致少数类别无法检测或者检测精度较低,从而会显著地降低机器学习算法性能。而且对于入侵检测系统来说,当在真实世界中遇到此类型攻击时,入侵检测系统可能无法准确地给出警告,漏报所造成的危害会远大于虚警所造成的危害。因此,如何在类别分布不均衡的数据基础上有效提高其对少数攻击样本类型乃至未知攻击类型的检测率具有十分重要的意义。
3、为了解决数据极度不平衡的分布问题,研究者们主要从算法和数据层面进行了改进来消除数据不平衡所带来的影响。在数据集分类算法的改进层面,主要包括集成学习和代价敏感学习,集成学习的主要策略是将多个不同的分类器进行线性拼接得到一个强大投票分类器,一个分类器的优点可以帮助弥补另一个分类器的缺点,最终集成的性能优于任何单一成分分类器,能够提高模型的分类精度。常用机器学习分类器应用的算法主要有逻辑回归(logistic regression,lr)、随机森林(random forest,rf)、决策树(decisiontree,dt)和k近邻(k-nearest neighbor,knn)等。代价敏感学习是一种学习范式,它通过在对应算法中加入代价敏感因子以解决不平衡分类问题。数据层面主要通过改变训练集的样本分布来降低或消除不平衡性,主要方法包括欠采样、过采样、过采样与欠采样结合3种方法。通过欠采样的方法对数据集进行处理容易丢失多数类样本信息导致模型对多数类的分类精度下降。过采样是通过对少数类样本进行简单复制达到与多数类样本的平衡,很容易导致过拟合问题。近年来随着深度学习的发展,变分自编码器(variational auto-encoders,vae),生成对抗网络(generative adversarial networks,gan)等深度生成模型在图像、语音和文本生成领域得到广泛应用。如图像处理领域中基于vae的跨域图像生成算法利用编码器对跨域图像进行编码得到其内容属性和风格属性后再进行拼接实现跨域图像过采样。利用条件生成对抗网络(conditional generative adversarial networks,cgan)来近似真实数据分布和以生成器作为过采样算法来生成少数类数据改善数据集不平衡的问题。
4、上述针对数据不平衡情况下分类问题的研究虽然取得了一定成果,但仍有各种不足,特别是针对少数类攻击和未知类型攻击的检测还不够准确,因此设计一种基于深度生成模型和聚类欠采样的网络入侵检测方法对提升入侵检测系统的性能具有重要意义。
技术实现思路
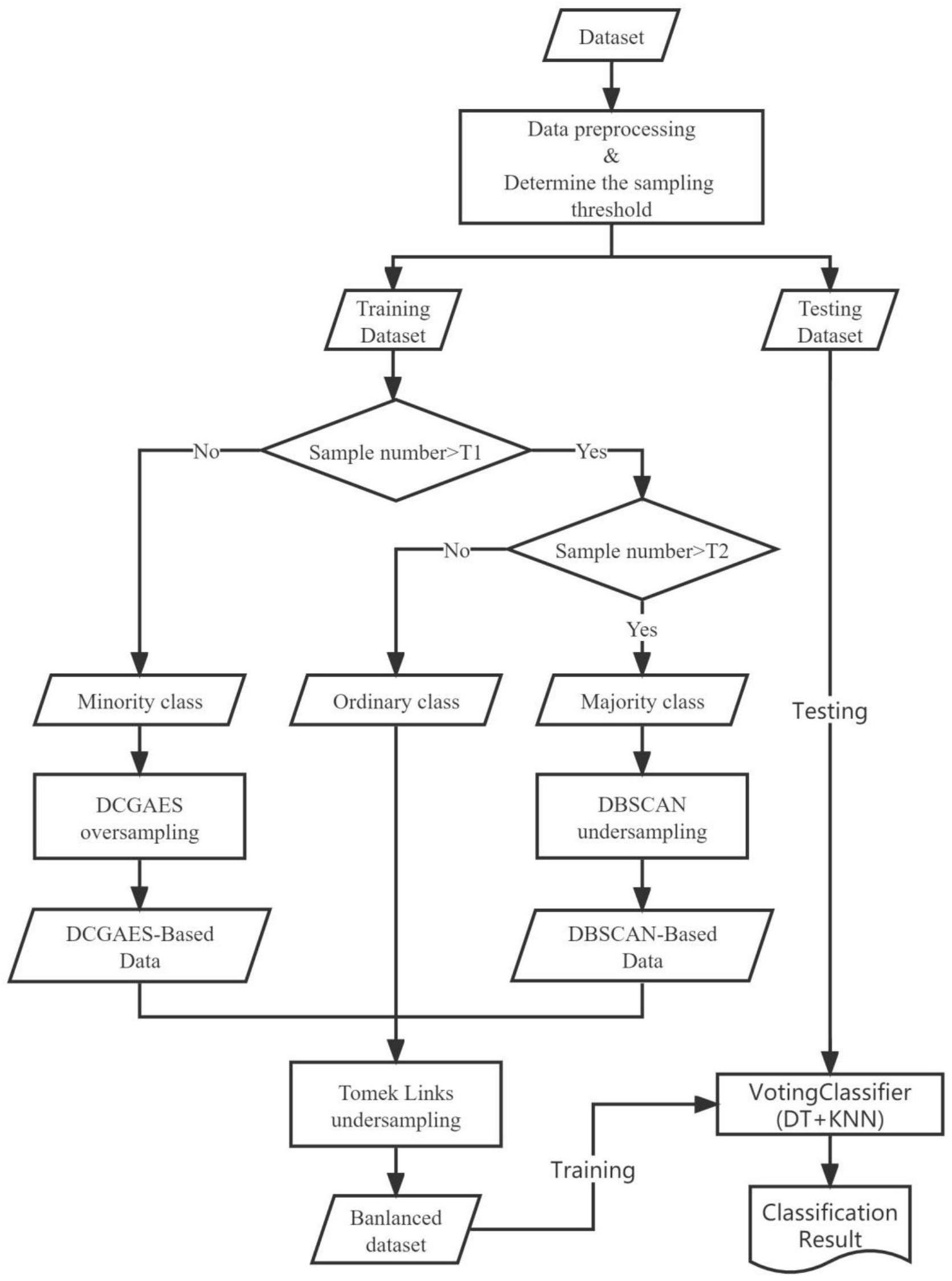
1、鉴于以上问题,本发明的目的在于提供一种基于深度生成模型和聚类欠采样的网络入侵检测方法。本发明重点考虑了入侵检测数据集中数据不平衡的特点,首先对少数类样本使用深度生成模型进行过采样增加少数类样本,对多数类样本采用聚类算法并进行欠采样去除冗余样本,然后在过采样和欠采样后混合的数据集上应用tomek links方法去除噪声样本,最后我们可以得到一个相对平衡且噪声样本较少的数据集。最后用投票分类器(dt+knn)在平衡后的数据集上进行训练,来实现高性能的入侵检测。
