一种基于多智能体强化学习的低轨卫星网络流路由方法
本发明属于计算机网络与通信,特别是涉及低轨卫星网络中一种基于多智能体(multi-agent)强化学习(deep reinforcement learning,drl)的流路由(flow-based routing)方法。
背景技术:
1、近年来,随着人类对泛在通信需求的快速增加、各类创新应用不断涌现,大规模低地球轨道(low earth orbit,leo)卫星网络,如spacex提出的starlink星座,已成为工业界和学术界的研究热点。低轨卫星宽带网络(leo satellite broadband network,lsbn)被广泛地视为未来地面网络的一种重要补充,并将在即将到来的第六代(6g)移动通信网络系统中发挥关键作用。相比传统高轨道卫星网络,低轨卫星宽带网络具在地球表面上无缝覆盖、点到点通信延迟小和通信传输功耗低的优势。然而,低轨卫星的高动态性和高移动性,导致间歇性的链路连接和动态的网络拓扑,这使得为地面网络设计的传统路由算法无法直接适用于大规模低轨卫星宽带网络。
2、另一方面,基于深度强化学习(drl)的人工智能技术在许多科研领域中得到了越来越多的应用。研究人员已经利用深度强化学习方法来实现对传统地面网络中的数据包进行路由和交换转发。学术界近期已经开始研究基于深度强化学习的低轨卫星宽带网络路由方法。初步的实验评估结果显示,基于深度强化学习的路由方法在低轨卫星宽带网络中可以胜过传统路由算法的性能。然而,大多数现有研究,仅仅假设数据包的路由决策过程可以在路由器接收到一个数据包后立即进行并完成,上述对决策过程的假定过于理想化,忽略了在实际网络环境中进行数据包路由决策时深度神经网络(dnn)模型推理所需的时间。考虑到低轨卫星上的有限计算资源,不能忽视深度神经网络模型推理所需时间。这将增加网络中数据包的传输延迟、增大数据包丢失率,最终限制低轨卫星宽带网络中的网络流量的吞吐量。因此,忽略深度神经网络模型推理时间将会威胁到这些已有研究工作所得出结论的正确性。
技术实现思路
1、为了消除深度神经网络模型推理时间对路由性能所带来的负面影响,本发明提出一种基于多智能体强化学习(multi-agent deep reinforcement learning,madrl)的流路由(flow-based routing)方法,该方法为网络数据流而不是每个单独的数据包做出路由决策。流路由被形式化为基于部分可观察马尔可夫决策过程(pomdp)的多智能体决策问题。每个低轨卫星作为一个智能体(agent)可以根据自己的策略(policy)将一个网络数据流转发给其邻近的卫星之一。需要强调的是,智能体上的深度神经网络模型仅在其路由特定数据流中的第一个数据包时进行推理,该数据流中的后续数据包按照与第一个数据包相同的路由决策进行转发。由于低轨卫星宽带网络的拓扑动态性会导致路由失效,从而影响流路由性能,本发明进一步提出一种自适应数据流路由更新方法,自动对路由决策进行更新、适应动态变化的网络拓扑,以增强所提出的流路由方法的性能。
2、本发明所采用的技术方案如下:一种基于多智能体强化学习的低轨卫星网络流路由方法,该方法包括:
3、a1:构建低轨星座宽带网络分布式星间路由模型;
4、本发明首先进行低轨星座网络路由模型构建;该模型包括星间通信链路、卫星运动轨迹、星座网络拓扑结构、用户分布等关键要素的建模;通过对目标系统架构和特性的深入分析,构建准确的低轨星座网络路由模型;
