率失真优化量化方法、装置、电子设备及存储介质与流程
本发明涉及视频压缩,具体涉及一种率失真优化量化方法、装置、电子设备及存储介质。
背景技术:
1、相关技术中,标量量化因为死区固定,因此不能达到性能最优,率失真优化量化(rdoq)由于在量化的过程中考虑了率失真代价,所以可以最大限度优化压缩性能。rdoq技术会从多种量化方案中比较率失真代价,最后选取率失真代价最小的那个方案以达到最优性能。量化方案可以由不同的量化参数(qp)确定,也可由不同的量化偏移确定。其中,rdoq技术始于h.264/avc视频编码标准。
2、相关技术中,提出了一个早期的rdoq方法,此方法为每个编码块选取最优的qp以达到优化的目的。相关技术中,还提出一个进一步改进的方法,通过一些快速算法去掉一些不必要的候选qp从而减少遍历的数量。但是,这些方法不适用于开启码率控制的应用,因为码率控制会进一步改变每个块的qp以达到平衡码率的作用。其中,rdoq的关键是计算每个量化方案的率失真代价,率失真代价可以定义为:
3、c=d+ λ×r (1)
4、其中,c是率失真代价,d是原始信号和解码信号之间的失真,r是编码码率,λ是率失真参数。d可以通过计算原始信号和解码信号之间的差值得到。但是,因为熵编码器的顺序执行特点和上下文模型的高复杂度,准确的码率r通常比较难以获得。相关技术中提出了一种将量化系数直接输入熵编码器得到码率r的方法,但是还是需要经过熵编码器的大量运算所以并不适合低延迟的场景。
5、为了减少rdoq对熵编码器的依赖,rdoq采用了许多技术快速估计失真d和码率r。首先,跳过反变换步骤直接计算失真d。然后,通过查询经过大量训练的熵编码表估计码率r从而无需依赖熵编码器。相关技术中,提出了一种简单有效的应用于h.265/hevc中的rdoq方法。此方法试图改变非零系数的空间分布和减小非零系数的绝对值达到最小化率失真代价的目的。对量化残差系数而言,非零系数的位置和非零系数的绝对值占据了编码码率的大部分,rdoq试图对这些位置和绝对值进行微调,从而使熵编码其能够以更高的效率压缩信息。一般来说,rdoq可以减少编码码率r,但是会增加编码失真d,但是通过最小化率失真代价c达到改善最终编码质量的目的。
6、相关技术中,还进一步提出了快速算法。通过检查量化系数和qp的乘积判定是否需要rdoq。如果乘积小于某个阈值,rdoq激活。否则,rdoq关闭。
7、然而,相关技术中,rdoq方法要求量化系数以预定义的顺序到达并按顺序处理它们,这对于软件实现来说可行,但对于硬件实现来说并不是最优的。具体来说,当rdoq模块处理一个特定的量化系数时,需要完成对先前量化系数的处理。这种依赖性使得对多个量化系数的并行处理很困难,从而无法充分发挥硬件的并行能力。
技术实现思路
1、本技术的目的在于提供一种率失真优化量化方法、装置、电子设备及存储介质,可以并行处理量化系数,降低硬件的处理延迟。
2、根据本技术实施例的第一方面,提供一种率失真优化量化方法,应用于编码器,所述方法,包括:
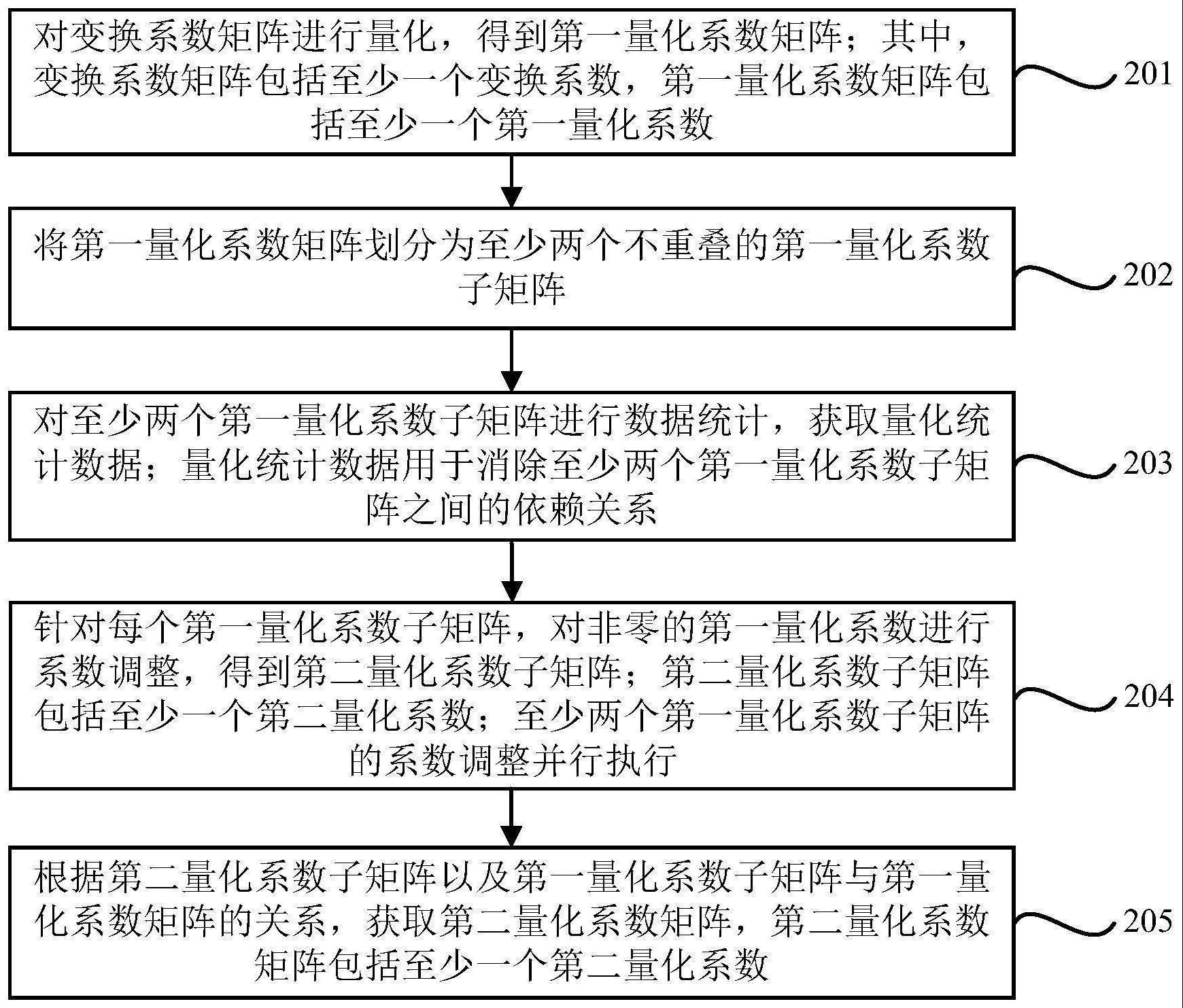
3、对变换系数矩阵进行量化,得到第一量化系数矩阵;其中,所述变换系数矩阵包括至少一个变换系数,所述第一量化系数矩阵包括至少一个第一量化系数;
4、将所述第一量化系数矩阵划分为至少两个不重叠的第一量化系数子矩阵;
5、对至少两个所述第一量化系数子矩阵进行数据统计,获取量化统计数据;所述量化统计数据用于消除至少两个所述第一量化系数子矩阵之间的依赖关系;
6、针对每个所述第一量化系数子矩阵,对非零的所述第一量化系数进行系数调整,得到第二量化系数子矩阵;所述第二量化系数子矩阵包括至少一个第二量化系数;至少两个所述第一量化系数子矩阵的系数调整并行执行;
7、根据所述第二量化系数子矩阵以及所述第一量化系数子矩阵与所述第一量化系数矩阵的关系,获取第二量化系数矩阵,所述第二量化系数矩阵包括至少一个所述第二量化系数。
8、在一种实施方式中,所述对变换系数矩阵进行量化,得到第一量化系数矩阵,包括:
9、针对所述变换系数矩阵中的每个所述变换系数,采用量化偏移参数对所述变换系数进行量化,得到所述第一量化系数。
10、在一种实施方式中,所述第一量化系数采用如下计算式计算得到:
