一种超级计算机的网络拓扑构建方法及网络拓扑结构与流程
本发明涉及超级计算机,具体是一种超级计算机的网络拓扑构建方法及网络拓扑结构。
背景技术:
1、为了简化超级计算机系统的网络拓扑结构,提高超级计算机系统的运行稳定性,当前大型超级计算机普遍采用了i/o转发架构。如图1所示,计算结点与i/o转发结点通过计算网络互连,i/o转发结点与存储结点通过存储网络互连。作业运行在计算结点上,当作业需要读写数据时,其i/o请求从计算结点发送给i/o转发结点,由i/o转发结点转发给存储结点。计算结点的数据读写请求须经i/o转发结点转发后才可发送给存储结点。
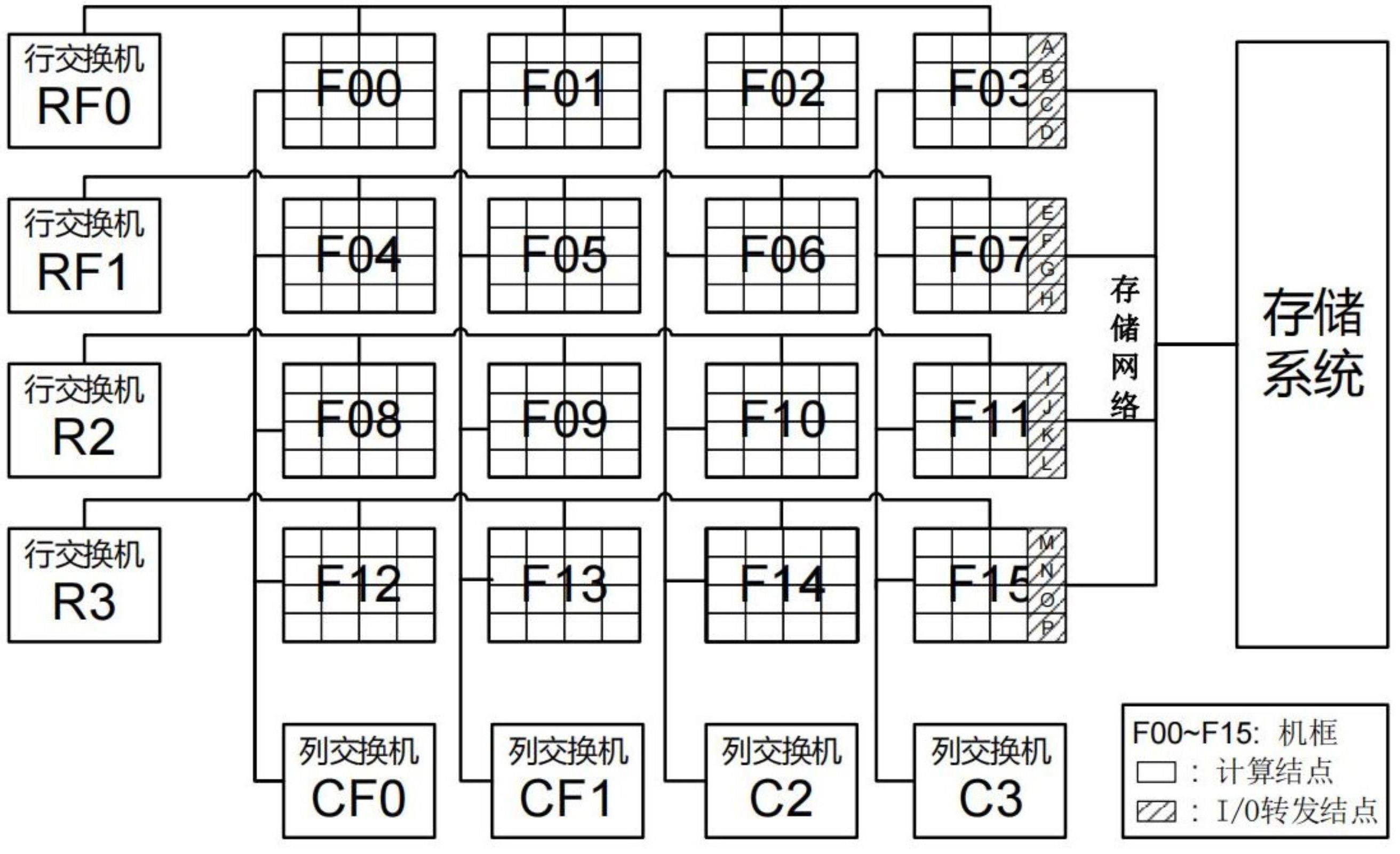
2、在采用二维网络拓扑的超级计算机中,计算网络采用二维网络结构。如图2所示,网络中的结点(包括计算结点与i/o转发结点)被分组(如64个或128个)放置在机框中,机框内的结点间只需通过框内交换板即可互连通信。在网络逻辑拓扑中,机框是二维网络中的最小连接单位,机框以行列形式呈二维排列。同一行的机框连接着同一个交换机,并且同一列的机框连接着同一个交换机,即每个机框同时连接着一个行交换机与一个列交换机。同行的机框之间只需通过该行的1个交换机即可互连,同列的机框之间只需通过该列的1个交换机即可互连。不同行且不同列的机框必须通过两个交换机才能互连,例如机框f00中的计算结点与机框f11中的计算结点通信,须先经过行交换机r0跳转至该两机框的行列交点处的机框f03,再经过列交换机c3跳转至目的机框f11。可见,在采用二维网络拓扑的超级计算机中,框内结点间通信的网络距离最短,同行或同列的框间通信网络距离次之,不同行且不同列的框间通信网络距离最长。在超级计算机生产系统中,跨行跨列的通信不但会增加通信延迟,影响通信效率,更会造成二维网络中的通信泛洪,易造成通信阻塞,影响通信系统运行稳定性。因此采用二维网络拓扑之后,超级计算机必须尽量减少跨行跨列的通信行为,以提升通信效率与网络稳定性。
3、然而,目前在采用二维胖树网络拓扑的超级计算机中,i/o转发架构设计仍存在一定优化空间。在超级计算机的实际部署中,考虑到设计与维护的便利性,通常将i/o转发结点集中放置在一个或少数几个机框中。例如,在图2所示的超级计算机中,i/o转发结点全部位于机框f15中,该种i/o转发架构存在以下两个方面的问题:
4、(1)有3个机框(f03、f07、f11)的计算结点与i/o转发结点处于同一列中,通信需经过1台列交换机(c3);有3个机框(f12、f13、f14)的计算结点与i/o转发结点处于同一行中,通信需经过1台行交换机(r3);有9个机框(f00~f02、f04~f06、f08~f10)的计算结点与i/o转发结点既不在同一行中,也不在同一列中,通信需经过2台交换机。上述现象将会产生两个方面的性能影响,一是由于大部分机框的计算结点需要经过跨行跨列通信才能与i/o转发结点通信,严重影响了这些计算结点的数据读写效率,并造成二维网络上的通信泛洪,造成网络互连系统运行不稳定;二是集群系统中所有的i/o流量都将发往机框f15中的i/o转发结点,造成该机框的通信负载较大,该机框的运行稳定性也将受到影响。
