面向6G基于部分可观测主动推理的智能资源分配方法
本发明属于无线通信,具体涉及面向6g基于部分可观测主动推理的智能资源分配方法。
背景技术:
1、资源分配是无线通信网络中的一个重要关键技术,高效的资源分配有助于充分利用宝贵且有限的资源,显著提升诸多通信指标。如频谱利用效率,能量效率等。然而,如何为未来的第六代(6g)无线通信网络设计高效的资源分配方案是一个极具挑战性的问题。一方面,6g无线通信网络中,能量、频谱、计算、缓存等多域资源的联合优化是主要趋势,高维决策变量深度耦合,导致优化问题难以求解;另一方面,随着各种智能可穿戴设备的盛行,为了满足6g用户的沉浸式体验,无线通信环境和用户业务需求会随着时间动态变化,因此实时的资源分配方法至关重要。
2、现有的资源分配方法可以分为两类:基于传统优化理论的方法和以深度强化学习(drl)为代表的基于机器学习的智能方法。基于传统优化理论的方法主要采用交替优化和逐次凸逼近等传统数学技巧。yuhao wang,long chen,yifan zhou,fuhui zhou等人发表的文章“resource allocation and trajectory design in uav-assisted jammingwideband cognitive radio networks”(ieee trans.cogn.commun.netw.,vol.7,no.2,pp.635-647,2022)中,为了最大化正交频分复用频谱共享网络的平均保密率,作者提出了一种基于连续凸逼近的资源分配算法,对次级基站的发射功率和无人机(uav)的飞行轨迹进行联合优化。然而,未来无线通信网络中的资源分配问题一般是非确定性多项式困难(np-hard)的,采用基于传统优化理论的方法难以获得最优解。此外,高计算复杂度和计算延时无法适应未来6g通信网络的需求。
3、近年来,drl以其高效、快速处理大规模复杂问题的突出优势,被广泛应用于设计智能的资源分配方案。公布号为cn113613332a的专利“基于协作分布式dqn联合模拟退火算法的频谱资源分配方法和系统”公开了一种基于协作分布式深度强化学习的方法,各个智能体共享同一个网络模型,相同的奖励函数,利用所有的智能体先前所收集到的经验来训练同一个深度q学习网络(dqn),这样能大大减少训练所需的内存和计算资源。但是这种方法仅仅考虑了单一的决策变量,通信场景过于理想,忽略了未来无线通信网络的异构复杂性。wei wu,fengchun yang,fuhui zhou等人在其发表的文章“intelligent resourceallocation for irs-enhanced ofdm communication systems:a hybrid deepreinforcement learning approach”(ieee trans.wireless commun.,2022)中,考虑了一个智能反射面增强的正交频分复用网络,设计出了联合dqn和深度确定性策略梯度算法的决策方案,实现了用户和传输速率的提升。但是这样的网络结构过于复杂,带来了巨大的计算开销。此外,基于drl的方法依赖于环境反馈来优化长期预期奖励。因此,基于drl的方法收敛速度较慢,这限制了它的实际部署能力,难以应用于未来6g无线通信网络。
4、总的来说,基于传统优化理论的资源分配方法难以应对6g通信环境的复杂动态性,智能的深度强化学习方法实时性差,实际部署困难。且大部分现有工作都假设能够获得完备的环境观测,然而,由于感知设备的能力不足,通信和计算开销有限,这在实际系统中是不现实的。因此,亟需开发新的适用于6g通信网络的资源分配通用框架。
