视频解码方法、编码方法、电子设备及存储介质与流程
本技术描述了总体上涉及视频编解码的实施例。
背景技术:
1、本文所提供的背景描述旨在整体呈现本技术的背景。在背景技术部分以及本说明书的各个方面中所描述的目前已署名的发明人的工作所进行的程度,并不表明其在本技术提交时作为现有技术,且从未明示或暗示其被承认为本技术的现有技术。
2、通过具有运动补偿的帧间图片预测技术,可以进行视频编码和解码。未压缩的数字视频可包括一系列图片,每个图片具有例如1920×1080亮度样本及相关色度样本的空间维度。所述系列图片具有固定的或可变的图片速率(也非正式地称为帧率),例如每秒60个图片或60hz。未压缩的视频具有非常大的比特率要求。例如,每个样本8比特的1080p60 4:2:0的视频(1920x1080亮度样本分辨率,60hz帧率)要求接近1.5gbit/s带宽。一小时这样的视频就需要超过600gb的存储空间。
3、视频编码和解码的一个目的,是通过压缩减少输入视频信号的冗余信息。视频压缩可以帮助降低对上述带宽或存储空间的要求,在某些情况下可降低两个或更多数量级。无损和有损压缩,以及两者的组合均可采用。无损压缩是指从压缩的原始信号中重建原始信号精确副本的技术。当使用有损压缩时,重建信号可能与原始信号不完全相同,但是原始信号和重建信号之间的失真足够小,使得重建信号可用于预期应用。有损压缩广泛应用于视频。容许的失真量取决于应用。例如,相比于电视应用的用户,某些消费流媒体应用的用户可以容忍更高的失真。可实现的压缩比反映出:较高的允许/容许失真可产生较高的压缩比。
4、视频编码器和解码器可利用几大类技术,例如包括:运动补偿、变换、量化和熵编码。
5、视频编解码器技术可包括已知的帧内编码技术。在帧内编码中,在不参考先前重建的参考图片的样本或其它数据的情况下表示样本值。在一些视频编解码器中,图片在空间上被细分为样本块。当所有的样本块都以帧内模式编码时,该图片可以为帧内图片。帧内图片及其衍生(例如独立解码器刷新图片)可用于复位解码器状态,并且因此可用作编码视频比特流和视频会话中的第一图片,或用作静止图像。帧内块的样本可用于变换,且可在熵编码之前量化变换系数。帧内预测可以是使预变换域中的样本值最小化的技术。在某些情形下,变换后的dc值越小,且ac系数越小,则在给定的量化步长尺寸下需要越少的比特来表示熵编码之后的块。
6、如同从诸如mpeg-2代编码技术中所获知的,传统帧内编码不使用帧内预测。然而,一些较新的视频压缩技术包括:试图从例如周围样本数据和/或元数据中得到数据块的技术,其中周围样本数据和/或元数据是在空间相邻的编码/解码期间、且在解码顺序之前获得的。这种技术后来被称为"帧内预测"技术。需要注意的是,至少在某些情形下,帧内预测仅使用正在重建的当前图片的参考数据,而不使用参考图片的参考数据。
7、可以存在许多不同形式的帧内预测。当在给定的视频编码技术中可以使用超过一种这样的技术时,所使用的技术可以按帧内预测模式进行编码。在某些情形下,模式可具有子模式和/或参数,且这些模式可单独编码或包含在模式码字中。将哪个码字用于给定模式/子模式/参数组合会通过帧内预测影响编码效率增益,因此用于将码字转换成比特流的熵编码技术也会出现这种情况。
8、h.264引入了一种帧内预测模式,其在h.265中进行了改进,在更新的编码技术中,例如,联合探索模型(jem)、通用视频编码(vvc)、基准集合(bms)等等,对其进一步进行了改进。。通过使用属于已经可用的样本的相邻样本值可以形成预测块。将相邻样本的样本值按照某一方向复制到预测块中。对所使用方向的引用可以被编码在比特流中,或者本身可以被预测。
9、运动补偿可以是有损压缩技术,并且可以涉及如下技术:从先前已重建图片或其部分(参考图片)得到的样本数据块,在按照运动矢量(下文称为mv)指示的方向上进行空间移位后,用于预测新重建的图片或图片部分。在一些情况下,参考图片可以与当前正在重建的图片相同。mv可以具有两个维度:x维度和y维度,或者具有三个维度,第三个维度用于指示使用中的参考图片(后者间接地可以是时间维度)。