11、qcoeff[cidx][x][y]=sign[cidx][x][y]×((|tcoeff[cidx][x][y]|×quantizationscaler[cidx][x][y]+(1<<(quantizationshift[cidx][x][y]-1)))>>quantizationshift[cidx][x][y]);
12、其中,qcoeff[cidx][x][y]为所述第一量化系数,sign[cidx][x][y]为所述变换系数的符号,tcoeff[cidx][x][y]为所述变换系数,quantizationscaler[cidx][x][y]为量化缩放参数,quantizationshift[cidx][x][y]为所述量化偏移参数,cidx为y、u、v分量索引,x、y为所述变换系数在所述变换系数矩阵中的坐标。
13、在一种实施方式中,当所述编码器适应hevc标准时,所述量化偏移参数采用如下计算式计算得到:
14、
15、其中,qp1为所述编码器适应所述hevc标准时的第一量化参数,transformshift为描述所述变换系数矩阵的内部变换移位的参数;和/或,
16、当所述编码器适应av1标准时,所述量化偏移参数采用如下计算式计算得到:
17、
18、numbitsdcqp为表示低频变换系数的量化索引dcqp所需的比特位数,tusize为所述变换系数矩阵的大小,bitdepth为视频的比特位深度,numbitsacqp为表示高频变换系数的量化索引acqp所需的比特位数。
19、在一种实施方式中,当所述编码器适应hevc标准时,所述transformshift采用如下计算式计算得到:
20、transformshift=15-bitdepth-log2(tusize);
21、其中,tusize为所述变换系数矩阵的大小,bitdepth为视频的比特位深度。
22、在一种实施方式中,当所述编码器适应av1标准时,所述dcqp采用如下计算式计算得到:
23、
24、其中,av1dcqlookup为第一表格,用于存储视频的比特位深度为8时所述第一量化参数与所述低频变换系数的量化索引的对应关系,所述av1dcqloopup10为第二表格,用于存储视频的比特位深度为10时所述第一量化参数与所述低频变换系数的量化索引的对应关系。
25、在一种实施方式中,当所述编码器适应av1标准时,所述acqp采用如下计算式计算得到:
26、
27、其中,av1acqlookup为第三表格,用于存储视频的比特位深度为8时所述第一量化参数与所述高频变换系数的量化索引的对应关系,所述av1acqloopup10为第四表格,用于存储视频的比特位深度为10时所述第一量化参数与所述高频变换系数的量化索引的对应关系。
28、在一种实施方式中,当所述编码器适应所述av1标准时,在计算所述量化偏移参数之前,包括:
29、将所述编码器适应所述av1标准时的第二量化参数转换为所述第一量化参数。
30、在一种实施方式中,所述第一量化参数采用如下计算式计算得到:
31、
32、其中,qp2为所述第二量化参数,av1tohevcqp为第五表格,用于存储视频的比特位深度为8时所述第二量化参数与所述第一量化参数的对应关系,av1tohevcqp10为第六表格,用于存储视频的比特位深度为10时所述第二量化参数与所述第一量化参数的对应关系。
33、在一种实施方式中,当所述编码器适应hevc标准时,所述quantizationscaler[cidx][x][y]采用如下计算式计算得到:
34、quantizationscaler[cidx][x][y]=hevcscalinglist[qp1%6];
35、其中,hevcscalinglist为第七表格,用于存储所述编码器适应所述hevc标准时qp1%6与所述量化缩放参数的对应关系;和/或,
36、当所述编码器适应av1标准时,所述quantizationscaler[cidx][x][y]采用如下计算式计算得到:
37、
38、numbitsdcqp为表示低频变换系数的量化索引dcqp所需的比特位数,numbitsacqp为表示高频变换系数的量化索引acqp所需的比特位数。
39、在一种实施方式中,所述对所述第一量化系数矩阵进行统计,获取量化统计数据之前,还包括:
40、为至少一个上下文模型创建对应的数组,并初始化所述上下文模型为预定义值;所述数组用于存储对应的上下文模型的状态;所述数组的每个元素为8位整数;