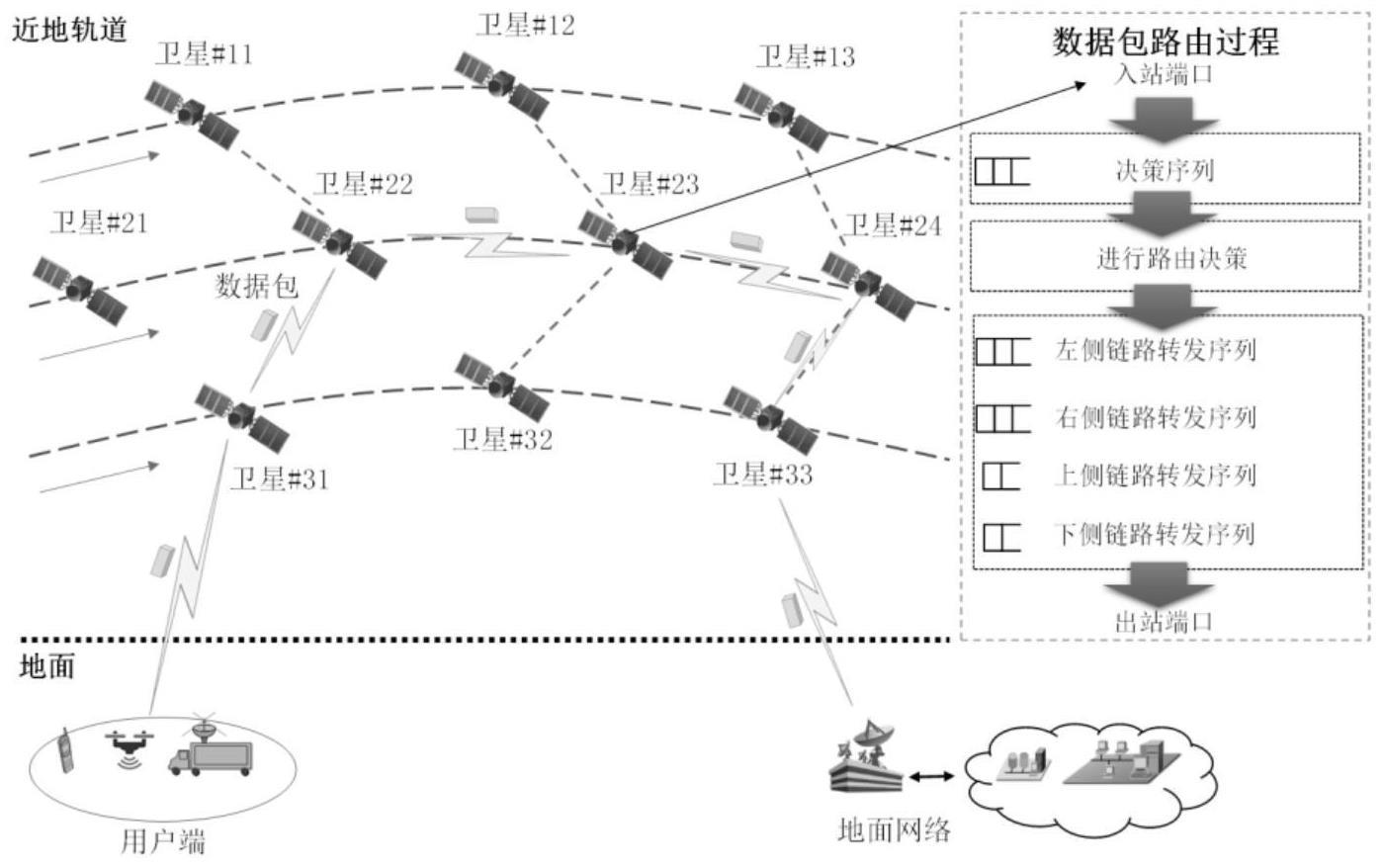
5、低轨卫星表示为sati,i∈{1,2,…,total},total表示低轨卫星总数;假设每颗卫星都建立n条星间链路,与其相邻卫星进行通信;上述链路分别与同一轨道上的前后两颗卫星相连,以及与相邻轨道上的左右两侧卫星相连;linki,j表示sati到satj的星间链路,其中i表示发送端卫星的编号,j表示接收端卫星的编号;
6、当低轨卫星接收到一个数据包时,将根据其上路由算法选择下一跳卫星,并通过星间链路将数据包转发到下一跳卫星;这个过程将会引入时间延迟,包括决策延迟和转发延迟:决策延迟指从接收数据包到做出路由决策的时间延迟;转发延迟指从做出路由决策到下一跳卫星接收到数据包的时间延迟;具体地,对于数据包k,决策延迟包括两个部分:决策排队延迟和决策制定延迟决策排队延迟是指在某低轨卫星上排队等待进行路由决策所需要的排队等候时间,而决策制定延迟是指卫星做出路由决策所需时间;在数据包转发过程中,转发延迟包括多个部分:转发排队延迟传输延迟和传播延迟转发排队延迟指数据包在某低轨卫星中排队等待转发所需时间,传输延迟指数据包通过星间链路传输所需时间,传播延迟则是指信号沿星间链路从一个卫星到另一个卫星所需时间;
7、设在上分配带宽用于传输数据包k,则该链路上传输延迟通过如下公式计算:
8、
9、其中,sk是数据包k的大小;如果linki,j上暂时没有空闲带宽,数据包k将被暂存到linki,j的转发队列缓存中,将引入转发排队延迟当缓存达到最大容量时,后续到来的数据包将被丢弃;另一方面,假设时间t时刻sati和satj的空间坐标分别为(xi,t,yi,t,zi,t)和(xj,t,yj,t,zj,t);这两个卫星之间的空间距离通过如下公式计算:
10、
11、若假设linki,j的传播距离为则可用公式:
12、
13、来计算信号传播延迟其中c为真空中光速;
14、计算低轨卫星sati上路由数据包k的总延迟di,k:
15、
16、如果下一跳的低轨卫星不是目标节点,则上述过程将在下一跳低轨卫星上再一次被执行;
17、a2:将路由问题建模为局部可观测马尔可夫决策过程;
18、将低轨星座宽带网络的路由性能优化问题转化为局部可观测马尔可夫决策过程,以更好地描述系统不确定性和随机性,有效处理复杂决策问题;该过程p由以下具有6元组描述:
19、p=(s,a,t,r,o,γ)
20、其中,s是环境的全局状态空间,a是智能体共享的动作集合,t是环境的状态转移函数,r=s×a是智能体共享的全局奖励函数,o表示智能体的局部观测状态空间,γ∈[0,1]是用来平衡长短期奖励的折扣因子;局部观测状态,动作和奖励函数更具体的定义为:
21、动作:每个智能体在接收到数据包后,需要对数据包进行路由决策;智能体从动作空间中选一个动作进行数据包路由;其中,和分别表示将数据包传递至其四个相邻卫星中的一个;
22、奖励函数:每个智能体的目标是学习最优路由策略以提升其路由性能,为确保每个智能体学习到最优路由决策,sati在时间t对数据包k进行路由的奖励函数ri(t)为:
23、
