直播处理方法、装置、电子设备及存储介质与流程
本公开涉及计算机,尤其涉及一种直播处理方法、装置、电子设备及存储介质。
背景技术:
1、随着直播行业的快速发展,出现了虚拟形象直播的直播形式。虚拟形象直播主要是通过主播自选的虚拟形象来替代主播真实形象进行直播。
2、然而,在主播的表情变化较快、表情幅度较大等情况下,基于常规的表情驱动模型,仍无法较好地通过主播的表情来驱动虚拟形象的表情变化,使得直播呈现的虚拟形象的表情与主播的表情之间存在一定的偏差,降低了表情传递的准确性。
技术实现思路
1、本公开提供一种直播处理方法、装置、电子设备及存储介质,以至少解决相关技术中至少一种技术问题。本公开的技术方案如下:
2、根据本公开实施例的第一方面,提供一种直播处理方法,应用于第一客户端,包括:
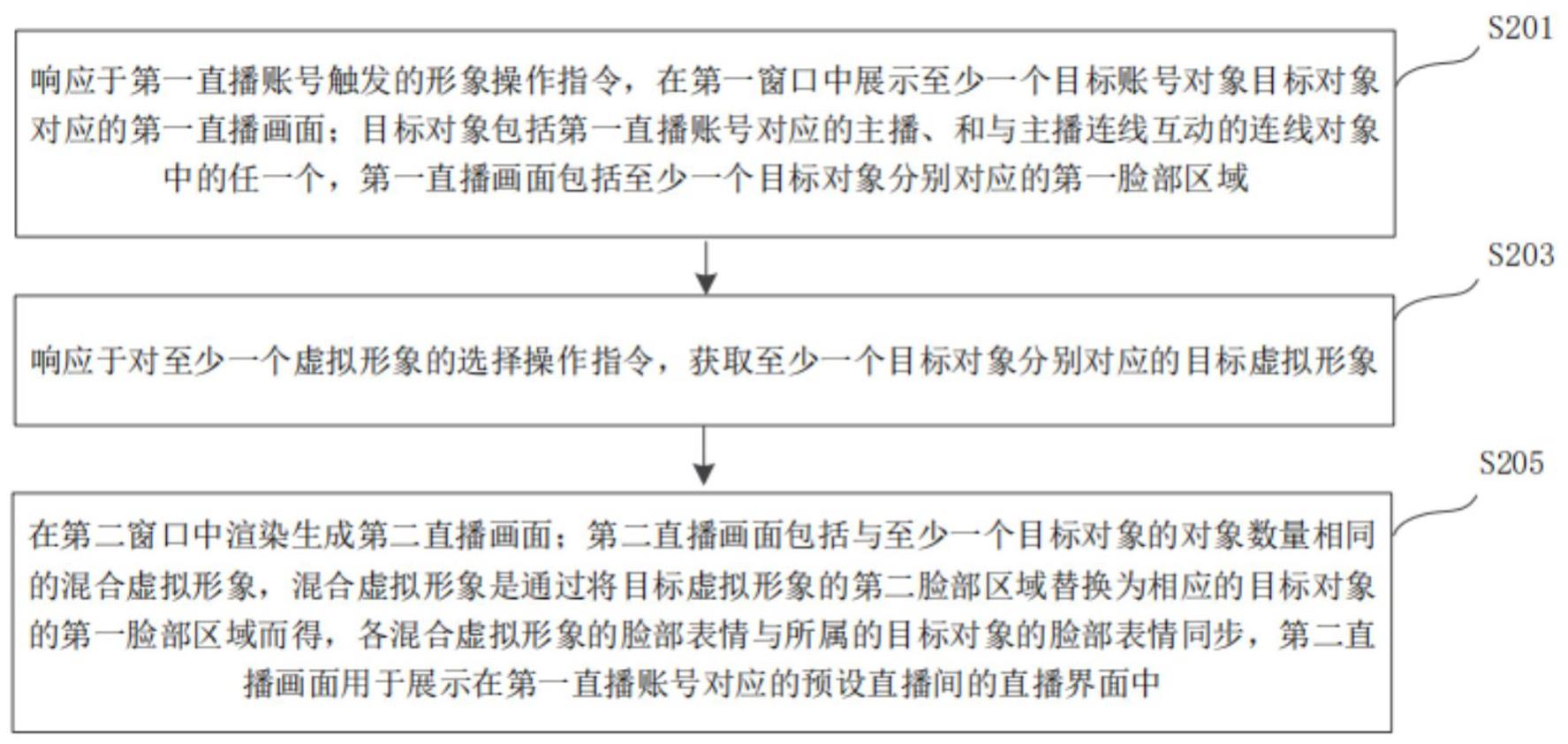
3、响应于第一直播账号触发的形象操作指令,在第一窗口中展示至少一个目标对象对应的第一直播画面;所述目标对象包括所述第一直播账号对应的主播、和与所述主播连线互动的连线对象中的任一个,所述第一直播画面包括所述至少一个目标对象分别对应的第一脸部区域;
4、响应于对至少一个虚拟形象的选择操作指令,获取所述至少一个目标对象分别对应的目标虚拟形象;
5、在第二窗口中渲染生成第二直播画面;所述第二直播画面包括与所述至少一个目标对象的对象数量相同的混合虚拟形象,所述混合虚拟形象是通过将所述目标虚拟形象的第二脸部区域替换为相应的目标对象的第一脸部区域而得,各所述混合虚拟形象的脸部表情与所属的目标对象的脸部表情同步,所述第二直播画面用于展示在所述第一直播账号对应的预设直播间的直播界面中。
6、在一可选实施方式中,所述第二直播画面中展示的各所述混合虚拟形象的目标姿态动作分别与各所述混合虚拟形象中脸部区域所属的目标对象的目标姿态动作相匹配;
7、其中,所述目标姿态动作包括头部姿态动作、肢体姿态动作中的一种或多种。
8、在一可选实施方式中,所述在第二窗口中渲染生成第二直播画面包括:
9、基于预设检测频率,对所述第一直播画面进行目标部位的关键点检测,并根据关键点检测结果,从所述第一直播画面中实时提取目标检测区域和所述目标检测区域对应的部位关键点数据,所述目标部位包括脸部、肢体部位中一种或多种,所述目标检测区域包括所述目标对象的第一脸部区域、所述目标对象的第一肢体部位区域中一种或多种;
10、基于提取的各目标检测区域,生成所述第一直播画面对应的检测图像序列帧;所述检测图像序列帧用于展示在所述第一窗口中;
11、基于所述部位关键点数据,确定所述检测图像序列帧的每一帧中所述目标对象的姿态动作数据;所述姿态动作数据用于同步调整所述目标虚拟形象的姿态动作;
12、基于所述目标检测区域、所述姿态动作数据和所述目标虚拟形象的形象模型数据,在所述第二窗口中渲染生成第二直播画面。
13、在一可选实施方式中,在所述目标检测区域包括所述目标对象的第一脸部区域,所述姿态动作数据包括头部动作数据的情况下,所述基于所述目标检测区域、所述姿态动作数据和所述目标虚拟形象的形象模型数据,在所述第二窗口中渲染生成第二直播画面包括:
14、将所述目标虚拟形象中的第二脸部区域替换为相应的目标对象的第一脸部区域,得到所述目标虚拟形象的调整后脸部区域;