41、其中,所述至少一个上下文模型包括第一上下文模型、第二上下文模型、第三上下文模型与第四上下文模型;至少一个上下文模型对应的数组包括第一数组、第二数组、第三数组与第四数组;
42、所述第一数组为significantcoeffgroupctx[2],用于存储第一语法元素的条件概率状态,所述第一语法元素为significantcoeffcroup,用于指出当前的第一量化系数子矩阵是否有非零的所述第一量化系数;所述第一语法元素为所述第一上下文模型;
43、所述第二数组为sigcoeffctx[44],用于存储第二语法元素的条件概率状态,所述第二语法元素为sigcoeffflag,用于指出当前的第一量化系数是否为零;所述第二语法元素为所述第二上下文模型;
44、所述第三数组为greateronecoeffctx[24],用于存储第三语法元素的条件概率状态,所述第三语法元素为abscoeffgreaterthanoneflag,用于指出当前的第一量化系数的绝对值是否大于1;所述第三语法元素为所述第三上下文模型;
45、所述第四数组为levelabscoeffctx[6],用于存储第四语法元素的条件概率状态,所述第四语法元素为levelabscoeff,是当前的第一量化系数的绝对值;所述第四语法元素为所述第四上下文模型。
46、在一种实施方式中,对至少两个所述第一量化系数子矩阵进行数据统计,获取量化统计数据,包括:
47、对所述第一量化系数矩阵的所述第一量化系数子矩阵,按照指定的第一扫描顺序对至少两个所述第一量化系数子矩阵分别进行扫描;
48、针对每个所述第一量化系数子矩阵,按照指定的第二扫描顺序对所述第一量化系数进行扫描,获取所述量化统计数据;所述第一扫描顺序与所述第二扫描顺序相同。
49、在一种实施方式中,所述量化统计数据包括:所述第一量化系数子矩阵中绝对值为1的第一量化系数的数量、所述第一量化系数子矩阵中绝对值大于1的第一量化系数的数量、所述第一量化系数子矩阵中绝对值大于2的第一量化系数的数量、所述第一量化系数矩阵中按照所述第一扫描顺序排列的第一个非零的第一量化系数的位置、所述第一量化系数子矩阵中按照所述第二扫描顺序排列的第一个绝对值为4的第一量化系数的位置、所述第一量化系数子矩阵中按照所述第二扫描顺序排列的第一个绝对值为7的第一量化系数的位置、所述第一量化系数子矩阵中按照所述第二扫描顺序排列的第一个绝对值为13的第一量化系数的位置以及所述第一量化系数子矩阵中按照所述第二扫描顺序排列的第一个绝对值为25的第一量化系数的位置。
50、在一种实施方式中,所述第一量化系数子矩阵中绝对值为1的第一量化系数的数量存储于名为cgonecnt[64]的第五数组中,所述第五数组在数据统计前初始化为全零数组,在数据统计过程中,如果当前第一量化系数的绝对值为1,对应的所述第一量化系数子矩阵的cgonecnt自增1。
51、在一种实施方式中,所述第一量化系数子矩阵中绝对值为1的第一量化系数的数量采用如下计算式计算得到:
52、
53、其中,qcoeff[cidx][x][y]为所述第一量化系数,cidx为y、u、v分量索引,x、y为所述第一量化系数在所述第一量化系数矩阵中的坐标,tusize为所述变换系数矩阵的大小。
54、在一种实施方式中,所述第一量化系数子矩阵中绝对值大于1的第一量化系数的数量存储于名为cggreatherthanonecnt[64]的第六数组中,所述第六数组在数据统计前初始化为全零数组,在数据统计过程中,如果当前第一量化系数的绝对值大于1,对应的所述第一量化系数子矩阵的cggreaterthanonecnt自增1。
55、在一种实施方式中,所述第一量化系数子矩阵中绝对值大于1的第一量化系数的数量采用如下计算式计算得到:
56、
57、其中,qcoeff[cidx][x][y]为所述第一量化系数,cidx为y、u、v分量索引,x、y为所述第一量化系数在所述第一量化系数矩阵中的坐标,tusize为所述变换系数矩阵的大小。
58、在一种实施方式中,所述第一量化系数子矩阵中绝对值大于2的第一量化系数的数量存储于名为cggreaterthantwocnt[64]的第七数组中,所述第七数组在数据统计前初始化为全零数组,在数据统计过程中,如果当前第一量化系数的绝对值大于2,对应的所述第一量化系数子矩阵的cggreaterthantwocnt自增1。
59、在一种实施方式中,所述第一量化系数子矩阵中绝对值大于2的第一量化系数的数量采用如下计算式计算得到:
60、
