未知协议流量数据明密态的细粒度识别方法与流程
本发明涉及数据识别领域,特别涉及一种未知协议流量数据明密态的细粒度识别方法。
背景技术:
1、随着网络应用协议版本更新迭代以及新增网络应用层出不穷,网络流量数据构成越来越复杂,未知协议流量占比也越来越高。根据是否对协议报文进行加密封装分为加密协议和明文协议。对于加密协议,大多数协议报文由明文数据和密文数据共同组成,少部分为全密文数据;对于明文协议,协议报文中也可能存在密文数据,例如ftp协议传输的内容是加密文件。
2、当前业界对未知协议流量进行明密态识别主要是判断流量会话或数据包是否加密,属于粗粒度的分析,分析结果为会话级或报文级的流量明密态。通常方法是去掉一定长度的包头字节后对剩余数据进行明密检测,根据检测结果判定是否为加密流量。由于不同协议包头长度不一,且明密分布情况差异较大,例如明文密文可能相间分布,因此该方法存在一定局限性,且无法还原字节级的流量明密态。
3、近几年也有研究人员提出了细粒度的字节级的流量明密态分析方法,主要思想是,对同一格式的多个数据包进行纵向对齐,将同一偏移位置的字节形成序列后进行明密检测。然而该方法在实际应用中普适性不强:首先,该方法需要获取足够多的数据包进行判别;其次,需保证所有对齐数据包的格式一致,由于可能存在不固定的tlv字段,即使同一种协议下也无法保证数据包格式完全一致;此外,由于大多协议存在动态变长域,无法保证数据包所有偏移位置都能对齐。
技术实现思路
1、针对现有技术中存在的问题,提供了一种未知协议流量数据明密态的细粒度识别方法,未知协议流量的字节级明密态识别难题,通过双模型检测提高了识别准确率和明态数据召回率,不受限于需获取大量同类数据包的前提,也无需考虑同类数据包对齐而截断或填充字节的问题。
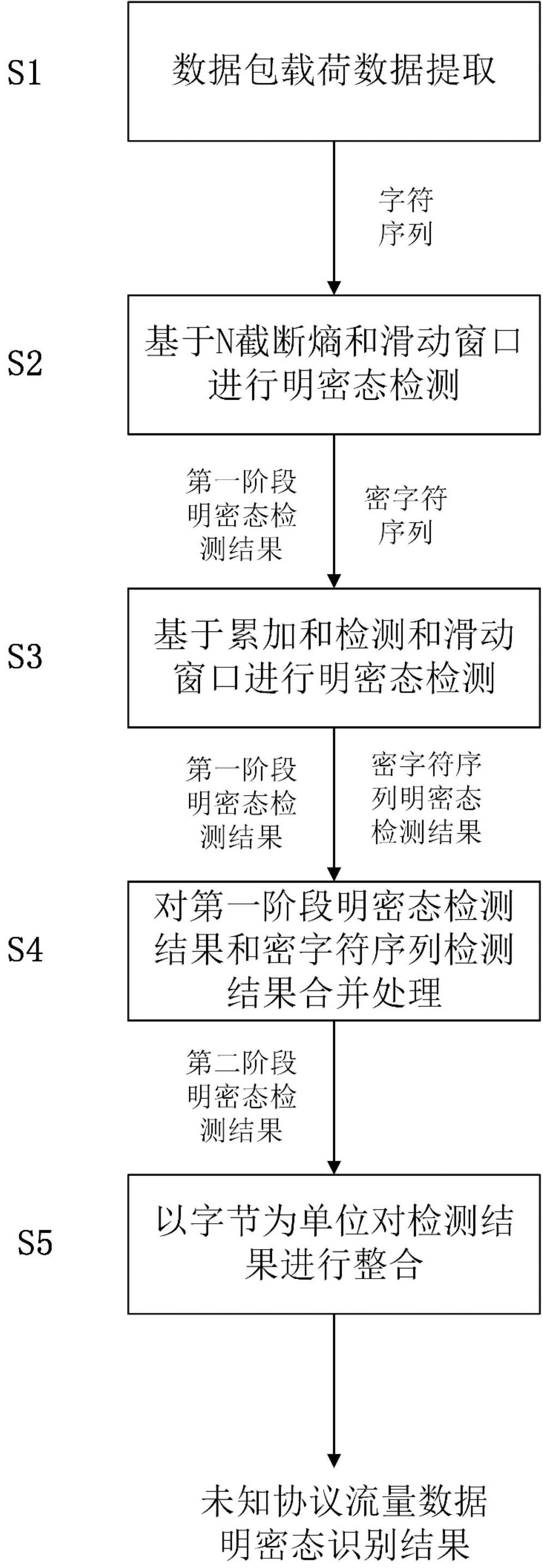
2、本发明采用的技术方案如下:未知协议流量数据明密态的细粒度识别方法,包括:
3、s1、提取数据包载荷数据,形成输入序列;
4、s2、对输入序列进行基于n截断熵和滑动窗口的明密态检测,得到第一阶段明密态检测结果;
5、s3、根据第一阶段明密态检测结果中标记为密态的位置,在输入序列中提取对应位置的字符形成新序列,并对新的序列进行基于累加和检测与滑动窗口的明密态检测,得到新序列检测结果;
6、s4、将新序列的检测结果按序列依次替换写入第一阶段明密态检测结果中标记为密文的位置,得到第二阶段明密态识别结果;
7、s5、以字节为单位对第二阶段明密态识别结果进行整合得到未知协议流量数据明密态识别结果。
8、进一步的,所述输入序列不小于16字节,若数据包载荷数据长度小于16字节,则将多个数据包的载荷数据拼接为输入序列。
9、进一步的,所述步骤s2中基于n截断熵和滑动窗口的明密态检测过程为:
10、s2.1、设定滑动窗口大小为n,并计算n截断熵与判断n长序列随机性的阈值;
11、s2.2、将滑动窗口在输入序列上的当前偏置位置cur置零;
12、s2.3、若输入序列长度,则将输入序列上窗口对应位置标记为1,得到输入序列第一阶段明密态检测结果,其中,1表示密态,0表示明态,进入步骤s3;否则进入步骤s2.4;
13、s2.4、计算当前滑动窗口内数据的熵值h,若,进入步骤s2.4;若,进入步骤s2.5;
