一种基于前置采样的网络流基数估计方法及系统
本技术涉及网络测量,尤其涉及一种基于前置采样的网络流基数估计方法及系统。
背景技术:
1、随着数字化和智能化时代的来临,各种新型网络应用也不断涌现,联网设备数量和网络流量规模呈现爆炸式增长。为应对急剧增长的数据通信需求带来的机遇与挑战,网络服务运营商和云服务公司近年来全力推进网络基础设施的虚拟化与细粒度管理,其中网络流量测量就是获取网络性能和支撑网络管理的重要基础功能。高速网络流量测量中的网络流基数测量在目前网络管理中起着十分重要的作用,可以为扫描攻击检测、性能诊断和异常检测等重要网络功能提供分析依据。因此,有必要在当前网络设备数量和链路速率的急剧增长的环境下,实现对数百万甚至更多的流量进行精准高速的基数测量。
2、当前业界的主流做法分为基于sketch和基于采样技术两种方案。
3、基于sketch的方案是通过利用数据压缩的技术,以远小于原始流量数据的空间尽可能多地存储数据信息,以便适应片上有限的存储空间,同时能够提供较好的精度保证。基于sketch的方法对于每个数据包的查询和更新操作仅会产生常数级的时间开销,同时具有概率保证的测量精度。然而这只能解决基数测量过程中紧缺的存储资源问题,在提高吞吐量方面并没有显著的效果,典型的例子有li等人提出的virtual bitmap算法,xiao等人提出的virtual hyperloglog算法等。
4、基于采样技术的方案仅选择部分有代表性的网络流量数据子集进行采集处理,利用片上的采样模块将被采样的流信息发往片下进行记录。可以凭借利用较低的采样概率来提高吞吐量,然而难以权衡其采样概率和估计精度是它的一个严重问题:采样概率较小会严重降低最后的测量精度,而采样概率偏大会消耗大量存储和通信资源。
5、现有技术也有将sketch技术与元素级别采样相结合的方式,但这会带来新的问题:一方面,尽管元素级别采样技术可以利用较低采样率来提高数据吞吐量,但这会带来精度损失,直接通过已有的sketch技术难以得到期望的估计结果;另一方面,现有元素级别采样方法大都需要实时生成随机数,或是对元素进行哈希。而这些采样处理操作都需要进行复杂的计算,在硬件计算速度难以提高的情况下,会额外消耗大量的时间,大大降低了算法的处理速度。
6、基于现有技术中高速网络环境下基数测量的问题,尚未提出有效的解决方案。
7、需要说明的是,在上述背景技术部分公开的信息仅用于加强对本公开的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、鉴于现有技术的上述缺点、不足,本技术提供一种基于前置采样的网络流基数估计方法及系统,在保证一定准确性的前提下降低检测系统所需要的计算和存储开销,同时最大程度的减少该系统对网络的影响。保证采样流量的实时性,有效性;提高算法的准确性,保证基数估计的精度;提高系统的速度,降低存储开销;提高流量测量的吞吐量。同时,本技术也需要保证系统的可扩展性,兼容性和易用性。
2、本技术主要包括以下几个方面:
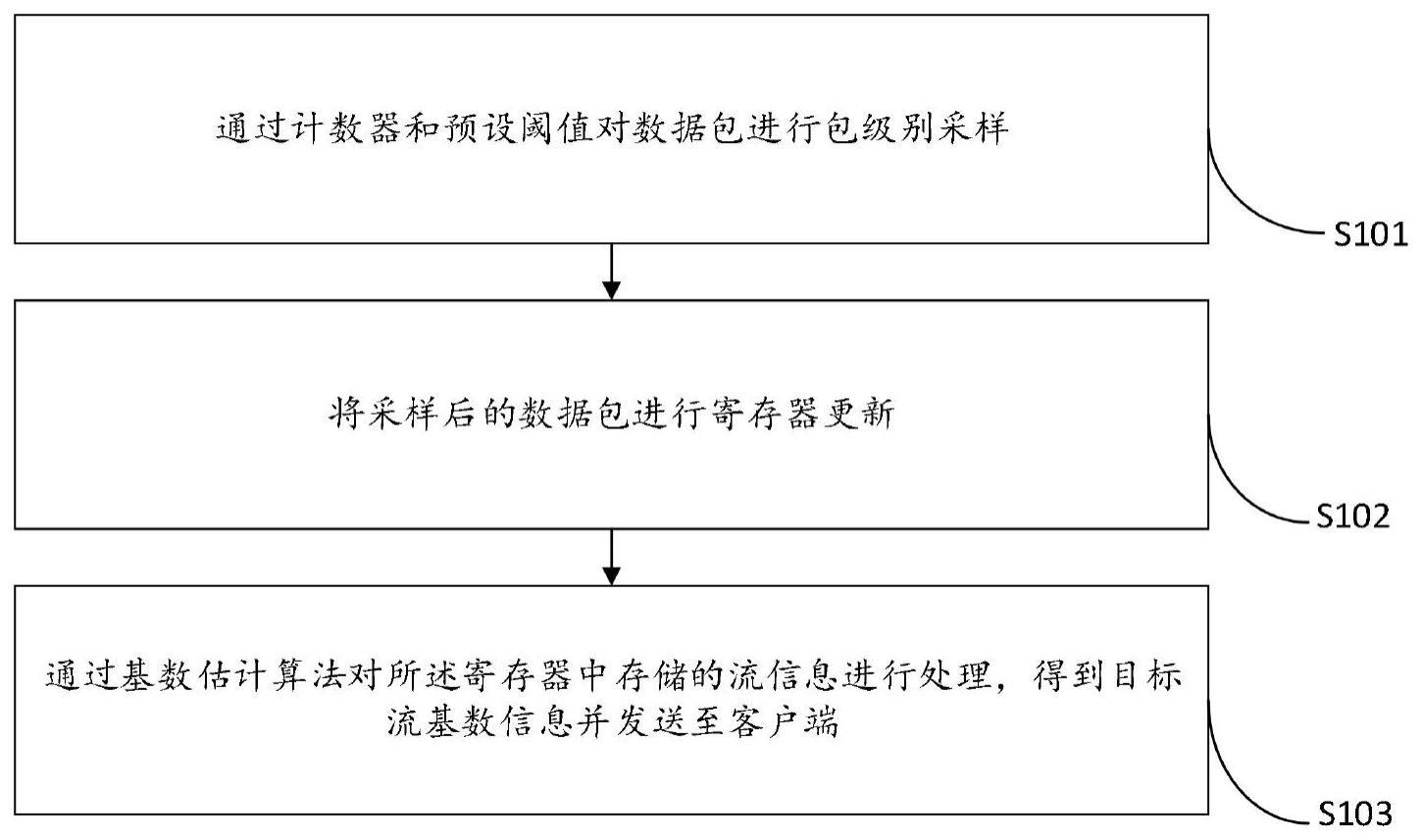
3、第一方面,本发明提供了一种基于前置采样的网络流基数估计方法,包括:
4、通过计数器和预设阈值对数据包进行包级别采样;
5、将采样后的数据包进行寄存器更新;
6、通过基数估计算法对所述寄存器中存储的流信息进行处理,得到目标流基数信息并发送至客户端。
7、在本发明的一个实施例中,通过计数器和预设阈值对初始数据包进行包级别采样,包括:
8、通过计数器和预设阈值进行包级别采样判断;
9、若所述计数器的值小于所述预设阈值,则采样;
10、若所述计数器的值大于或等于所述预设阈值,则不采样。
11、在本发明的一个实施例中,将采样后的数据包进行寄存器更新,包括:
12、对采样后的数据包进行解析,提取所述数据包的流标签和元素标签;
13、并利用哈希函数重新计算所述流标签和所述元素标签;
14、根据所述元素标签中的第一目标数值得到寄存器;
15、根据所述元素标签中的第二目标数值对所述寄存器进行更新。
16、在本发明的一个实施例中,所述基数估计算法包括原始流基数计算和修正系数计算。
17、在本发明的一个实施例中,所述原始流基数计算中原始流基数的计算公式为:
18、
19、其中,为原始流基数估计数值,m为每条流使用的虚拟寄存器个数,j为虚拟寄存器组中的每个虚拟寄存器的索引,αm为每条流使用m个虚拟寄存器个数时的估计偏置系数,rf为流f的虚拟寄存器组。
20、在本发明的一个实施例中,所述原始流基数计算中,当识别到小流部分时,需要对所述小流部分进行修正,具体计算公式为:
21、
22、其中,为小流估计基数值,z为寄存器中数值为0的个数。
23、在本发明的一个实施例中,所述原始流基数计算中基于基数估计结果进行去噪,具体公式为:
24、
25、其中,为所有的估计基数总和,n为测量过程中物理寄存器的个数。
26、在本发明的一个实施例中,所述修正系数计算包括:包级别采样大流修正和包级别采样小流修正。
27、第二方面,本技术实施例还提供了一种基于前置采样的网络流基数估计系统,包括:
28、采样模块,用于通过计数器和预设阈值对数据包进行包级别采样;
29、更新模块,用于将采样后的数据包进行寄存器更新;
30、结果处理模块,用于通过基数估计算法对所述寄存器中存储的流信息进行处理,得到目标流基数信息并发送至客户端。
31、在本发明的一个实施例中,所述采样模块,还用于:
32、通过计数器和预设阈值进行包级别采样判断;
33、若所述计数器的值小于所述预设阈值,则采样;
34、若所述计数器的值大于或等于所述预设阈值,则不采样。
35、本发明的上述技术方案相比现有技术具有以下优点:
36、本发明所述的一种基于前置采样的网络流基数估计方法及系统,引入前置包级别采样技术pps(preposition packet-level sampling)。首先改进已有的元素级别采样技术,仅利用一个计数器和一个预先设定好的阈值来完成是否采样的判断。与常见的元素哈希采样方式相比,极大减少了计算的复杂度,有效提高了吞吐量。并且进行前置包级别采样时无需使用数据包的信息,省去了提取元素标签或流标签的时间。此外,本技术利用概率分析的方式对原有的基数估计结果进行修正。基于真实世界数据集的实验结果表明,本技术提出的pps算法可以在保证基数估计精度的基础上,实现大幅度提高流量测量的吞吐量。
37、本技术针对数据包处理速度与高速网络流量不匹配的问题,改进了现有的元素级别采样技术,减少了采样处理的平均操作时间,提高了算法的吞吐量。
38、本技术针对采样技术带来的数据特征损失,在已有寄存器更新算法上,分析其中数值频率分布情况,提出一个修正系数用于修正最后基数估计结果,有效地保证了基数估计的精度。
39、本技术针对算法验证方法的选择上,使用真实网络流量数据集,在不同采样概率下模拟真实网络环境对算法进行实验。实验结果显示,相较于元素级别采样算法,本技术提出的算法具有更高的吞吐量和更小的估计误差。
- 还没有人留言评论。精彩留言会获得点赞!