61、其中,qcoeff[cidx][x][y]为所述第一量化系数,cidx为y、u、v分量索引,x、y为所述第一量化系数在所述第一量化系数矩阵中的坐标,tusize为所述变换系数矩阵的大小。
62、在一种实施方式中,所述第一个绝对值为4的第一量化系数的位置存储于名为cgfirst4loc[64][2]的第八数组中,所述第八数组在数据统计前所有元素初始化为-1,所述第一个绝对值为4的第一量化系数的位置的纵坐标存储于cgfirst4loc[64][0],横坐标存储于cgfirst4loc[64][1]。
63、在一种实施方式中,如果coeff[cidx][x][y]是所述第一量化系数子矩阵中第一个绝对值为4的系数,则cgfirst4loc更新为:
64、
65、
66、其中,cidx为y、u、v分量索引,x、y为所述第一个绝对值为4的系数在所述第一量化系数矩阵中的坐标,tusize为所述变换系数矩阵的大小,y1为所述第一个绝对值为4的第一量化系数在所述第一量化系数子矩阵中的纵坐标,x1为所述第一个绝对值为4的第一量化系数在所述第一量化系数子矩阵中的横坐标。
67、在一种实施方式中,所述第一个绝对值为7的第一量化系数的位置存储于名为cgfirst7loc[64][2]的第九数组中,所述第九数组在数据统计前所有元素初始化为-1,所述第一个绝对值为7的第一量化系数的位置的纵坐标存储于cgfirst7loc[64][0],横坐标存储于cgfirst7loc[64][1]。
68、在一种实施方式中,如果coeff[cidx][x][y]是所述第一量化系数子矩阵中第一个绝对值为7的系数,则cgfirst7loc更新为:
69、
70、
71、其中,cidx为y、u、v分量索引,x、y为所述第一个绝对值为7的系数在所述第一量化系数矩阵中的坐标,tusize为所述变换系数矩阵的大小,y2为所述第一个绝对值为7的第一量化系数在所述第一量化系数子矩阵中的纵坐标,x2为所述第一个绝对值为7的第一量化系数在所述第一量化系数子矩阵中的横坐标。
72、在一种实施方式中,所述第一个绝对值为13的第一量化系数的位置存储于名为cgfirst13loc[64][2]的第十数组中,所述第十数组在数据统计前所有元素初始化为-1,所述第一个绝对值为13的第一量化系数的位置的纵坐标存储于cgfirst13loc[64][0],横坐标存储于cgfirst13loc[64][1]。
73、在一种实施方式中,如果coeff[cidx][x][y]是所述第一量化系数子矩阵中第一个绝对值为13的系数,则cgfirst13loc更新为:
74、
75、
76、其中,cidx为y、u、v分量索引,x、y为所述第一个绝对值为13的系数在所述第一量化系数矩阵中的坐标,tusize为所述变换系数矩阵的大小,y3为所述第一个绝对值为13的第一量化系数在所述第一量化系数子矩阵中的纵坐标,x3为所述第一个绝对值为13的第一量化系数在所述第一量化系数子矩阵中的横坐标。
77、在一种实施方式中,所述第一个绝对值为25的第一量化系数的位置存储于名为cgfirst25loc[64][2]的第十一数组中,所述第十一数组在数据统计前所有元素初始化为-1,所述第一个绝对值为25的第一量化系数的位置的纵坐标存储于cgfirst25loc[64][0],横坐标存储于cgfirst25loc[64][1]。
78、在一种实施方式中,如果coeff[cidx][x][y]是所述第一量化系数子矩阵中第一个绝对值为25的系数,则cgfirst25loc更新为:
79、
80、
81、其中,cidx为y、u、v分量索引,x、y为所述第一个绝对值为25的系数在所述第一量化系数矩阵中的坐标,tusize为所述变换系数矩阵的大小,y4为所述第一个绝对值为25的第一量化系数在所述第一量化系数子矩阵中的纵坐标,x4为所述第一个绝对值为25的第一量化系数在所述第一量化系数子矩阵中的横坐标。
82、在一种实施方式中,所述针对每个所述第一量化系数子矩阵,对非零的所述第一量化系数进行系数调整,得到第二量化系数子矩阵,包括:
83、针对每个非零的所述第一量化系数,计算按照至少两个系数调整方案进行系数调整的第一编码代价;
84、针对每个系数调整方案,根据所有所述第一编码代价的和值,获得第二编码代价;所述第二编码代价为所述第一量化系数子矩阵进行系数调整的编码代价;