技术实现思路
1、本发明所要解决的技术问题是针对上述现有技术的不足,提供面向6g基于部分可观测主动推理的智能资源分配方法,通过一种新型的部分可观测深度多智能体主动推理框架,提升了资源分配效率,加快了收敛速度,在实际通信场景中性能较好、收敛速度快且满足实时性要求、不依赖环境全观测状态。
2、为实现上述技术目的,本发明采取的技术方案为:
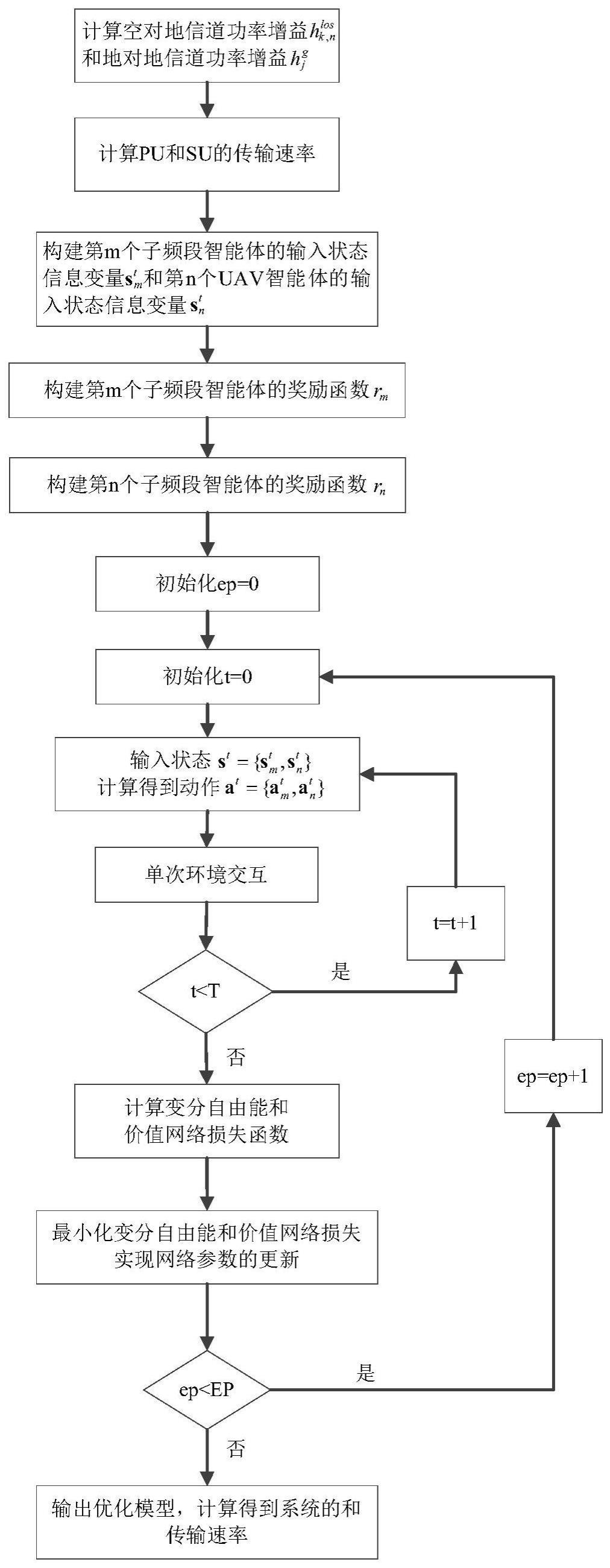
3、面向6g基于部分可观测主动推理的智能资源分配方法,包括:
4、步骤1、计算uav到次级用户su的信道功率增益,主基站到主用户pu的信道功率增益;
5、步骤2、基于步骤1计算得到的信道功率增益计算su和pu的传输速率;
6、步骤3、构建子频段智能体的输入状态信息变量、uav智能体的输入状态信息变量;
7、步骤4、基于传输速率,构建子频段智能体的奖励函数、uav智能体的奖励函数;
8、步骤5、将训练回合ep初始化为0;
9、步骤6、将ep回合中的时间步t初始化为0;
10、步骤7、根据步骤3构建的输入状态信息变量得到输入的状态,分别获取子频带分配动作和无人机飞行方向动作;
11、步骤8、根据步骤4构建的奖励函数获取网络的即时奖励,完成单次环境交互,切换到下一个时刻的状态,并将经验样本存放到经验池中;
12、步骤9、判断是否满足时间步t<t,t为ep回合的总步数,若是则t=t+1,返回步骤7,若不是则进入步骤10;
13、步骤10、计算变分自由能和价值网络损失;
14、步骤11、最小化变分自由能和价值网络损失实现网络参数的更新;
15、步骤12、判断是否满足ep<ep,ep为总回合数,若是,则ep=ep+1,返回步骤6,若不是,则优化结束,得到优化后的算法模型以用于智能资源分配,计算此时的次级网络传输速率。
16、为优化上述技术方案,采取的具体措施还包括:
17、上述的步骤1包括:
18、步骤1-1、设置单位距离时信道功率增益βref;
19、步骤1-2、计算第n个uav到第k个su之间的距离pbs到第j个pu之间的距离
20、步骤1-3、根据βref、计算uav到su之间的信道功率增益根据βref、计算主基站pbs到pu之间的信道功率增益
21、上述的步骤2包括:
22、步骤2-1、按照下式计算第n个uav与第k个su在第m个子频带的信噪比
23、
24、其中,和分别表示uav和pbs在第m个子频段上的发射功率,σ2表示噪声功率,j表示pu的总数,ρk,n[m]=1是一个二进制变量,用来表示第m个子频段是否被占用,当ρk,n[m]=1时,第m个子频段被第n个uav与第k个su之间的通信链路占用,否则ρk,n[m]=0;
25、为第n个uav到第k个次级用户su的信道功率增益、主基站到第j个主用户pu的信道功率增益;
26、步骤2-2、计算第k个su和第j个pu的传输速率:
27、
28、
29、其中,b表示每个子频段的带宽。
30、上述的步骤3第m个子频段智能体的输入状态信息变量:
31、
32、其中表示第m个子频段智能体在第t-1个时间步长时的频段分配策略;
33、为第n个uav到第k个次级用户su的信道功率增益、主基站到第j个主用户pu的信道功率增益;和分别表示uav集合和次级用户集合,是对和的集合,是传输速率的集合;
34、表示第t-1个时间步长uav的位置,为部分可观测状态输入;
35、构建第n个uav智能体的输入状态信息变量
36、上述的步骤4构建第m个子频段智能体的奖励函数rm:
37、
38、其中α1,α2,α3,和α4均为非负常数,是当pu的最小传输速率未被满足时的惩罚项,和是当高传输速率需求和低传输速率需求用户的和传输速率未得到满足时的惩罚项;具体表达式如下:
39、
40、
41、
42、其中,和分别表示高传输速率需求用户和低传输速率需求用户的最低传输速率阈值。
43、上述的步骤4构建第n个uav智能体的奖励函数rn:
44、
45、其中和分别是高传输速率需求用户和低传输速率需求用户组成的集合,dk,n是第k个su到第n个uav之间的距离;
46、是一个惩罚项,当uav与低速率需求用户之间的距离大于阈值dthr时降低和奖励,具体表示为:
47、
48、上述的步骤7根据输入的状态分别获取子频带分配动作和无人机飞行方向动作
49、上述的步骤8获取网络的即时奖励完成单次环境交互,切换到下一个时刻的状态和将经验样本{st+1,st,st-1,at+1,st,rt}存放到经验池中。
50、上述的步骤10包括:
51、步骤10-1、计算主动推理转换模型的输出aμ(st-1,at-1),a(·)和μ分别表示主动推理转换模型的映射和网络参数矩阵,通过与st计算最小二乘误差得到网络损失其中表示最小二乘损失函数;
52、步骤10-2、主动推理目标网络输出目标期望自由能qω(st+1),q(·)和ω分别表示目标网络的映射和网络参数矩阵,策略网络输出π(·)和分别表示策略网络的映射和网络参数矩阵,通过一步自举得到估计期望自由能
53、步骤10-3、价值网络通过状态输入st得到输出gθ(at|st),g(·)和θ分别表示价值网络的映射和网络参数矩阵,通过估计期望自由能与目标自由能之间的差异得到主动推理价值网络损失
54、步骤10-4、将动作上的分布建模为价值网络期望自由能估计上的精度加权玻尔兹曼分布σ(-γgθ(at|st)),结合策略网络输出熵ht,转换模型损失函数l(μ),价值网络输出gθ(at|st),计算得到主动推理的内在变分自由能
55、上述的步骤11根据梯度下降算法对网络参数进行更新,
56、
57、
58、
59、其中,∈t,∈p和∈v分别是转换模型,策略网络和价值网络的学习率,表示梯度计算操作。
60、本发明具有以下有益效果:
61、本发明通过一种新型的面向6g资源分配的部分可观测深度多智能体主动推理通用框架,利用基于信念的学习方法实现主动推理,通过最小化自由能来模拟智能体在现实世界中的行为,通过分布式训练分布式执行的多智能体解决部分可观测系统中分布式智能体之间的信息缺失问题,不仅能够提升资源分配性能而且能够提升决策速度。本发明能使得频谱共享系统获得最大的资源分配效率和速率,且加快了网络的收敛速度,实时性更强,且框架的泛化能力强,能够拓展到各种无线通信场景,这使得该发明在实际中能更好的得到应用。
62、相比于传统的完全依赖外部奖励的深度强化学习方法,本发明提出的深度主动推理方法最小化智能体自身的内在自由能,通过基于信念的学习方法完成智能体的自动更新,相比于深度强化学习更符合实际,因此能够获得更快的收敛速度。
63、分布式训练分布式执行的多智能体学习框架能够克服传统方法依赖环境全观测的假设,且以子频段为主体的多智能体协作方式大大降低了动作空间维度,因此能够节省计算和存储开销。
64、本发明首次在多无人机频谱共享场景中考虑了用户的动态传输速率需求,在该系统模型中验证了所提出的podmai框架,相比于传统的基于优化的算法,解决了众多参数难以同时在线优化的问题,且框架泛用性强,很容易扩展到各种系统场景。
- 还没有人留言评论。精彩留言会获得点赞!