基于目标检测的实时双光谱融合视频流显示方法及系统与流程
本发明涉及目标检测,具体涉及基于目标检测的实时双光谱融合视频流显示方法及系统。
背景技术:
1、目标检测是计算机视觉中最重要的任务之一,主要目标是在真实场景或输入图像中检测出特定目标以及目标的具体位置,并为每个检测到的对象分配预先标注的类别标签。当前大部分目标识别的展示大多基于单光谱的视频流,即仅展示可见光或红外光谱视频流,而忽略了另外一路视频流中拍摄到的对应检测目标。这种展示方式虽然能够满足一定的需求,但无法给用户提供更加全面、精准的目标识别体验。
2、在当下工业巡检机器人中,越来越多地采用了计算机视觉技术,特别是目标检测技术,以达到在机器人巡检时,实时检测人员情况、开关表计、烟火毒气等目标,辅助相关工作人员对工业生产的规划和维护。然而,现有的目标检测技术多数只基于单光谱的视频流进行检测和展示,无法展示同一目标在另一路光谱视频中的对应位置信息。例如,针对可见光视频流进行人员头部检测,而忽略了红外光谱视频中人员对应的信息。这种情况下,用户需要同时观看两路光谱的视频流,并自行判断两路视频中的目标是否对应。这样的方式明显增加了用户的认知负担,而且无法保证检测的准确性和实时性。
技术实现思路
1、发明目的:本发明目的在于针对现有技术的不足,提供基于目标检测的实时双光谱融合视频流显示方法及系统,能够在单光谱视频的基础上,实时追踪并在对应位置上显示另一路光谱视频中的目标信息,提高了目标识别的准确性和用户体验。
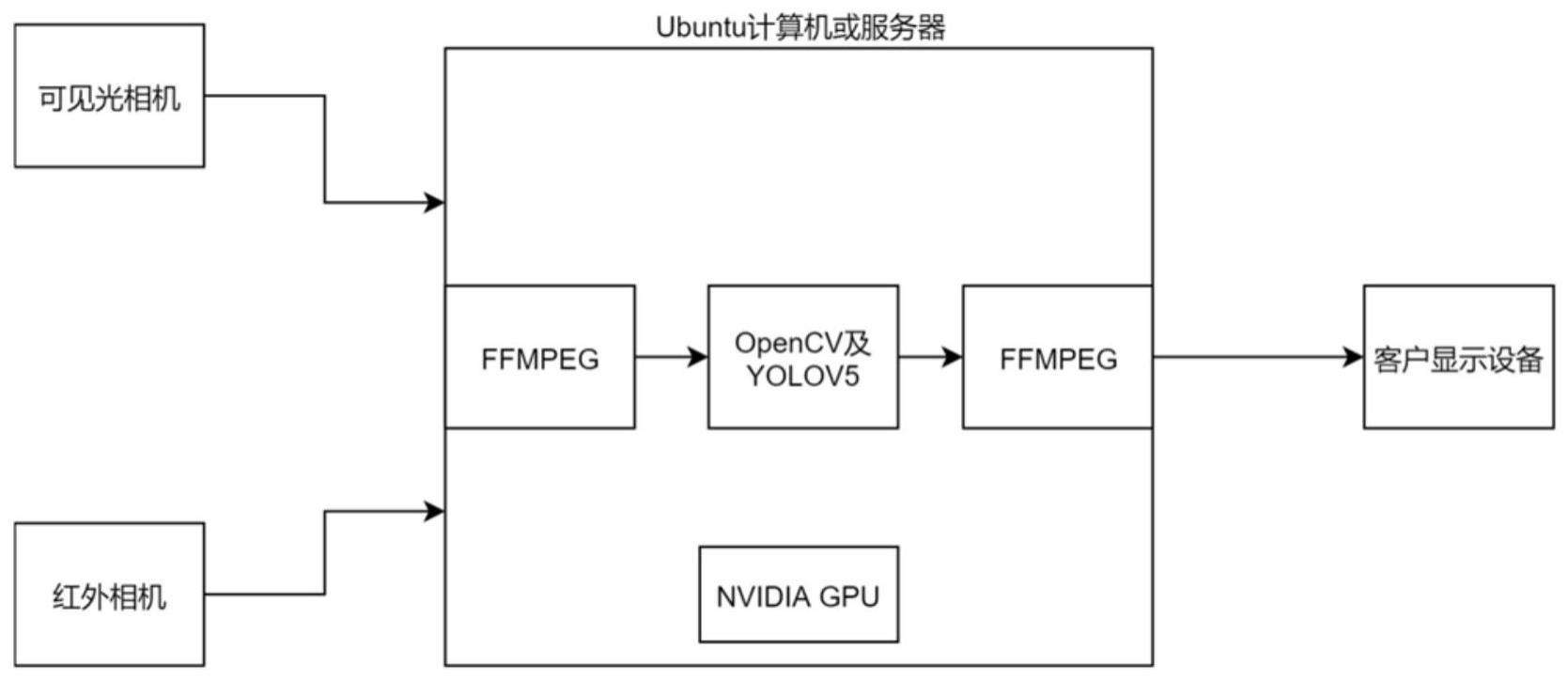
2、技术方案:本发明所述基于目标检测的实时双光谱融合视频流显示方法,包括如下步骤:捕捉可见光视频和红外视频;读取可见光视频流和红外视频流,分别标记为流a和流b;构建两条流水线管道,对流a和流b分别解码并编码为一系列bgr视频帧图像,从流水线管道输出缓冲区中读取每一帧图像的b/g/r颜色分量信息;对每一帧图像使用目标检测算法,获取目标的位置信息;根据检测到的目标位置信息,从流a和流b的帧图像中获取对应位置的颜色数组信息,将流a中的颜色数组信息替换流b中对应位置的颜色数组信息,完成单帧图片的双光融合;将融合后的帧图像转换为图片格式,并逐帧输出至内存缓冲队列,当内存缓冲队列满时,构建用于接收格式帧图片的流水线管道,合成为视频流,推送至对应端口;从推送端口接收视频流,转发视频流并将其在前端显示设备中播放,以实现双光谱融合视频流的实时显示。
3、进一步完善上述技术方案,分别采用可见光相机、红外相机捕捉可见光视频和红外视频以及通过网络传输对应的视频流。
4、进一步地,利用python构建用于读取视频流的两条pipeline流水线管道,使用ffmpeg和nvidia联合推出的cuvid库的硬解码功能,在nvidia gpu上分别读取这两路视频流数据,并逐帧编码为一系列bgr视频帧图片。
5、进一步地,使用python从两条流水线管道的输出缓冲区中读取每一帧图像的b/g/r三个颜色分量的信息,并用python的numpy库处理为能被opencv直接读取的nparray格式数据。
6、进一步地,使用yolov5算法接收nparray格式的图片数据,提取图像关键特征,然后利用神经网络结构识别待检测目标,并预测检测到的每一个目标的类别,选择概率最高的类别作为预测类别,最后利用非极大值抑制nms来去除重复检测框,最后并为每一帧图像输出一组检测到的目标检测框的位置,其中,检测框位置信息包括了目标的上下左右坐标以及这个目标的预测类别和预测分数,这些位置信息被暂存在一个自定义的缓冲区数据池中。