24、其中,ψ为数据包丢失时给智能体的惩罚值,disj,k表示下一跳卫星satj和目标卫星之间的归一化空间距离,是数据包k的归一化转发延迟,是路由数据包k在satj上的归一化决策延迟;κ1,κ2和κ3是用于平衡上述因素的权重,累积折扣奖励由计算,其中γ∈[0,1]表示折扣因子;
25、局部观测状态:在低轨卫星宽带网络中,每颗低轨卫星作为一个智能体,其局部观测状态空间定义为设每个卫星能够与其周边上、下、左、右四颗相邻卫星通信;其中是卫星sati的四个相邻卫星到当前数据包k的目标卫星的空间距离;本发明使用simplified general perturbations 4(sgp4)模型估计相邻卫星和目的卫星的空间位置;表示四个连接卫星sati的星间链路的网络可用带宽;为卫星sati上四个转发队列的当前流量负荷,为卫星sati的四个相邻卫星上的决策队列的负载;由于上述要素取值范围不同,使用前需对其进行归一化;
26、a3:设计基于多智能体深度强化学习的路由方法;
27、利用深度强化学习技术,通过智能体之间的协作和学习,从低轨星座网络环境中不断获得反馈和奖励,优化星间路由策略,以提高整个网络的路由性能和吞吐量;每个卫星都包含两个深度神经网络:估计q网络qi(oi,ai;μi)和目标q网络qi′(oi,ai;μi′),分别由μi和μi′对应网络的参数化;在每个决策时间t,卫星sati考虑其本地观测oi(t),并基于ε-greedy策略从动作空间ai中选择动作ai(t):
28、
29、si(t)表示全局状态,ai(t)表示动作,当智能体根据当前观测选择动作后,智能体与环境交互,当前状态将被改变为下一个状态oi(t+1),同时sati将获得奖励ri(t),设定经验元组{oi(t),oi(t+1),ai(t),ri(t)},该经验元组将被记录到经验回放池rb中,该经验回放池是用于打破训练数据的相关性的一种设定,从而优化强化学习训练过程,智能体从经验回放池rb中随机抽取一批经验元组并利用其更新估计q网络的参数值进行训练,在每次的迭代中,目标q网络被用于计算每个状态-动作对(oi(t),ai(t))的固定目标q值yi(t),其中使用估计q网络获得下一个状态oi(t+1)上所有动作的最大q值,并使用目标网络参数μi′,其中yi(t)计算方法为:
30、
31、其中,γ是折扣因子,用于确定未来奖励的重要性;ri(t)是对于状态-动作对(oi(t),ai(t))的即时奖励;损失函数为:
32、lossi(t)=(yi(t)-qi(oi(t),ai(t);μi))2
33、估计q网络的参数值通过使用随机梯度下降来最小化估计q值和目标q值之间的均方误差进行更新,估计q网络的参数μi在每个训练迭代结束时通过复制目标q网络的参数μi′进行更新:
34、
35、其中α是学习率,在每次迭代后,目标q网络的参数根据估计q网络进行软更新,逐渐地,估计q网络可以更准确地估计代理的数据包路由决策;
36、a4:定义低轨卫星星座网络分布式路由场景中的数据流;
37、随着新一代低轨卫星宽带网络建设进程的加速和用户数量的急剧增加,卫星网络通信频率进一步提高,向着高通量和宽带网络的方向持续发展;单颗卫星的吞吐量需求超过数百gbps,将上述madrl算法部署到低轨卫星上,用于分布式路由转发,神经网络模型固有的推理时延,将导致单星吞吐量严重受限、丢包率大幅提升,无法满足新一代低轨星座宽带网络的高带宽、低时延传输需求;为全面优化上文所提基于madrl的分布式路由方案,本发明提出了一种基于数据流(flow-based)的路由方案;