2、深度生成模型是对少数类过采样的关键手段,本发明提出一种dcgaes生成模型,dcgaes生成模型是一个高度复杂的结构,具有许多相互依赖的组件。为了确保这些组件之间的无缝相互作用,该模型采用了一个编码器/解码器框架,该框架基于深度卷积生成对抗网络(deep convolutional generative adversarial networks,dcgan)架构,擅长处理复杂的输入样本,从而形成模型的主干并能够生成理想的输出。模型操作的核心是基于smote的过采样方法,它提高了输出的复杂性。此外,dcgaes生成模型包含样本的重建损失和惩罚损失,它们协同工作以优化模型的性能。这些不同的组件协调工作以生成高质量的数据样本,赋予模型一定程度的泛化能力,这在其他生成模型中通常是不存在的。
3、除了生成少数类样本,还需要对数据集中多数类样本进行数据清理,以去除多数类样本中的冗余样本。具有噪声的基于密度的聚类方法(density-based spatialclustering of applications with noise,dbscan)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。因此簇类样本在一定程度上具有相似性,可以对簇内样本按比例进行抽样,在保留簇类样本多样性的同时达到去除冗余样本的目的。
4、去除冗余样本后,还存在类别分布重叠的情况,部分多数类样本嵌入到少数类样本密集的区域,导致边界模糊,分类困难,这种困难程度随着类别不平衡的增大而进一步加剧。tomek links表示不同类别之间距离最近的一对样本,即这两个样本互为最近邻且分属不同类别。这样如果两个样本形成一个tomek links,则要么其中一个是噪声样本,要么两个样本都在边界附近。这样通过移除tomek links就能“清洗掉”类间重叠样本,使得互为最近邻的样本皆属于同一类别,从而能更好地进行分类。
5、训练dcgaes生成模型分为两个部分。一方面,dcgaes的编码器/解码器学习到少数类数据中固有的基本重构模式,对每批样本及重构样本计算重构损失,从而在训练过程中保证生成样本分布不会偏离原始样本分布。另一方面,dcgaes通过排列编码数据的顺序,将方差引入编码/解码过程,解码器可以生成与输入样本不同的示例,但仍会受输入数据的约束。当解码顺序发生改变时,编码后的样本和解码后的样本必然存在一定的差异,这种差异不同于重构样本时的差异,可以使用惩罚损失来表示。
6、结合重构样本的损失函数和引入方差后的惩罚损失函数可以得到总的损失函数,所以我们可以通过优化总损失函数tl来训练dcgaes生成模型。然后,经过训练的编码器可用于深度过采样过程以获得高质量的嵌入,有助于发现输入数据的最佳数据表示。smote方法在最佳数据上生成数据,最后通过训练好的解码器对生成的数据进行解码,生成高质量的少数攻击样本。
7、因此本发明提出一种结合dcgaes生成模型,dbscan聚类欠采样以及tomek links算法的平衡数据集方法,该方法能够生成高质量的少数类攻击样本,同时去除多数类中的冗余和噪声样本,最终可以得到一个相对平衡且优质的数据集。最后用投票分类器(dt+knn)在平衡后的数据集上进行训练,来实现高性能的入侵检测。