5、(2)当前i/o转发构架多采用集中映射的方式,即同一个或相邻几个机框里的计算结点共享使用一个i/o转发结点。例如,在图2中机框f00中计算结点的i/o请求全部交由机框f15中的i/o转发结点a处理,类似的,机框f01中计算结点与i/o转发结点b对应。据统计,一个作业更容易被分配到相邻的计算结点,因此相邻的计算结点更容易同时读写数据,这将造成一小部分i/o转发结点过载,导致负载不均。
6、由于i/o转发结点是连接计算结点与存储服务器的桥梁,i/o转发结点承担了超级计算机系统上所有的i/o流量,在以上存储转发架构下,几乎所有的i/o流量都必须跨行跨列与一小部分i/o转发结点通信,在二维网络中产生大量聚集的通信数据包,造成通信阻塞,严重影响了互连通信系统的运行稳定性,并影响了i/o效率。
7、当前采用二维网络拓扑的超级计算机中,其存储转发架构并没有针对以上“跨行跨列通信问题”进行特殊设计,于是便产生了两个方面的问题。(1)当前的i/o转发结点一般集中地连接在一个或少数几个机框交换板上,因此除了与这些i/o转发结点所在机框同行同列的机框外,绝大部分机框内的计算结点都与i/o转发结点既不同行也不同列,计算结点与i/o转发结点的通信必须经过两台交换机;(2)当前i/o转发构架多采用集中映射的方式,即同一个或相邻几个机框里的计算结点共享使用一个i/o转发结点,据统计,一个作业更容易被分配到相邻的计算结点,因此相邻的计算结点更容易同时读写数据,这将造成一小部分i/o转发结点过载,导致负载不均。由于i/o转发结点是连接计算结点与存储服务器的桥梁,i/o转发结点承担了超级计算机系统上所有的i/o流量,在以上存储转发架构下,几乎所有的i/o流量都必须跨行跨列与一小部分i/o转发结点通信,在二维网络中产生大量聚集的通信数据包,造成通信阻塞,严重影响了互连通信系统的运行稳定性,并影响了i/o效率。
技术实现思路
1、为克服现有技术的不足,本发明提供了一种超级计算机的网络拓扑构建方法及网络拓扑结构,解决现有技术存在的以下问题:在二维网络中产生大量聚集的通信数据包,造成通信阻塞,严重影响了互连通信系统的运行稳定性,并影响了i/o效率等。
2、本发明解决上述问题所采用的技术方案是:
3、一种超级计算机的网络拓扑构建方法,将计算结点划分成组、将i/o转发结点分组放置,并改变i/o转发方式,使得计算结点只能共享使用本组内的i/o转发结点。
4、作为一种优选的技术方案,在同一组中,i/o转发结点轮询服务相邻计算结点。
5、作为一种优选的技术方案,包括以下步骤:
6、s1,将计算结点与i/o转发结点进行分组放置;