85、从至少两个系数调整方案中确定目标系数调整方案,其中,所述目标系数调整方案的第二编码代价为至少两个系数调整方案的第二编码代价中最小的编码代价;
86、根据目标系数调整方案对所述第一量化系数子矩阵中的非零的所述第一量化系数进行系数调整,得到所述第二量化系数子矩阵。
87、在一种实施方式中,所述第一编码代价采用如下计算式计算得到:
88、cost1[cidx][x′][y′]=distortion[cidx][x′][y′]+rate[cidx][x′][y′];
89、其中,cost1[cidx][x'][y']为所述第一编码代价,distortion[cidx][x'][y']为像素域的误差,rate[cidx][x'][y']为编码码率,cidx为y、u、v分量索引,x'、y'为所述第一量化系数在所述第一量化系数子矩阵中的坐标。
90、在一种实施方式中,所述像素域的误差采用如下计算式计算得到:
91、distortion[cidx][x′][y′]=(merr[cidx][x′][y′]>>(2×transformshift+1))×merr[cidx][x′][y′];
92、其中,merr[cidx][x'][y']为量化误差的反向还原值,transformshift为描述所述变换系数矩阵的内部变换移位的参数。
93、在一种实施方式中,当所述编码器适应hevc标准且视频的比特位深度为8时,所述量化误差的反向还原值采用如下计算式计算得到:
94、merr[cidx][x′][y′]=(err[cidx][x′][y′]>>12)×hevcscaler[qp1%6];
95、其中,err[cidx][x'][y']为量化误差,hevcscaler为第八表格,用于存储qp1%6与放大系数的对应关系,qp1为所述编码器适应所述hevc标准时的第一量化参数;和/或,
96、当所述编码器适应av1标准且视频的比特位深度为8时,所述量化误差的反向还原值采用如下计算式计算得到:
97、
98、其中,err[cidx][x'][y']为量化误差,numbitsdcqp为表示低频变换系数的量化索引dcqp所需的比特位数,numbitsacqp为表示高频变换系数的量化索引acqp所需的比特位数。
99、在一种实施方式中,视频的比特位深度为10时的量化误差的反向还原值采用如下方法得到:
100、获取视频的比特位深度为8时的量化误差的反向还原值;
101、将视频的比特位深度为8时的量化误差的反向还原值右移两位,得到视频的比特位深度为10时的量化误差的反向还原值。
102、在一种实施方式中,所述量化误差采用如下计算式计算得到:
103、err[cidx][x′][y′]=||tcoeff[cidx][x′][y′]|×quantizationscaler[cidx][x′][y′]-(|qcoeff[cidx][x′][y′]|<<quantzationshift[cidx][x′][y′])|;
104、其中,tcoeff[cidx][x'][y']为所述变换系数,quantizationscaler[cidx][x'][y']为量化缩放参数,qcoeff[cidx][x'][y']为所述第一量化系数,quantizationshift[cidx][x'][y']为量化偏移参数。
105、在一种实施方式中,所述编码码率采用如下计算式计算得到:
106、rate[cidx][x′][y′]=sigcoeffflagrate[cidx][x′][y′]+coeffabslevelrate[cidx][x′][y′];
107、其中,sigcoeffflagrate[cidx][x'][y']为第二语法元素的第一码率估计,所述第二语法元素为sigcoeffflag,用于指出当前的所述第一量化系数是否为零,coeffabslevelrate[cidx][x'][y']为对非零的第一量化系数的绝对值进行编码的语法元素的第二码率估计。
108、在一种实施方式中,当所述编码器适应hevc时,所述第一码率估计采用如下计算式计算得到:
109、
110、其中,rateesttab为第九表格,所述第九表格用于存储qp1%3、语法元素的条件概率状态与码率估计的对应关系,qp1为所述编码器适应所述hevc标准时的第一量化参数,sigcoeffflagtabidx为第二语法元素的当前条件概率状态,bitdepth为视频的比特位深度;和/或,
