欺诈用户识别方法、装置、设备及存储介质与流程
本发明涉及运营商大数据,尤其涉及一种欺诈用户识别方法、装置、设备及存储介质。
背景技术:
1、目前电信诈骗已成为一项重点社会治理问题,其中通过语音专线的固话类诈骗为其中重要的类别。诈骗分子通过盗取等手段获得语音专线类资源,并设计巧妙的话术引导诱骗群众以实现倾销劣质产品或非法获取群众财产的目的。为了有效抑制该种电信诈骗行为的发生,各运营商均积极响应政府的工作部署,应用业务经验或大数据技术构建自身的语音专线反欺诈模型。
2、但是由于样本及技术的限制,以及反欺诈模型的特殊性(建模正样本极其有限),当前各运营商均通过简单粗暴的“过采样”或者“欠采样”方法实现样本均衡,进而通过逻辑回归、决策树等简单的算法进行语音专线反欺诈模型的构建,存在反欺诈模型性能差、欺诈用户识别有效性低的技术问题。
3、上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现思路
1、本发明的主要目的在于提供一种欺诈用户识别方法、装置、设备及存储介质,旨在解决现有技术中反欺诈模型性能差、欺诈用户识别有效性低的技术问题。
2、为实现上述目的,本发明提供了一种欺诈用户识别方法,所述方法包括以下步骤:
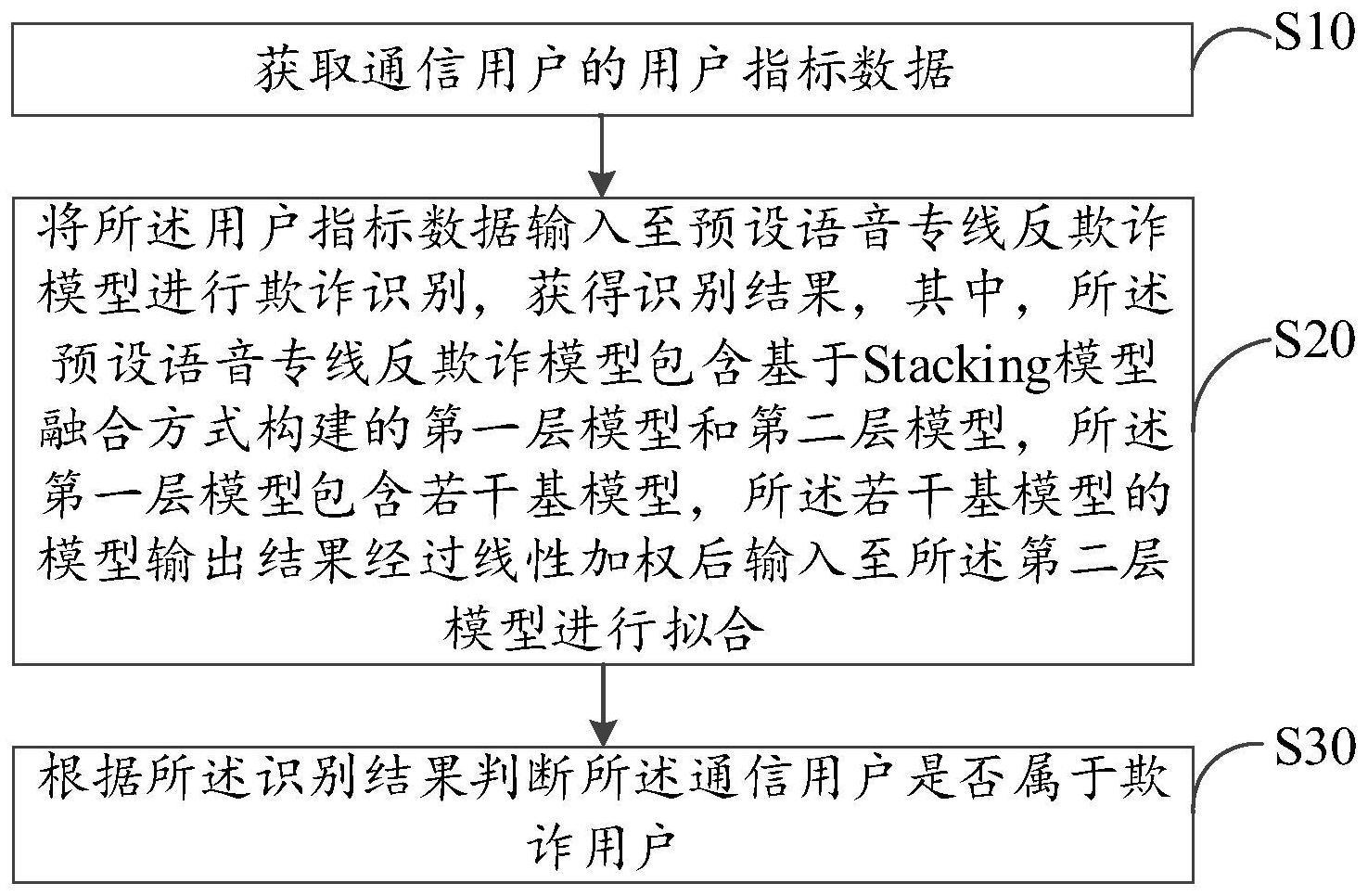
3、获取通信用户的用户指标数据;
4、将所述用户指标数据输入至预设语音专线反欺诈模型进行欺诈识别,获得识别结果,其中,所述预设语音专线反欺诈模型包含基于stacking模型融合方式构建的第一层模型和第二层模型,所述第一层模型包含若干基模型,所述若干基模型的模型输出结果经过线性加权后输入至所述第二层模型进行拟合;
5、根据所述识别结果判断所述通信用户是否属于欺诈用户。
6、可选地,采用n折交叉验证方式将均衡化建模样本集拆分成n个数据集,其中n为大于等于2的正整数;
7、对所述预设语音专线反欺诈模型的第一层模型中的每个基模型循环执行n次模型训练操作,所述模型训练操作为从所述n个数据集中任选n-1份数据集对所述基模型分别进行模型训练,并通过剩余的一份数据集对训练后的基模型进行模型推理。
8、可选地,采用分段赋值方式对所述预设语音专线反欺诈模型的第一层模型中的每个基模型进行权重赋值,所述分段赋值方式为根据各基模型输出的欺诈用户概率所处的概率区间分配不同的权重值。
9、可选地,获取建模样本数据,所述建模样本数据包括正样本数据和负样本数据,所述正样本数据为历史语音专线欺诈用户的用户指标数据,所述负样本数据为历史正常用户的用户指标数据;
10、根据所述正样本数据和所述负样本数据的数量比例确定采样倍率;
11、在所述正样本数据中任选一个正样本点,获取所述正样本点与剩余正样本点之间的欧式距离,根据所述欧式距离确定所述正样本点的预设近邻值k对应的k近邻样本;
12、根据所述采样倍率从所述k近邻样本中选出m近邻样本组合,其中,k>m;
13、根据所述m近邻样本组合和所述正样本点通过第一预设公式构建拟合样本,并且将所述拟合样本和所述建模样本数据进行合并,获得均衡化建模样本集,
14、其中,所述第一预设公式为:
15、xnew=x+rand(0,1)*(xn-x),
16、式中,xnew表示拟合样本,x表示所述正样本点,xn表示所述m近邻样本组合中的近邻组样本点的维度。
17、可选地,通过第二预设公式计算每个所述m近邻样本组合与所述正样本点之间的距离,并选择距离最小的所述m近邻样本组合作为最优近邻样本组合;