7、s2,将计算结点与i/o转发结点进行分组轮询映射。
8、作为一种优选的技术方案,步骤s1包括以下步骤:
9、s11,将超级计算机的计算结点按行或按列分组:计算超级计算机二维网络拓扑的行数与列数,比较两值并取较小者,将较小值记为;若,则按行将计算结点分组为组;若,则按列将计算结点分组为组;
10、s12,计算i/o转发结点数量,根据步骤s11得出的分组数量,计算每组平均分配的i/o转发结点数量;
11、s13,在二维网络的每一组中,根据机框与存储系统的物理位置与二者之间的布线距离,在距存储系统最近的机框中放置个i/o转发结点;
12、s14,将映射方式设置成局部的分组映射模式:每组计算结点无法使用所有的i/o转发结点,只能使用组内的i/o转发结点。
13、作为一种优选的技术方案,步骤s14中,若是采用lustre lnet router的i/o转发架构,则更改router设置,将每个计算结点的router设置成计算结点所在组的i/o转发结点,并重启i/o转发服务。
14、作为一种优选的技术方案,步骤s2包括以下步骤:
15、s21,根据计算结点的分组结果,计算每一组中计算结点的数量,将计算结点记为;计算每一组中i/o转发结点的数量,将i/o转发结点记为;其中,i表示计算结点序号,m表示计算结点数量,0≤i≤m,j表示i/o转发结点序号,n表示i/o转发结点数量,0≤j≤n;
16、s22,对于每一组中的计算结点,将映射至i/o转发结点,以使计算结点的所有i/o请求将交由该i/o转发结点处理。
17、一种超级计算机的网络拓扑结构,采用所述的一种超级计算机的网络拓扑构建方法构建,包括:行数为、列数为的机框,机框中包括计算结点、i/o转发结点,计算结点与i/o转发结点进行分组放置;
18、在二维网络的每一组中,根据机框与存储系统的物理位置与二者之间的布线距离,在距存储系统最近的机框中放置个i/o转发结点;
19、映射方式设置成局部的分组映射模式:每一组中计算结点无法使用所有的i/o转发结点,只能使用组内的i/o转发结点。
20、作为一种优选的技术方案,对于每一组中的计算结点,将映射至i/o转发结点,以使计算结点的所有i/o请求将交由该i/o转发结点处理。
21、作为一种优选的技术方案,还包括存储网络、存储系统,每一组中i/o转发结点分别通过存储网络与存储系统通信连接。
22、作为一种优选的技术方案,还包括行交换机、列交换机,同一行中的机框共用一个行交换机,同一列中的机框共用一个列交换机。
23、本发明相比于现有技术,具有以下有益效果:
24、(1)本发明可缩短高性能计算机上运行的计算作业读写数据时的网络通信距离;
25、(2)本发明增加高性能计算机上运行的计算作业可利用的i/o转发结点数量;
26、(3)本发明减少二维通信网络中的跨行跨列通信数量,从而提高计算作业的数据读写效率、提升网络通信系统的稳定性。
- 还没有人留言评论。精彩留言会获得点赞!