15、基于所述头部动作数据,确定所述目标虚拟形象的头部姿态参数;
16、基于所述调整后脸部区域和所述目标虚拟形象的形象模型数据,得到所述混合虚拟形象,并基于所述头部姿态参数,在所述第二窗口中渲染生成包含所述混合虚拟形象的第二直播画面,所述第二直播画面的帧率与所述预设检测频率的数值相关;
17、其中,所述头部动作数据包括头部转动角度、头部横向偏移量、头部纵向偏移量中一种或多种。
18、在一可选实施方式中,所述第一直播画面的获取途径包括以下任一种:
19、通过所述目标对象对应的第三客户端调用图像采集模块获取得到、通过对所述目标对象的直播画面进行截屏得到、通过对所述目标对象的直播画面进行录屏得到、通过所述第一客户端调用图像采集模块采集得到。
20、在一可选实施方式中,所述方法还包括:
21、通过第二客户端获取所述第二窗口中展示的所述第二直播画面;所述第二客户端用于对包括所述第二直播画面的直播内容推流至第三客户端,所述第三客户端用于在所述预设直播间展示所述直播内容;或者
22、对包含所述第二直播画面的直播内容推流至第三客户端,所述第三客户端用于在所述预设直播间展示所述直播内容。
23、在一可选实施方式中,在所述预设直播间为多人直播间的情况下,所述预设直播间还展示所述第一直播画面,所述第一直播画面和所述第二直播画面分别展示在所述预设直播间的不同直播窗口中。
24、在一可选实施方式中,所述第二直播画面在所述直播界面中的展示位置包括以下任一种:
25、所述第一直播账号在所述直播界面中的直播窗口所在位置、第二直播账号在所述直播界面中的直播窗口所在位置、所述直播界面中除各直播窗口之外的位置,其中,所述第二直播账号是参与所述预设直播间的连线互动的直播账号中除所述第一直播账号之外的任一个。
26、在一可选实施方式中,所述混合虚拟形象的目标姿态动作与姿态参考对象的目标姿态动作相匹配,所述姿态参考对象包括参与所述预设直播间的连线互动、且与各所述混合虚拟形象中脸部区域所属的目标对象不同的连线对象;
27、其中,所述目标姿态动作包括头部姿态动作、肢体姿态动作中的一种或多种。
28、在一可选实施方式中,所述响应于对至少一个虚拟形象的选择操作指令,获取所述至少一个目标对象分别对应的目标虚拟形象包括:
29、响应于对至少一个虚拟形象的选择操作,获取所述至少一个目标对象分别对应的初始虚拟形象;
30、若检测到对特效元素的选择操作,获取选中的目标特效元素;
31、将所述目标特效元素添加到对应的所述初始虚拟形象中,得到所述目标虚拟形象。
32、根据本公开实施例的第二方面,提供一种直播处理装置,应用于第一客户端,包括:
33、第一展示模块,被配置为执行响应于第一直播账号触发的形象操作指令,在第一窗口中展示至少一个目标对象对应的第一直播画面;所述目标对象包括所述第一直播账号对应的主播、和与所述主播连线互动的连线对象中的任一个,所述第一直播画面包括所述至少一个目标对象分别对应的第一脸部区域;
34、第一获取模块,被配置为执行响应于对至少一个虚拟形象的选择操作指令,获取所述至少一个目标对象分别对应的目标虚拟形象;
35、渲染模块,被配置为执行在第二窗口中渲染生成第二直播画面;所述第二直播画面包括与所述至少一个目标对象的对象数量相同的混合虚拟形象,所述混合虚拟形象是通过将所述目标虚拟形象的第二脸部区域替换为相应的目标对象的第一脸部区域而得,各所述混合虚拟形象的脸部表情与所属的目标对象的脸部表情同步,所述第二直播画面用于展示在所述第一直播账号对应的预设直播间的直播界面中。
