面向联邦学习标签翻转攻击的客户端选择防御方法及系统
本发明涉及一种面向联邦学习标签翻转攻击的客户端选择防御方法及系统,属于信息安全。
背景技术:
1、传统的机器学习大多采用集中式的方法来训练机器学习模型,用户将本地数据上传到中心服务器,然后通过数据预处理、数据分割、模型选择、模型训练等步骤实现机器学习,使用所有用户的私有数据对模型进行训练固然会给模型性能带来较大的提升,然而,这种集中式的机器学习方法存在泄露用户数据,侵犯用户隐私的风险,这时候,联邦学习就应运而生了,它的核心思想是在保护用户数据隐私的前提下,实现多方共同参与的训练,解决数据孤岛问题。
2、在联邦学习训练过程中,首先,由中心服务器初始化一个全局模型,然后将初始化的全局模型分发给参与训练的客户端,接着客户端利用其本地数据集训练全局模型,在此过程中,客户端不会将本地数据共享给中心服务器,而是将训练后的模型更新发送到中心服务器用于全局聚合,最后,中心服务器将聚合后的模型分发给客户端,进行下一轮训练,迭代多次。
3、由于联邦学习分布式的特性,客户端能够完全控制自己的本地数据,服务器无法掌控客户端的行为,因此联邦学习很容易受到各种攻击。其中,较为常见的就是标签翻转攻击,它通常是由恶性客户端发起的,通过翻转某些类别样本的标签,让模型学习到错误的知识,最终诱导全局模型将源类别的样本错误分类为目标类别,来达到损害全局模型,降低模型准确率的目的。
4、为了缓解标签翻转攻击给联邦学习系统带来的危害,目前已经有了多种防御机制。当前,防御标签翻转攻击的方法主要是基于客户端的本地数据集和客户端上传至中心服务器的模型更新两个维度考虑的。
5、第一类方案可以使用支持向量机模型来对数据进行审查,通过分类模型在有毒数据集和干净数据集上产生的总误差作为判断数据集是否有毒的标准。该类方案需要深入用户层检测客户端的数据集,但是联邦学习要求客户端的数据是不公开、不共享的,因此这显然是违背联邦学习隐私安全的分布式特性。
6、第二类方案通过检测客户端上传至中心服务器的模型更新来防御标签翻转攻击,可以基于模型更新在各个维度的中位数来评估客户端的可靠程度,然后自适应的调整相应用户模型更新的权重。krum算法和multi-krum算法通过计算每一个模型更新与其余所有更新之间的欧氏距离,选择距离最小的更新用于全局模型的聚合,虽然该种办法鲁棒性较高,能够剔除掉距离其他模型较远的模型,从而减小恶性客户端的影响,但是欧氏距离的计算会浪费较多的内存和计算资源,计算复杂度非常高,对于大规模的网络来说这种防御方法是不可行的,同时它需要提前知道恶性客户端的数量,显然是不符合现实场景的。
7、上述问题是在面向标签翻转攻击的客户端选择防御过程中应当予以考虑并解决的问题。
技术实现思路
1、本发明的目的是提供一种面向联邦学习标签翻转攻击的客户端选择防御方法及系统解决现有技术中存在的计算开销大,不适用于非独立同分布场景,防御标签翻转攻击的有效性有待提高的问题。
2、本发明的技术解决方案是:
3、一种面向联邦学习标签翻转攻击的客户端选择防御方法,包括以下步骤,
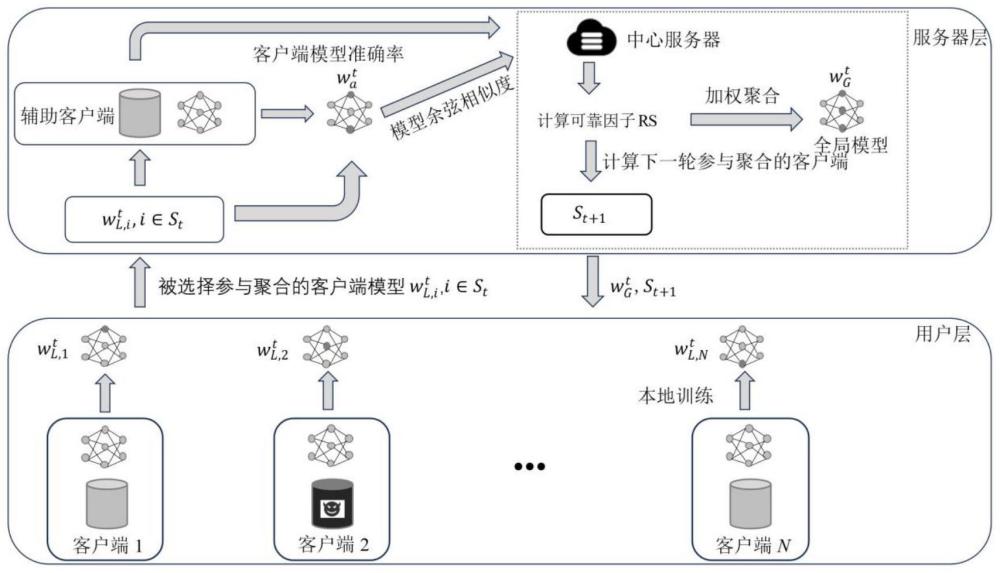
4、s1、中心服务器初始化全局模型,随机选择k个客户端,并将全局模型分发给本地客户端和辅助客户端,并初始化训练次数t=1;
5、s2、辅助客户端和本地客户端在接收到中心服务器发来的全局模型后,利用自己的本地数据集采用随机梯度下降算法训练全局模型,采取交叉熵损失函数以适应分类问题,训练完成后,本地客户端将训练后的全局模型作为本地客户端模型更新发送到服务器层;
6、s3、服务器层的辅助客户端在接收到本地客户端模型后,利用辅助客户端的辅助数据集测试本地客户端模型的准确率acc,测试完后将准确率传给中心服务器,然后中心服务器计算辅助客户端模型和本地客户端模型的余弦相似度proximity;
7、s4、中心服务器基于求得的余弦相似度proximity和准确率acc两个指标,将两者进行权重和运算,得到可靠因子,基于可靠因子对本地客户端模型进行加权聚合,并赋予良性客户端更高的权重,得到更新后的全局模型;
8、s5、基于可靠因子进一步融合本地客户端的历史良性情况,融合汤普森采样方法,选择用于进行下一轮的训练良性的客户端,得到第t轮被选中进行聚合的客户端序号的集合st;
9、s6、将步骤s4中得到的更新后的全局模型分发给步骤s5得到的第t轮被选中进行聚合的客户端序号的集合st中对应的客户端,令t=t+1,并返回步骤s2,开始下一轮训练,直至完成设定次数迭代。