8、为达到上述目的,本发明提供如下技术方案:
9、一种基于深度生成模型和聚类欠采样的网络入侵检测方法,该方法包括以下步骤:
10、步骤1)对数据集进行预处理和确定采样阈值;
11、步骤2)采用dcgaes生成模型对少数类样本进行生成;
12、步骤3)采用dbscan聚类对多数类样本进行欠采样;
13、步骤4)采用tomek links剔除数据集中的噪声样本;
14、步骤5)使用投票分类器(dt+knn)对平衡前后的数据集进行分类实验。
15、进一步,所述步骤1)具体为包括以下步骤:
16、步骤11)数据集中,存在一些特征为字符型的数据,如“proto”属性,内容为“tcp”、“udp”、“icmp”等,采用one-hot编码对字符型数据进行预处理,将字符型特征转换为数字维度特征。采用独热编码的好处在于:可以解决分类器不好处理属性数据的问题,在一定程度上起到了扩充特征的作用。
17、步骤12)在数据集中,不同的特征具有不同的量纲。若直接将未归一化的数据送入模型学习,易导致值域范围大的数据特征具有很高的权重,使其成为主导属性,而值域范围小的数据的权重小,易使得特征丢失。为了便于算术处理和消除不同量纲,采用min-max归一化方法,在[0,1]区间内均匀且线性地映射每个特征的范围。计算公式为:
18、
19、其中,x′表示归一化之后的值,x表示初始特征值,xmin表示该属性中的最小特征值,xmax表示该属性中的最大特征值。
20、步骤13)数据集内各种类别的标签一般为字符型,需要对标签进行顺序编码转换为数字型标签。
21、步骤14)设定采样阈值区分多数类与少数类。
22、进一步,所述步骤2)具体为包括以下步骤:
23、步骤21)首先,dcgaes生成模型将入侵检测数据集中的少数类攻击样本分批输入编码器/解码器,编码器/解码器可以学习到少数类数据中固有的基本重构模式,以此重构少数类攻击样本,可以对每批样本及重构样本计算重构损失,从而在训练过程中保证生成样本分布不会偏离原始样本分布。重构损失函数可表示为:
24、
25、其中bj为原始数据样本,db为解码器解码后的样本。
26、步骤22)另一方面,dcgaes为了生成与输入样本不同的示例,需要在编码的特征空间中引入方差,以便解码生成不同于自动编码器的输入,但仍受输入数据的约束。首先从少数类攻击中随机采样与批大小重构样本相等数量的少数类样本,编码器将采样的少数类样本降为低维特征空间,通过排列编码数据的顺序,将方差引入编码/解码过程。在解码阶段,解码器改变排列好的编码数据顺序来还原样本,当解码顺序发生改变时,编码后的样本和解码后的样本必然存在一定的差异,这种差异不同于重构样本时的差异,它有助于过采样时少数类样本的生成,可以使用惩罚损失来表示。惩罚损失函数可以表示为:
27、
28、其中sb为原始数据样本,ds为编码顺序排列改变后进行解码的样本。
29、最后结合重构样本的损失函数和引入方差后的惩罚损失函数可以得到总的损失函数如下所示:
30、tl=rl+pl