36、在一可选实施方式中,所述第二直播画面中展示的各所述混合虚拟形象的目标姿态动作分别与各所述混合虚拟形象中脸部区域所属的目标对象的目标姿态动作相匹配;
37、其中,所述目标姿态动作包括头部姿态动作、肢体姿态动作中的一种或多种。
38、在一可选实施方式中,所述渲染模块包括:
39、检测子模块,被配置为执行基于预设检测频率,对所述第一直播画面进行目标部位的关键点检测,并根据关键点检测结果,从所述第一直播画面中实时提取目标检测区域和所述目标检测区域对应的部位关键点数据,所述目标部位包括脸部、肢体部位中一种或多种,所述目标检测区域包括所述目标对象的第一脸部区域、所述目标对象的第一肢体部位区域中一种或多种;
40、序列帧生成子模块,被配置为执行基于提取的各目标检测区域,生成所述第一直播画面对应的检测图像序列帧;所述检测图像序列帧用于展示在所述第一窗口中;
41、姿态动作确定子模块,被配置为执行基于所述部位关键点数据,确定所述检测图像序列帧的每一帧中所述目标对象的姿态动作数据;所述姿态动作数据用于同步调整所述目标虚拟形象的姿态动作;
42、渲染子模块,被配置为执行基于所述目标检测区域、所述姿态动作数据和所述目标虚拟形象的形象模型数据,在所述第二窗口中渲染生成第二直播画面。
43、在一可选实施方式中,在所述目标检测区域包括所述目标对象的第一脸部区域,所述姿态动作数据包括头部动作数据的情况下,所述渲染子模块具体被配置为执行:
44、将所述目标虚拟形象中的第二脸部区域替换为相应的目标对象的第一脸部区域,得到所述目标虚拟形象的调整后脸部区域;
45、基于所述头部动作数据,确定所述目标虚拟形象的头部姿态参数;
46、基于所述调整后脸部区域和所述目标虚拟形象的形象模型数据,得到所述混合虚拟形象,并基于所述头部姿态参数,在所述第二窗口中渲染生成包含所述混合虚拟形象的第二直播画面,所述第二直播画面的帧率与所述预设检测频率的数值相关;
47、其中,所述头部动作数据包括头部转动角度、头部横向偏移量、头部纵向偏移量中一种或多种。
48、在一可选实施方式中,所述第一直播画面的获取途径包括以下任一种:
49、通过所述目标对象对应的第三客户端调用图像采集模块获取得到、通过对所述目标对象的直播画面进行截屏得到、通过对所述目标对象的直播画面进行录屏得到、通过所述第一客户端调用图像采集模块采集得到。
50、在一可选实施方式中,所述装置还包括:
51、第一处理模块,被配置为执行通过第二客户端获取所述第二窗口中展示的所述第二直播画面;所述第二客户端用于对包括所述第二直播画面的直播内容推流至第三客户端,所述第三客户端用于在所述预设直播间展示所述直播内容;或者
52、第二处理模块,被配置为执行对包含所述第二直播画面的直播内容推流至第三客户端,所述第三客户端用于在所述预设直播间展示所述直播内容。
53、在一可选实施方式中,在所述预设直播间为多人直播间的情况下,所述预设直播间还展示所述第一直播画面,所述第一直播画面和所述第二直播画面分别展示在所述预设直播间的不同直播窗口中。
54、在一可选实施方式中,所述第二直播画面在所述直播界面中的展示位置包括以下任一种:
55、所述第一直播账号在所述直播界面中的直播窗口所在位置、第二直播账号在所述直播界面中的直播窗口所在位置、所述直播界面中除各直播窗口之外的位置,其中,所述第二直播账号是参与所述预设直播间的连线互动的直播账号中除所述第一直播账号之外的任一个。
56、在一可选实施方式中,所述混合虚拟形象的目标姿态动作与姿态参考对象的目标姿态动作相匹配,所述姿态参考对象包括参与所述预设直播间的连线互动、且与各所述混合虚拟形象中脸部区域所属的目标对象不同的连线对象;
57、其中,所述目标姿态动作包括头部姿态动作、肢体姿态动作中的一种或多种。
58、在一可选实施方式中,所述第一获取模块具体被配置为执行:
59、响应于对至少一个虚拟形象的选择操作,获取所述至少一个目标对象分别对应的初始虚拟形象;
60、若检测到对特效元素的选择操作,获取选中的目标特效元素;
61、将所述目标特效元素添加到对应的所述初始虚拟形象中,得到所述目标虚拟形象。
62、根据本公开实施例的第三方面,提供一种计算机可读存储介质,当所述计算机可读存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行如上述中任一实施方式所述的直播处理方法。
63、根据本公开实施例的第四方面,提供一种电子设备,包括:
64、处理器;
65、用于存储所述处理器可执行指令的存储器;
66、其中,所述处理器被配置为执行所述指令,以实现如上述任一实施方式所述的直播处理方法。
67、根据本公开实施例的第五方面,提供一种计算机程序产品,该计算机程序产品包括计算机程序,该计算机程序被处理器执行时实现上述任一种实施方式中提供的直播处理方法。
68、本公开的实施例提供的技术方案至少带来以下有益效果:
69、本公开实施例响应于第一直播账号触发的形象操作指令,在第一窗口中展示至少一个目标对象对应的第一直播画面;目标对象包括第一直播账号对应的主播、和与主播连线互动的连线对象中的任一个,第一直播画面包括至少一个目标对象分别对应的第一脸部区域;响应于对至少一个虚拟形象的选择操作指令,获取至少一个目标对象分别对应的目标虚拟形象;在第二窗口中渲染生成第二直播画面;第二直播画面包括与至少一个目标对象的对象数量相同的混合虚拟形象,混合虚拟形象是通过将目标虚拟形象的第二脸部区域替换为相应的目标对象的第一脸部区域而得,各混合虚拟形象的脸部表情与所属的目标对象的脸部表情同步,第二直播画面用于展示在第一直播账号对应的预设直播间的直播界面中。如此,通过将目标虚拟形象的第二脸部区域替换为相应的目标对象的第一脸部区域得到混合虚拟形象,各混合虚拟形象的脸部表情与所属的目标对象的脸部表情同步,也即将真实的人脸与目标虚拟形象的身体相结合,无需通过表情驱动模型来驱动虚拟形象的表情变化,减少虚拟形象的表情与主播表情之间的偏差,提高了生成的混合虚拟形象的表情传递准确率。此外,第一直播账号具有对目标对象的形象操作的控制权,由于该目标对象可以为不同于第一直播账号的连线对象,从而能够实现对连线对象的形象控制,丰富主播之间的互动形式,改善了直播间的互动形式较单一的局限性,且提高了直播互动多样性和趣味性,利于增加经直播处理后的直播间的吸引度。
70、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!