10、在一些视频压缩技术中,可应用于某一样本数据区域的mv,可以根据其它mv预测得到,例如,根据在空间上与正在重建的区域相邻的另一样本数据区域相关的、解码顺序在所述mv之前的mv预测得到。这样做可以实质上减少对所述mv进行编解码所需的数据量,从而消除冗余并增强压缩。mv预测可以有效地进行,例如,因为当对从摄像机导出的输入视频信号(称为自然视频)进行编码时,存在统计似然性,即,比单个mv可应用的区域大的多个区域,在相似方向上运动,因此,在一些情况下可以使用从相邻区域的多个mv导出的相似运动矢量进行mv预测。这导致所找到的用于给定区域的mv,与从周围的mv预测得到的mv相似或相同,并且在熵编解码之后,又可以用比直接对mv编解码所用的比特数少的比特数来表示。在一些情况下,mv预测可以是对从原始信号(即:样本流)导出的信号(即:mv)的无损压缩的示例。在其它情况下,mv预测本身可以是有损的,例如,因为当从若干周围mv计算预测子时,会有舍入误差。
11、h.265/hevc(itu-t h.265建议书,“高效视频编解码(high efficiency videocoding)”,2016年12月)中描述了各种mv预测机制。在h.265提供的多种mv预测机制中,本技术描述的是下文称作“空间合并”的技术。
12、请参考图1,当前块(101)包括在运动搜索过程期间已由编码器发现的样本,根据已产生空间偏移的相同大小的先前块,可预测所述样本。另外,可从一个或多个参考图片相关联的元数据中导出所述mv,而非对mv直接编码。例如,使用关联于a0、a1和b0、b1、b2(分别对应102到106)五个周围样本中的任一样本的mv,(按解码次序)从最近的参考图片的元数据中导出所述mv。在h.265中,mv预测可使用相邻块也正在使用的相同参考图片的预测值。
技术实现思路
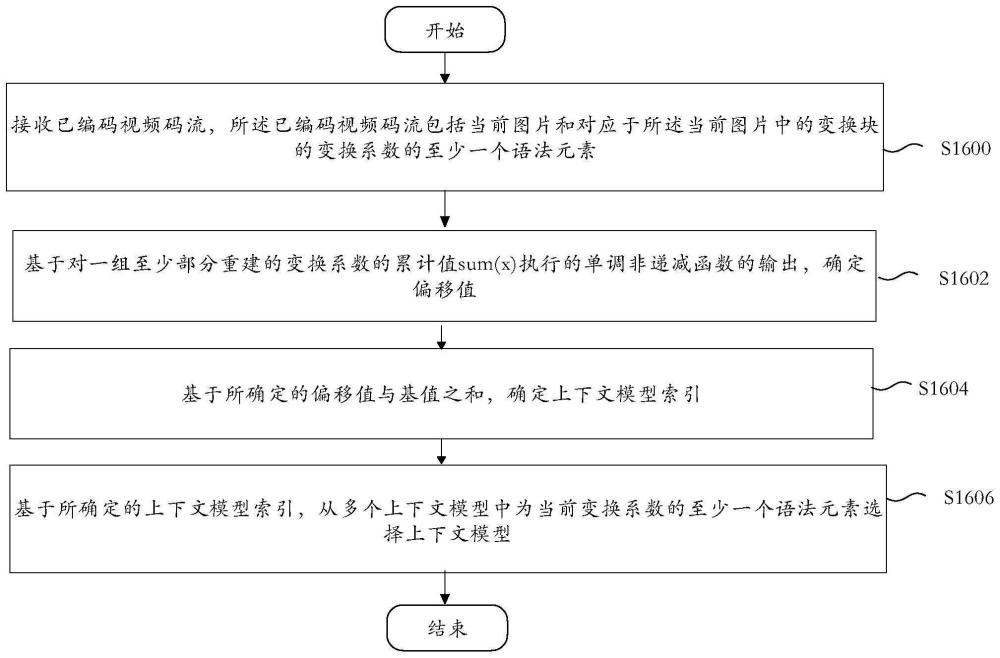
1、根据一个示例性的实施例,一种在视频解码器中执行的视频解码方法包括接收已编码视频码流,所述已编码视频码流包括当前图片和对应于所述当前图片中的变换块的变换系数的至少一个语法元素。所述方法进一步包括基于对一组至少部分重建的变换系数的累计值sum(x)执行的单调非递减函数的输出,确定偏移值。所述方法进一步包括基于所确定的偏移值与基值之和,确定上下文模型索引。所述方法进一步包括基于所确定的上下文模型索引,从多个上下文模型中为当前变换系数的至少一个语法元素选择上下文模型。
2、根据一个示例性的实施例,一种在视频解码器中执行的视频解码方法包括接收已编码视频码流,所述已编码视频码流包括当前图片和对应于所述当前图片中的变换块的变换系数的至少一个语法元素。所述方法进一步包括对于多个上下文模型区域中的每个上下文模型区域,确定单调非递减函数的输出,所述单调非递减函数是对一组至少部分重建的变换系数的累计值sum(x)和与各个上下文模型区域相关联的上下文模型的数目执行的。所述方法进一步包括基于每个上下文模型区域的所述单调非递减函数的所述输出,确定上下文模型索引。所述方法进一步包括基于所确定的上下文模型索引,从多个上下文模型中为当前变换系数的至少一个语法元素选择上下文模型。
3、根据一个示例性的实施例,一种用于视频解码的视频解码器,包括处理电路。所述处理电路被配置为接收已编码视频码流,所述已编码视频码流包括当前图片和对应于所述当前图片中的变换块的变换系数的至少一个语法元素。所述处理电路进一步被配置为基于对一组至少部分重建的变换系数的累计值sum(x)执行的单调非递减函数的输出,确定偏移值。所述处理电路进一步被配置为基于所确定的偏移值与基值之和,确定上下文模型索引。所述处理电路进一步被配置为基于所确定的上下文模型索引,从多个上下文模型中为当前变换系数的至少一个语法元素选择上下文模型。
4、根据一个示例性的实施例,一种用于视频解码的视频解码器,包括处理电路。所述处理电路被配置为接收已编码视频码流,所述已编码视频码流包括当前图片和对应于所述当前图片中的变换块的变换系数的至少一个语法元素。所述处理电路进一步被配置为对于多个上下文模型区域中的每个上下文模型区域,确定单调非递减函数的输出,所述单调非递减函数是对一组至少部分重建的变换系数的累计值sum(x)和与各个上下文模型区域相关联的上下文模型的数目执行的。所述处理电路进一步被配置为基于每个上下文模型区域的所述单调非递减函数的所述输出,确定上下文模型索引。所述处理电路进一步被配置为基于所确定的上下文模型索引,从多个上下文模型中为当前变换系数的至少一个语法元素选择上下文模型。
5、根据一个示例性的实施例,一种非易失性计算机可读介质存储有指令,当由计算机执行所述指令时,使计算机执行上述的方法。
- 还没有人留言评论。精彩留言会获得点赞!