RAW域图像去噪方法及拍摄装置与流程
本发明属于图像处理的,具体涉及一种raw域图像去噪方法及拍摄装置。
背景技术:
1、现有很多智能电子设备具有图像拍摄的功能,例如智能手机、平板电脑、行车记录仪等均设置有摄像装置,摄像装置通常设置有cmos图像传感器来获取图像。常见的图像传感器所直接采集的图像格式称为raw格式(bayer格式),需要将输出的图像经过图像信号处理器(isp)处理后,转变为色彩域图像格式(rgb或yuv格式)进行输出。图像传感器在图像采集和传输过程中易受多种因素影响从而产生噪声,使得通过图像传感器直接获取的图像通常是含有噪声的图像。由于噪声信号与图像信号混合在一起,导致存在图像特征不明显、清晰度低的问题,所以通常需要进行去噪处理以提升图像的信噪比。
2、目前传统的raw域去噪算法主要有:nlm(non-local means,非局部均值滤波)算法和bm3d(block matching 3-d filtering algorithm)等算法。这些算法存在的问题:去噪更容易牺牲原图细节,对于raw域图像不可接受;bm3d这类算法复杂度更高,硬件资源限制;随着主流图像传感器支持的增益越来越高,对于高倍增益带来的噪声,去除更困难。
3、基于学习的raw域图像去噪的模型,容易存在下面的问题:去噪的图像psnr(peaksignal to noise ratio,峰值信噪比)更高,但丢失了部分细节信息,图像不自然;为了保留更多的高频细节,出现一些伪纹理等;模型大,复杂度高,对硬件资源需求比传统去噪算法更大,对移动端部署有更大挑战。目前常见的用于raw域图像基于学习的去噪方法:存在结构臃肿,资源消耗大,容易引入伪纹理以及鲁棒性较差的缺点。
4、在实际应用中,手机相机在采集图像时会自动调整iso(增益)的值,而不同iso下所带来的噪声等级是不同的。尤其在夜景等光线不足的情况下,对应的iso会更加大,对去噪带来了更多大的挑战,尤其随着应用场景越来越广泛,一些夜景的去噪缺陷更容易放大。为消除iso变量所带来的影响,简单的思路直接收集各种iso下的数据,放入一个大的网络里进行训练,尽可能的覆盖更多的场景。存在以下问题:训练数据太杂且难收集;不同的iso带来的数据使得网络会难以学习;如果数据够多,也需要大型网络才能覆盖住,更难部署到相机应用中。
技术实现思路
1、本发明的目的在于提供一种raw域图像去噪方法及拍摄装置,针对raw域图像设计并且分通道训练做到精准去噪,模型更为轻量化,时间消耗更小,得到准确的简单的噪声图像,能适应更大的噪声强度变化。去噪后的图像更为清晰。
2、本发明提供一种raw域图像去噪方法,包括:
3、获取选定场景的原始raw域图像,包括:选取至少两个预设光照强度,在每个所述预设光照强度下分别采集至少两个预设倍数增益的噪声水平的raw数据,作为训练数据样本;