111、当所述编码器适应av1标准时,sigcoeffflagrate[cidx][x'][y']采用如下计算式计算得到:
112、
113、其中,rateesttab为第九表格,所述第九表格用于存储qp1%3、语法元素的条件概率状态与码率估计的对应关系,qp1为所述编码器适应所述hevc标准时的第一量化参数,由所述编码器适应所述av1标准时的第二量化参数转换得到,sigcoeffflagtabidx为第二语法元素的当前条件概率状态。
114、在一种实施方式中,sigcoeffflagtabidx采用如下计算式计算得到:
115、
116、其中,sigcoeffctx为第二上下文模型,用于存储所述第二语法元素的条件概率状态,sigcoeffctxidx由当前的所述第一量化系数子矩阵顶部的两个相邻的所述第一量化系数子矩阵和左边的两个相邻的所述第一量化系数子矩阵的第一语法元素的值综合决定。
117、在一种实施方式中,所述第二码率估计采用如下计算式计算得到:
118、coeffabslevelrate[cidx][x′][y′]=abscoeffgreaterthanoneflagrate[cidx][x′][y′]+abscoeffgreaterthantwoflagrate[cidx][x′][y′]+abscoeffminustworate[cidx][x′][y′];
119、其中,abscoeffgreaterthanoneflagrate[cidx][x'][y']为第三语法元素的第三码率估计,所述第三语法元素为abscoeffgreaterthanoneflag,用于指出当前的第一量化系数的绝对值是否大于1,abscoeffgreaterthantwoflagrate[cidx][x'][y']为第五语法元素的第四码率估计,所述第五语法元素为abscoeffgreaterthantwo,用于指出当前的第一量化系数的绝对值是否大于2,abscoeffminustworate[cidx][x'][y']为第六语法元素的第五码率估计,所述第六语法元素为absceoffminustwo,用于表示当前的第一量化系数的绝对值减2。
120、在一种实施方式中,当|qcoeff[cidx][x'][y']|<1时,所述第三码率估计等于0;qcoeff[cidx][x'][y']为所述第一量化系数;
121、当|qcoeff[cidx][x'][y']|≥1且所述编码器适应hevc标准时,所述第三码率估计采用如下计算式计算得到:
122、
123、其中,rateesttab为第九表格,所述第九表格用于存储qp1%3、语法元素的条件概率状态与码率估计的对应关系,qp1为所述编码器适应所述hevc标准时的第一量化参数,greaterthanonetabidx为所述第三语法元素的当前条件概率状态,bitdepth为视频的比特位深度;和/或,
124、当|qcoeff[cidx][x'][y']|≥1且所述编码器适应av1标准时,所述第三码率估计采用如下计算式计算得到:
125、
126、其中,rateesttab为第九表格,所述第九表格用于存储qp1%3、语法元素的条件概率状态与码率估计的对应关系,qp1为所述编码器适应所述hevc标准时的第一量化参数,由所述编码器适应所述av1标准时的第二量化参数转换得到,greaterthanonetabidx为所述第三语法元素的当前条件概率状态。
127、在一种实施方式中,当|qcoeff[cidx][x'][y']|<2时,所述第四码率估计等于0;qcoeff[cidx][x'][y']为所述第一量化系数;
128、当|qcoeff[cidx][x'][y']|≥2且所述编码器适应hevc标准时,所述第四码率估计采用如下计算式计算得到:
129、
130、其中,rateesttab为第九表格,所述第九表格用于存储qp1%3、语法元素的条件概率状态与码率估计的对应关系,qp1为所述编码器适应所述hevc标准时的第一量化参数,greaterthantwotabidx为所述第五语法元素的当前条件概率状态,bitdepth为视频的比特位深度;和/或,
131、当|qcoeff[cidx][x'][y']|≥2且所述编码器适应av1标准时,所述第四码率估计采用如下计算式计算得到:
132、