10、进一步地,步骤s3中,利用辅助客户端的辅助数据集测试本地客户端模型的准确率acc:
11、
12、其中,m()是用于评估客户端模型的函数,输出模型的准确率;da是辅助客户端的辅助数据集。
13、进一步地,步骤s3中,中心服务器计算辅助客户端模型和本地客户端模型的余弦相似度proximity:
14、
15、其中,为第t轮中第i个客户端的本地模型更新,为辅助客户端在第t轮的模型更新。
16、进一步地,步骤s4中,中心服务器基于求得的proximity和准确率acc两个指标,将两者进行权重和运算,得到可靠因子rs:
17、rs=γ*proximity+ξ*acc
18、其中,γ和ξ分别是余弦相似度和准确率两个指标在可靠因子中占的比重。
19、进一步地,步骤s4中,基于可靠因子对本地客户端模型进行加权聚合,并赋予良性客户端更高的权重,得到更新后的全局模型:
20、
21、其中,是第t轮中的全局模型,是第t轮中第i个本地客户端本地训练后的模型,rsi是第t轮中第i个本地客户端的可靠因子,rsj是第t轮中第j个本地客户端的可靠因子。
22、进一步地,步骤s5中,基于可靠因子进一步融合本地客户端的历史良性情况,融合汤普森采样方法,选择用于进行下一轮的训练良性的客户端,得到第t轮被选中进行聚合的客户端序号的集合st,具体为,
23、s51、基于汤普森采样方法,将reliability定义为某客户端被判定为良性客户端的次数,unreliability定义为某客户端被判定为恶性客户端的次数,根据beta分布概率密度函数值域在[0,1]的特点,将其映射为每个客户端被选择进行下一轮聚合的概率p:p=beta(reliability,unreliability);
24、s52、在第一轮训练中,将reliability和unreliability都设定为1,此时的beta分布就是在(0,1)的均匀分布,表示在第一轮训练前,每一个客户端都有均等概率被选择进行第一轮的聚合;
25、s53、然后,在后续轮次训练过程中,当中心服务器计算客户端的可靠因子后,会对这些可靠因子进行降序排序,排在前设定比例的可靠因子,对应客户端的reliability属性值会加1,其余客户端则保持reliability值不变,unreliability属性值加1,实现实时对每个客户端的reliability和unreliability值进行更新;
26、s54、然后通过beta分布计算每一个客户端下一轮被选中的概率,为选择更加良性的客户端进行训练,将每个客户端被选中的概率进行排序,然后选择概率最大的前k个客户端进行下一轮聚合:st=maxk{p1,p2,...,pn},其中,pi为第t轮第i个客户端被选中进行聚合的概率,函数maxk表示从集合中选择最大的前k个元素,并返回选中元素下标组成的集合,st是第t轮被选中进行聚合的客户端序号的集合。
27、一种面向联邦学习标签翻转攻击的客户端选择防御系统,包括服务器层和用户层,用户层包括若干本地客户端,服务器层包括辅助客户端和中心服务器,辅助客户端用于测试客户端模型的准确率,中心服务器用于计算客户端的可靠因子和模型的加权聚合,并采用上述任一项面向联邦学习标签翻转攻击的客户端选择防御方法。
28、本发明的有益效果是:
29、一、该种面向联邦学习标签翻转攻击的客户端选择防御方法及系统,能够快速有效把恶性客户端剔除出来,选择良性客户端进行聚合,并能够较快地收敛,计算开销较小,有效防御标签翻转攻击,提高模型准确率。
30、二、本发明,结合辅助客户端与中心服务器设计可靠因子计算及加权聚合,基于辅助客户端测量的客户端模型准确率及客户端与辅助客户端模型的余弦相似度可以较小的计算开销获得客户端的可靠因子,用以评价客户端在某一训练轮次的良性程度。同时基于该可靠因子实现对模型的加权聚合,以此获得全局模型,通过赋予良性客户端更高的权重,可显著降低恶性客户端对全局模型的影响,提高模型的准确率。
31、三、该种面向联邦学习标签翻转攻击的客户端选择防御方法及系统,结合客户端历史良性情况,融合汤普森采样方法,通过对reliability和unreliability值的实时更新,并将它们的beta分布映射为对应客户端被选择的概率,实现对下一轮聚合客户端的选择。实现动态客户端选择,可以筛选出更加良性的客户端进行下一轮聚合,来提升模型的鲁棒性,防御标签翻转攻击。
- 还没有人留言评论。精彩留言会获得点赞!