14、s2.5、计算窗口内数据熵值变为的最小步长h,窗口右移h,并将输入序列上窗口右移滑过对应位置为1,cur+=h,进入步骤s2.3;
15、s2.6、计算窗口内数据熵值变为的最小步长h,窗口右移h,并将输入序列上窗口右移滑过对应位置为0,cur+=h,进入步骤s2.3。
16、进一步的,所述步骤s2.1中,判断n长序列随机性的阈值的确定方法为:记熵的平均值为,标准偏差为,通过调整参数得到在范围内的随机序列样本的置信度,在设定的置信度下,确定的值,从而得到n长序列明密判断阈值。
17、进一步的,所述步骤s3的子步骤包括:
18、s3.1、根据第一阶段明密态检测结果中标记为1的位置,从输入序列中提取对应位置的字符形成新序列,
19、s3.2、设置滑动窗口大小为,将滑动窗口在新序列上的当前偏置位置置零,置信度为;
20、s3.3、若新序列长度,判断窗口内字符序列的累加和检测值是否大于,若大于则将新序列窗口位置标记为1,进入步骤s3.7,若小于则将新序列窗口位置标记为0,进入步骤s3.7;若新序列长度,则进入步骤s3.4;
21、s3.4、判断窗口内字符序列的累加和检测值是否大于,若是进入步骤s3.5;否则进入步骤s3.6;
22、s3.5、计算窗口内数据变为非随机的最小步长公式,窗口右移,并将新序列上窗口右移滑过对应位置为1,+=,进入步骤s3.3;
23、s3.6、计算窗口内数据变为随机的最小步长公式,窗口右移,并将新序列上窗口右移滑过对应位置为0,+=,进入步骤s3.3;
24、s3.7、得到新序列所有位置的检测结果。
25、进一步的,所述累加和检测值计算方法为:
26、s3.3.1、将窗口内字符序列转化为0-1比特序列;
27、s3.3.2、将比特序列中元素0变换为-1,元素1不变得到新比特序列;
28、s3.3.3、分别前向和后向遍历新比特序列,计算每个位置的累加和;
29、s3.3.4、分别计算前向和后向遍历结果中累加和最大结果值;
30、s3.3.5、分别计算前向和后向遍历结果的累加和检测值;
31、s3.3.6、将前向和后向遍历结果的累加和检测值中较小的值作为种种的累加和检测值。
32、进一步的,所述步骤s3.3.5中,累加和检测值计算方法为:
33、
34、其中,为标准正态分布函数,z为前向或后向遍历结果中累加和最大结果值,表示输入序列前向或后向k个比特的累加和,表示输入的比特序列长度。
35、进一步的,所述步骤s4的具体过程为:将新序列的检测结果按顺序依次替换写入第二阶段明密态识别结果中标记为1的位置,得到输入序列的第二阶段明密态识别结果。
36、进一步的,所述步骤s5的具体过程为:
37、s5.1、对第二阶段明密态识别结果内每个元素,若元素为0,则扩充为个0,若为1,则扩充为个1,形成新的0-1序列;为字符宽度;
38、s5.2、从序列中读取8个字符,若1的数量超过4个则标记为1,否则标记为0;
39、s5.3、依次连续从序列中读取8个字符并标记,直到读取完所有字符,将标记结果按顺序形成最终的未知协议流量数据明密态识别结果。
40、与现有技术相比,采用上述技术方案的有益效果为:本发明实现了细粒度的分析,分析结果为字节级的流量明密态,普适性较强,也可用于除流量载荷数据外的其他数据(例如文件数据)的明密态识别。
- 还没有人留言评论。精彩留言会获得点赞!