31、步骤23)深度过采样过程也需要引入方差,但使用的方法与训练阶段不同。在训练阶段,编码器将输入数据减少到低维空间,并通过乱序排列编码数据来扰乱解码过程,从而在其中引入方差。然而,当涉及到深度过采样时,会使用smote过采样方法来引入方差。首先通过优化总损失函数tl训练dcgaes生成模型,然后经过训练的编码器可用于深度过采样过程以获得高质量的嵌入,有助于发现输入数据的最佳数据表示。smote方法在最佳数据上生成数据,最后通过训练好的解码器对生成的数据进行解码,生成高质量的少数类攻击样本。
32、进一步,所诉步骤3)具体包括以下步骤:
33、步骤31)dbscan的关键思想是,对于集群的每个对象,给定半径的邻域(eps)必须包含至少最小数量的对象(minpts),这意味着邻域的基数必须超过某个阈值。任意点p的ε-邻域被定义为:
34、neps=q∈d and dist(p,q)<eps
35、其中d是对象的数据库,dist(p,q)为点p,q的相互距离。如果点p的ε-邻域至少包含最小数量的点,则此点称为核心点。核心点定义为:
36、neps(p)>minpts
37、这里eps和minpts是用户指定的参数,分别表示一个核心点的ε-邻域的邻域半径和最小点数。如果不满足此条件,则认为该点为非核心点。
38、dbsacn通过检查数据集中每个对象的ε-邻域来搜索簇群。如果对象p的ε-邻域包含超过minpts,则创建一个以p为核心对象的新簇群。然后迭代地从这些核心对象中直接收集密度可达对象,这可能涉及到一个新的密度可达集群的合并。当没有新对象可以添加到任何集群时,进程终止。
39、进一步,所述步骤4)具体为包括以下步骤:
40、步骤41)去除冗余样本后,还存在类别分布重叠的情况,部分多数类样本嵌入到少数类样本密集的区域,导致边界模糊,分类困难,这种困难程度随着类别不平衡的增大而进一步加剧。tomek links表示不同类别之间距离最近的一对样本,即这两个样本互为最近邻且分属不同类别。这样如果两个样本形成一个tomek links,则要么其中一个是噪声样本,要么两个样本都在边界附近。这样通过移除tomek links就能“清洗掉”类间重叠样本,使得互为最近邻的样本皆属于同一类别,从而能更好地进行分类。
41、进一步,所述步骤5)具体为包括以下步骤:
42、步骤51)使用投票分类器(dt+knn)分别在原始训练集和平衡后训练集上进行拟合,用测试集上的分类结果检验上述平衡数据集方法的有效性。
43、有益效果:
44、1.提出的dcgaes生成模型弥补了常用过采样方法插值取样的缺点,又结合了深度生成模型拟合样本的能力,生成的样本符合原始数据集的分布,有效扩充了少数类样本数量。
45、2.对多数类样本进行dbscan聚类,聚类后的每个簇群的样本在一定程度上具有相似性,可以对簇内样本按比例进行抽样,在保留簇类样本多样性的同时达到去除冗余样本的目的。
46、3.应用tomek links方法剔除噪声样本,样本之间的分界线变得更加清晰,从而能更好地进行分类。
47、4.改善数据集的不平衡问题后,网络入侵检测模型能够有效提高对少数类攻击样本的检测率,突出了本发明的实用性。
- 还没有人留言评论。精彩留言会获得点赞!