133、其中,rateesttab为第九表格,所述第九表格用于存储qp1%3、语法元素的条件概率状态与码率估计的对应关系,qp1为所述编码器适应所述hevc标准时的第一量化参数,由所述编码器适应所述av1标准时的第二量化参数转换得到,greaterthantwotabidx为所述第五语法元素的当前条件概率状态。
134、在一种实施方式中,当|qcoeff[cidx][x'][y']|<3时,所述第五码率估计等于0;qcoeff[cidx][x'][y']为所述第一量化系数;
135、当|qcoeff[cidx][x'][y']|≥3且所述编码器适应hevc标准时,所述第五码率估计采用如下计算式计算得到:
136、abscoeffminustworate[cidx][x′][y′]=(golombcodelength×eqprobrateesttab[qp1-6*(bitdepth-8)]);
137、其中,golombcodelength为采用golomb-rice码编码第六语法元素所需的码长,eqprobrateesttab为第十表格,用于存储在第六语法元素的条件概率均匀分布的情况下,索引值和码率估计的对应关系,所述索引值根据第一量化参数与比特位深度确定,所述第一量化参数为所述编码器适应所述hevc标准时的量化参数;和/或,
138、当|qcoeff[cidx][x'][y']|≥3且所述编码器适应av1标准时,所述第五码率估计采用如下计算式计算得到:
139、abscoeffminustworate[cidx][x′][y′]=golombcodelength×(eqprobrateesttab[qp1]-(eqprobrateesttab[qp1]>>2));
140、其中,golombcodelength为采用golomb-rice码编码第六语法元素所需的码长,eqprobrateesttab为第十表格,用于存储在第六语法元素的条件概率均匀分布的情况下,第一量化参数与码率估计的对应关系,所述第一量化参数由第二量化参数转换而来,所述第一量化参数为所述编码器适应所述hevc标准时的量化参数,所述第二量化参数为所述编码器适应所述av1标准时的量化参数。
141、在一种实施方式中,所述针对每个所述第一量化系数子矩阵,对非零的所述第一量化系数进行系数调整,得到第二量化系数子矩阵,包括:
142、针对每个非零的所述第一量化系数,如果所述第一量化系数在所述第一扫描顺序中位于所述第一个非零的第一量化系数之后,计算将所述第一量化系数归零的第三编码代价;
143、对所述第一量化系数进行微调,得到对应的所述第二量化系数,并计算微调所述第一量化系数的第四编码代价;
144、获取所有所述第三编码代价的和值,得到第五编码代价;所述第五编码代价为所述第一量化系数子矩阵归零的编码代价;
145、获取所有所述第四编码代价的和值,得到第六编码代价;所述第六编码代价为所述第一量化系数子矩阵进行系数微调的编码代价;
146、如果所述第五编码代价小于所述第六编码代价,将所述第一量化系数子矩阵置零,得到所述第二量化系数子矩阵;
147、如果所述第六编码代价小于所述第五编码代价,根据所述第二量化系数得到所述第二量化系数子矩阵。
148、在一种实施方式中,所述获取所有所述第三编码代价的和值,得到第五编码代价,采用如下计算式计算得到:
149、
150、其中,cgcost0为所述第五编码代价,zerooutcost[cidx][x'][y']为所述第三编码代价,cidx为y、u、v分量索引,x'、y'为所述第一量化系数在所述第一量化系数子矩阵中的坐标,cgsize为所述第一量化系数子矩阵的大小。
151、在一种实施方式中,所述第三编码代价采用如下计算式计算得到:
152、zerooutcost[cidx][x′][y′]=distortion[cidx][x′][y′];
153、其中,distortion[cidx][x'][y']为像素域的误差。
154、在一种实施方式中,所述获取所有所述第四编码代价的和值,得到第六编码代价,采用如下计算式计算得到:
155、
156、其中,cgcost1为所述第六编码代价,tweakedcoeffcost[cidx][x'][y']为所述第四编码代价,cidx为y、u、v分量索引,x'、y'为所述第一量化系数在所述第一量化系数子矩阵中的坐标,cgsize为所述第一量化系数子矩阵的大小。