4、增强所述训练数据样本;
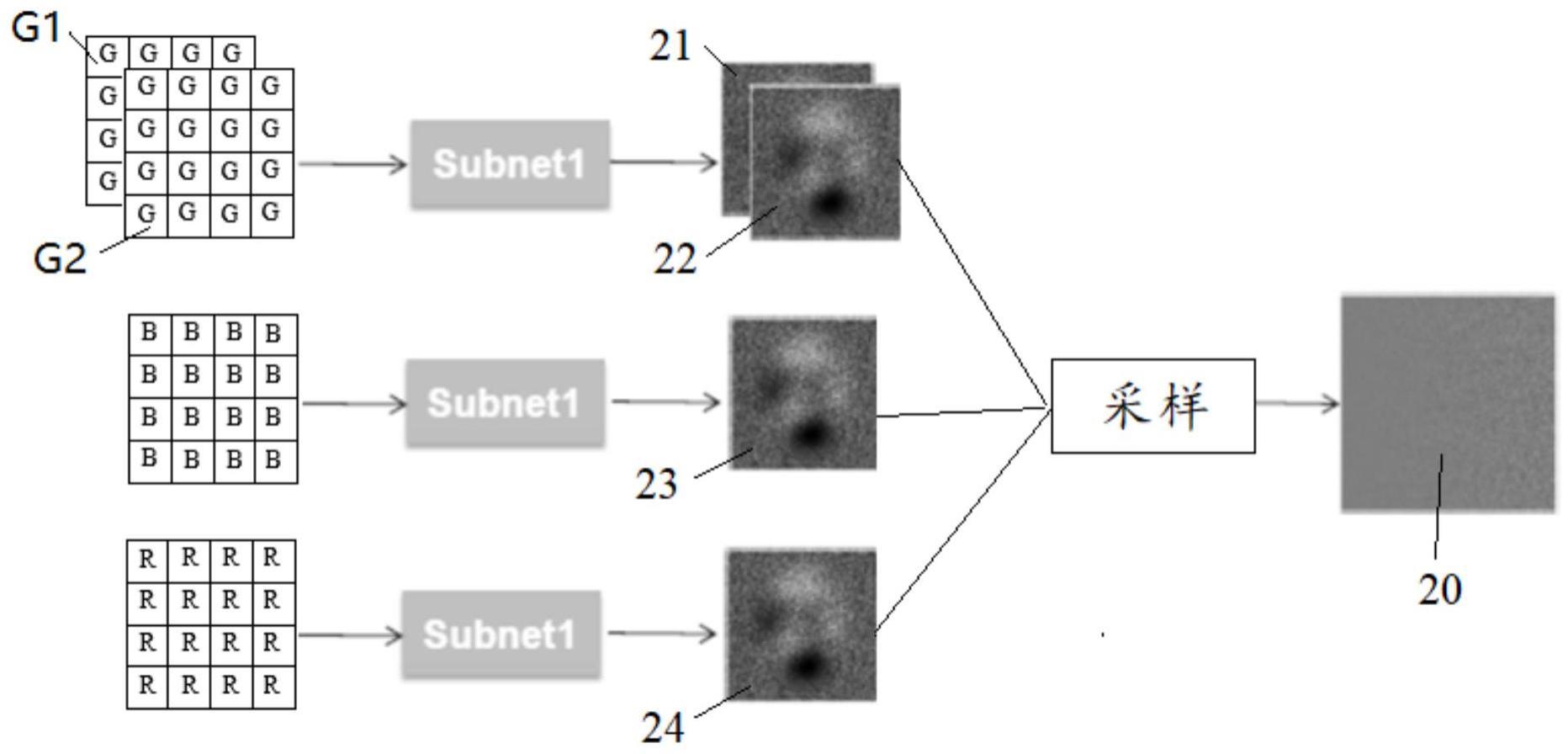
5、将增强后的训练数据样本拆分,分别训练g通道、r通道和b通道噪声估计子网络模型,得到rgb各通道噪声估计图像;
6、将所述rgb各通道的噪声估计图像进行采样并融合得到全尺寸噪声图像;
7、将所述原始raw域图像与所述全尺寸噪声图像作差,获得初始去噪图像;将所述初始去噪图像输入去噪子网络模型训练至最优,得到raw域去噪图像。
8、进一步的,所述预设光照强度包括1lux、10lux、50lux、100lux、200lux、500lux以及1000lux中的至少两个。
9、进一步的,所述预设倍数包括1倍至256倍中的至少两个整数倍数。
10、进一步的,获取所述选定场景的原始raw域图像之后,增强所述训练数据样本之前,还包括:
11、对所述原始raw域图像进行黑电平矫正处理,扣除纯黑的环境下,采集到的所述raw数据中的基底值。
12、进一步的,在每个所述预设倍数增益下均连续采集预设帧数的raw域图像,各所述预设倍数增益下的所述预设帧数的raw域图像的平均值作为各自所述预设倍数增益对应的真实标签。
13、进一步的,对于64倍增益及64倍以上增益的训练数据,将1倍增益的预设帧数的raw域图像的平均值作为64倍增益和64倍以上增益对应的真实标签,调整曝光以及通过增加一个基于整幅图像的全局补偿系数,使64倍增益和64倍以上增益中各倍数增益下的训练样本的图像灰度值均值和真实标签的图像灰度值均值一致。
14、进一步的,增强所述训练数据样本包括:
15、将每帧所述raw域图像剪裁为mxn大小的中间图像;
16、基于所述中间图像的梯度进行筛选,去除缺乏纹理的图像;
17、对筛选后的所述中间图像进行翻转、旋转以及翻转结合旋转的操作,扩充样本容量,得到所述增强后的训练数据样本。
18、进一步的,所述噪声估计子网络采用全局残差网络结构,所述去噪子网络模型采用unet网络模型。
19、进一步的,所述g通道的所述噪声估计子网络模型训练采用l1损失函数,最小化所述g通道的真实标签和噪声估计值之间差值的绝对值的和,得到所述g通道噪声估计图像。
20、进一步的,所述r通道和所述b通道的所述噪声估计子网络模型训练采用l2损失函数,最小化所述r通道的真实标签和噪声估计值之间差值的平方的和,得到所述r通道噪声估计图像;以及最小化所述b通道的真实标签和噪声估计值之间差值的平方的和,得到所述b通道噪声估计图像。
21、进一步的,采用l1损失函数联合基于边缘梯度损失函数的加权损失函数作为所述去噪子网络模型的损失函数。
22、进一步的,所述raw域图像去噪完成后,进行推理测试以验证去噪效果;所述推理测试包括:
23、重新获取与所述选定场景不同的新场景的原始raw域图像;