7、进一步地,采用opencv从缓冲区数据池中读取yolov5输入的检测框位置,每读到一帧的检测框信息,就依据检测框的上下左右坐标信息,将流a当前帧对应位置的检测目标的颜色数组信息拷贝下来,再用拷贝下来的信息将流b当前帧的对应位置的颜色数组信息替换,从而完成单帧图片的合成。
8、进一步地,opencv将合成后的单帧图片数组信息转换为jpg格式的图片,逐帧输出到内存缓冲队列中,当内存缓冲队列满时,使用python构建一条用于接收jpg格式帧图片的pipeline流水线管道,下达系统指令,使ffmpeg接收队列中的图片,并使用cuvid库的硬编码功能在nvidia gpu中合成为h264视频流,封装为flv格式的rtmp视频流,推送到对应端口。
9、进一步地,使用nginx从视频流推送端口中接收视频流,并代理和转发视频流,将其在前端显示设备中播放,从而实现了基于目标检测的实时双光谱融合视频流的显示。
10、进一步地,yolov5算法接收了nparray格式的每一帧图片,开始进行目标识别,包括如下步骤:首先利用卷积神经网络模型来提取图像的关键特征;在特征提取的基础上,yolov5使用darknet神经网络结构进行目标检测,darknet神经网络结构会将输入的图像分割为多个小的区域,并为每个区域生成一系列的候选框,预测每个候选框中是否包含一个目标,以及这个目标的位置和大小;对于检测到的每个目标,yolov5采用多分类器预测它的类别,多分类器会输出每个类别的概率,最后选择概率最高的类别作为这个目标的预测类别;yolov5采用非极大值抑制算法来去除重复的检测框,非极大值抑制算法会比较所有检测框的预测分数,并保留分数最高的检测框,同时去除与这个检测框重叠度过高的其他检测框;yolov5算法会为每一帧图像生成一组检测框的位置,每个检测框的位置包括了目标的上下左右坐标,以及这个目标的预测类别和预测分数,这些位置信息可以被用来定位待检测目标,从而完成目标识别任务。
11、用于实现上述的基于目标检测的实时双光谱融合视频流显示方法的系统,包括:至少一台用于捕捉可见光视频的可见光相机和一台用于捕捉红外视频的红外相机;用于接收和处理可见光相机和红外相机传输的视频流的计算机或服务器,所述计算机或服务器配备有nvidia gpu,运行在ubuntu系统上;所述ubuntu系统运行有基于深度学习技术的目标检测算法和图像处理软件,所述目标检测算法采用特征提取、目标检测、类别识别和非极大值抑制,用于检测目标并提供目标的位置、类别和预测分数信息;所述图像处理软件采用python编程语言和opencv库实现,用于从视频流中提取颜色信息、执行目标检测算法、融合两路视频流、生成合成帧图像并输出至内存缓冲队列;用于显示双光融合视频流的显示设备。
12、有益效果:本发明采用了双光谱融合技术,将可见光和红外光的信息融合在一起,可以更加全面、精准地展示显示目标。
13、与传统的单光相机方式相比,本发明具有以下优点:(1)更加精准:基于深度学习的目标检测算法,可以精准地检测和识别目标,提高检测的精准度和准确性;(2)更加实用:实时的双光融合视频流显示方法,可以实时地展示更为丰富的目标检测信息,方便实际应用场景中的使用,降低用户的认知负担;(3)更加安全性:在某些特殊应用场景中,如工业巡检、安防监控等,双光融合视频流可以帮助检测人员发现隐蔽的安全隐患,提高安全性。
- 还没有人留言评论。精彩留言会获得点赞!