18、其中,所述第二预设公式为:
19、
20、式中,k表示样本的维度、p表示所述m近邻样本组合中的样本序号,a、m_group分别为n维空间的所述正样本点和所述m近邻样本组合的近邻组样本点,a点坐标为a(x11,x12,x13,...,x1n),近邻组样本点坐标为b(x21,x22,x23,...,x2n);
21、获取所述最优近邻样本组合中的近邻组样本点与所述正样本点之间的欧式距离,并在所述欧式距离中选择距离最小的所述近邻组样本点作为最优近邻样本;
22、根据所述最优近邻样本和所述正样本点通过第三预设公式构建拟合样本,并且将所述拟合样本和所述建模样本数据进行合并,获得均衡化建模样本集;
23、其中,所述第三预设公式为:
24、xnew=x+rand(0,1)*(xm-x),
25、式中,xnew表示拟合样本,x表示所述正样本点,xm表示所述最优近邻样本的维度。
26、可选地,根据所述最优近邻样本、所述正样本点和预设膨胀系数通过第四预设公式构建拟合样本,并且将所述拟合样本和所述建模样本数据进行合并,获得均衡化建模样本集,
27、其中,所述第四预设公式为:
28、xnew=x+rand(0,1)*λ*(xo-x),
29、式中,xnew表示拟合样本,λ表示膨胀系数,x表示所述正样本点,xo表示所述最优近邻样本的维度。
30、可选地,获取每个所述拟合样本与所述均衡化建模样本集中的其他样本的欧式距离,根据所述欧式距离确定所述拟合样本的所述预设近邻值k对应的k临近样本;
31、判断所述k临近样本中的所述正样本数据的数量是否小于(k/2)+1;
32、若是,则将所述拟合样本剔除。
33、此外,为实现上述目的,本发明还提出一种欺诈用户识别装置,所述欺诈用户识别装置包括:
34、数据获取模块,用于获取通信用户的用户指标数据;
35、欺诈识别模块,用于将所述用户指标数据输入至预设语音专线反欺诈模型进行欺诈识别,获得识别结果,其中,所述预设语音专线反欺诈模型包含基于stacking模型融合方式构建的第一层模型和第二层模型,所述第一层模型包含若干基模型,所述若干基模型的模型输出结果经过线性加权后输入至所述第二层模型进行拟合;
36、欺诈判断模块,用于根据所述识别结果判断所述通信用户是否属于欺诈用户。
37、此外,为实现上述目的,本发明还提出一种欺诈用户识别设备,所述设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的欺诈用户识别程序,所述欺诈用户识别程序配置为实现如上文所述的欺诈用户识别方法的步骤。
38、此外,为实现上述目的,本发明还提出一种存储介质,所述存储介质上存储有欺诈用户识别程序,所述欺诈用户识别程序被处理器执行时实现如上文所述的欺诈用户识别方法的步骤。
39、本发明通过获取通信用户的用户指标数据;将所述用户指标数据输入至预设语音专线反欺诈模型进行欺诈识别,获得识别结果,其中,所述预设语音专线反欺诈模型包含基于stacking模型融合方式构建的第一层模型和第二层模型,所述第一层模型包含若干基模型,所述若干基模型的模型输出结果经过线性加权后输入至所述第二层模型进行拟合;根据所述识别结果判断所述通信用户是否属于欺诈用户。由于本发明通过将通信用户的用户指标数据输入预设语音专线反欺诈模型进行欺诈识别,并根据识别结果判断所述通信用户是否属于欺诈用户,从而提高了欺诈模型的性能,更加有效的识别欺诈用户。
- 还没有人留言评论。精彩留言会获得点赞!