24、对所述新场景的原始raw域图像进行黑电平矫正处理,作为新场景的训练数据样本;
25、将所述新场景的训练数据样本拆分,将拆分得到的g通道、r通道和b通道图像数据输入训练好的所述噪声估计子网络模型,得到所述新场景的rgb各通道的噪声估计图像;将所述新场景的rgb各通道的噪声估计图像融合得到所述新场景的全尺寸噪声图像;
26、将所述新场景的原始raw域图像与所述新场景的全尺寸噪声图像作差,获得所述新场景的初始去噪图像;将所述新场景的初始去噪图像输入训练好的所述去噪子网络模型得到所述新场景的raw域去噪图像。
27、进一步的,所述新场景的原始raw域图像是训练好的所述噪声估计子网络模型和训练好的所述去噪子网络模型未识别过的图片,若所述新场景的raw域去噪图像效果优良,证明所述噪声估计子网络模型和所述去噪子网络模型训练是合格的。
28、本发明还提供一种拍摄装置,包括:
29、图像传感器,用于获取原始raw域图像;所述图像传感器在至少两个预设光照强度下分别采集至少两个预设倍数增益的噪声水平的raw数据,作为训练数据样本;
30、存储器以及处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时实现上述的raw域图像去噪方法的各个步骤。
31、与现有技术相比,本发明具有如下有益效果:
32、本发明提供一种raw域图像去噪方法及拍摄装置,去噪方法包括:
33、获取选定场景的原始raw域图像,包括:选取至少两个预设光照强度,每个所述预设光照强度下分别采集至少两个预设倍数增益的噪声水平的raw格式数据,作为训练数据样本;增强所述训练数据样本;将增强后的训练数据样本拆分,分别训练g通道、r通道和b通道噪声估计子网络模型,得到rgb各通道的噪声估计图像;将所述rgb各通道的噪声估计图像进行采样并融合得到全尺寸噪声图像;将所述原始raw域图像与所述全尺寸噪声图像作差,获得初始去噪图像;将所述初始去噪图像输入去噪子网络模型训练至最优,得到raw域去噪图像。
34、本发明raw格式输入,raw格式输出,去噪前后格式不变。本发明针对raw域图像设计,与基于转化后的rgb等格式的图像设置的算法或者模型相比,更好地利用了raw域图像的所携带的原始信息,从而有助于在去噪时保留更多的细节信息,使得去噪后的图像更为清晰。本发明能适应各种不同的增益水平并且分通道训练做到精准去噪,本发明的模型更为轻量化,时间消耗更小。本方明着手于得到准确的简单的噪声图像,基于全局的残差做最优化,能适应更大的噪声强度变化。能够达到sota的psnr(峰值信噪比)等客观指标,以及主观效果。本发明的模型更为轻量化,在窗口大小和传统图像信号处理一致的前提下,去噪效果更好。
- 还没有人留言评论。精彩留言会获得点赞!