38、数据流(flow)是指一组有序的,源头节点和目地节点相同的数据包序列;在低轨卫星宽带网络场景中,本发明关注数据包的星间路由。因此,将低轨卫星节点作为数据流的起点和终点,而不关心序列中的数据包具体是由哪些地面用户节点发送与接收。本发明所提madrl是分布式算法,因此,每个低轨卫星节点是独立的智能体,卫星节点在接收到数据包后,需要根据接收该数据包的网口信息,以及该数据包发往的目的地址信息,确定该数据包所属的数据流。由此,低轨卫星网络场景中数据流的定义为:从某低轨卫星上同一个网口接收到的、目的地址节点为相同卫星的数据包的有序集合,定义为同一条数据流。
39、a5:提出基于数据流的路由策略共享机制
40、为有效减轻深度神经网络推理时间对低轨卫星网络路由性能所带来的负面影响,本发明提出了一种流路由方法。该方法将数据包组织为流,并考虑数据流的特性、时延要求、带宽需求等因素,通过智能体上的学习和决策,选择低轨卫星间最佳路由路径和资源分配策略,以最大程度优化网络路由性能。
41、考虑到同一数据流中所有数据包具有相同的目的地址,每颗低轨卫星独立维护通过其的所有数据流的“流路由表”,与传统的madrl包路由方法类似,基于madrl的数据流路由方法要求低轨卫星使用深度神经模型为该数据流中的第1个数据包进行路由决策。所得路由信息作为“流路由表”中相应条目存储,并为同一数据流中的后续数据包使用,消除该数据流中后续数据包进行深度神经网络模型推理需求,显著减少低轨卫星宽带网络中进行深度神经网络模型推断所花费的累积时间。因此,路由性能(包括:端到端传输延迟、数据包丢失以及网络吞吐量)将得到显著优化,从而满足大规模低轨卫星宽带网络性能需求。
42、a6:设计基于时延抖动的自适应流路由更新方法
43、本发明引入一种自适应数据流路由更新方法,通过实时监测星间数据包传输延迟变化,自动更新数据流路由决策。具体地,基于计算前后两次成功传输数据包之间的延迟差异,并将其与预设的阈值进行比较。如延迟差异(时延抖动)超出阈值,将触发多智能体强化学习算法来重新为该流进行路由选择,更新路由决策。该机制的实施完全独立于复杂的网络模型(model-fee)。当卫星对数据包完成转发后,会感知并记录该数据包在这一跳传输的时延,并将属于同一条数据流的连续两个数据包的时延delayi+1和delayi做差,计算时延抖动δdelayi+1:
44、δdelayi+1=|delayi+1-delayi|
45、然后基于时延抖动δdelayi+1判断在当前网络状态下,路由表中针对该数据流的路由策略的适用性。若时延抖动δdelayi+1高于设定的一个阈值θthr,说明当前的路由路径可能存在性能问题或异常情况,则对该数据流的下一个数据包进行转发时,再次调用深度神经网络模型,执行推理所输出的路由策略来转发该数据包,并替换路由表中的旧策略,由此完成对数据包的转发和对数据流的路由策略更新。
46、相比现有网络路由技术,本发明综合利用了“强化学习”和“基于数据流的路由”技术。能够有效减少针对低轨卫星宽带网络数据包进行深度神经网络模型推理的次数,显著减少深度神经网络模型推断所花费的累积时间。并能够有效改善和提升大规模低轨卫星宽带网络的路由性能,从而更好地满足其网络性能需求。
- 还没有人留言评论。精彩留言会获得点赞!