157、在一种实施方式中,所述对所述第一量化系数进行微调,得到对应的所述第二量化系数,并计算微调所述第一量化系数的第四编码代价,包括:
158、将所述第一量化系数调整为第一候选量化系数,并计算调整所述第一量化系数的第一候选编码代价,其中,所述第一候选量化系数为0;
159、如果所述第一量化系数的绝对值大于1,将所述第一量化系数调整为第二候选量化系数,并计算调整所述第一量化系数的第二候选编码代价,其中,所述第二候选量化系数的符号与所述第一量化系数的符号相同,所述第二候选量化系数的绝对值等于所述第一量化系数的绝对值减去1;
160、计算所述第一量化系数的第三候选编码代价,其中,不对所述第一量化系数做任何调整;
161、选取所述第一候选编码代价、所述第二候选编码代价与所述第三候选编码代价中最小的编码代作为所述第四编码代价;
162、选取所述第一候选编码代价、所述第二候选编码代价与所述第三候选编码代价中最小的编码代价对应的量化系数作为所述第二量化系数。
163、在一种实施方式中,所述第二量化系数采用如下计算式计算得到:
164、
165、其中,newqcoeff[cidx][x'][y']为所述第二量化系数,sign[cidx][x'][y']为所述第一量化系数的符号,cost0[cidx][x'][y']为所述第一候选编码代价,cost1[cidx][x'][y']为所述第二候选编码代价,cost2[cidx][x'][y']为所述第三候选编码代价。
166、在一种实施方式中,所述第四编码代价采用如下计算式计算得到:
167、tweakedcoeffcost[cidx][x′][y′]=min(cost0[cidx][x′][y′],cost1[cidx][x′][y′],cost2[cidx][x′][y′]));
168、其中,tweakedcoeffcost[cidx][x'][y']为所述第四编码代价。
169、根据本技术实施例的第二方面,提供一种率失真优化量化装置,应用于编码器,所述装置,包括:
170、量化模块,被配置为对变换系数矩阵进行量化,得到第一量化系数矩阵;其中,所述变换系数矩阵包括至少一个变换系数,所述第一量化系数矩阵包括至少一个第一量化系数;
171、分解模块,被配置为将所述第一量化系数矩阵划分为至少两个不重叠的第一量化系数子矩阵;
172、统计模块,被配置为对至少两个所述第一量化系数子矩阵进行数据统计,获取量化统计数据;所述量化统计数据用于消除至少两个所述第一量化系数子矩阵之间的依赖关系;
173、调整模块,被配置为针对每个所述第一量化系数子矩阵,对非零的所述第一量化系数进行系数调整,得到第二量化系数子矩阵;所述第二量化系数子矩阵包括至少一个第二量化系数;至少两个所述第一量化系数子矩阵的系数调整并行执行;
174、获取模块,被配置为根据所述第二量化系数子矩阵以及所述第一量化系数子矩阵与所述第一量化系数矩阵的关系,获取第二量化系数矩阵,所述第二量化系数矩阵包括至少一个所述第二量化系数。
175、根据本技术实施例的第三方面,提供一种电子设备,包括存储器与处理器,所述存储器用于存储所述处理器可执行的计算机程序;所述处理器用于执行所述存储器中的计算机程序,以实现上述的方法。
176、根据本技术实施例的第四方面,提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,当所述存储介质中的可执行的计算机程序由处理器执行时,能够实现上述的方法。
177、与现有技术相比,本技术的有益效果在于:由于在对变换系数矩阵进行量化得到第一量化系数矩阵后,将第一量化系数矩阵划分为至少两个不重叠的第一量化系数子矩阵,并对至少两个第一量化系数子矩阵进行数据统计,获取量化统计数据,这样,利用量化统计数据可以用于消除至少两个第一量化系数子矩阵之间的依赖关系,后续可以第一量化系数子矩阵为单位并行处理量化系数。接着,针对每个第一量化系数子矩阵,对非零的第一量化系数进行系数调整,得到第二量化系数子矩阵,第二量化系数子矩阵包括至少一个第二量化系数,其中,至少两个第一量化系数子矩阵的系数调整并行执行。然后,根据第二量化系数子矩阵以及第一量化系数子矩阵与第一量化系数矩阵的关系,获取第二量化系数矩阵,第二量化系数矩阵包括至少一个第二量化系数。综上所述,本技术提供的技术方案,可以并行处理量化系数,提高硬件的处理速度,降低硬件的处理延迟。
- 还没有人留言评论。精彩留言会获得点赞!