本发明涉及云计算,尤其涉及一种全量sql数据采集方法、装置及系统。
背景技术:
1、在云计算领域,对云数据库的监控、运维与治理服务往往依赖于全量sql数据的实时采集,以支撑下游的sql执行情况监控、sql洞察与优化、sql安全审计与预警等应用场景。与普通的数据库sql采集不同,云数据库的关联服务更多,全量sql数据量更加庞大,对采集端的性能要求极高。
2、现有云平台对全量sql采集的技术方案有以下三种思路:
3、(1)基于数据库内核输出sql数据,这类方法性能较好,采集数据丰富,但要求对内核源码进行修改,技术门槛极高,操作复杂度极大。
4、(2)基于数据库日志的定期数据采集,这类方法操作复杂度较低,但由于不能持续查询sql日志,因此实时性差,且频繁操作数据库日志会极大影响数据库本身性能。
5、(3)基于抓包的方法,主流对数据库进行抓包的方法有pcap、pf_ring等等,这类方法通过对用户与云数据库之间交互产生的tcp协议包进行抓包解析,获取全量sql数据,这类方法需要在设备内部通过中断切换至系统态中进行抓包,稳定性较差,采集速度中等,实时性一般。
技术实现思路
1、鉴于以上现有技术的不足,发明的目的在于提供一种全量sql数据采集方法、装置及系统,针对sql数据包的特性,提供高实时、低损耗、高效率的全量sql数据采集方案。
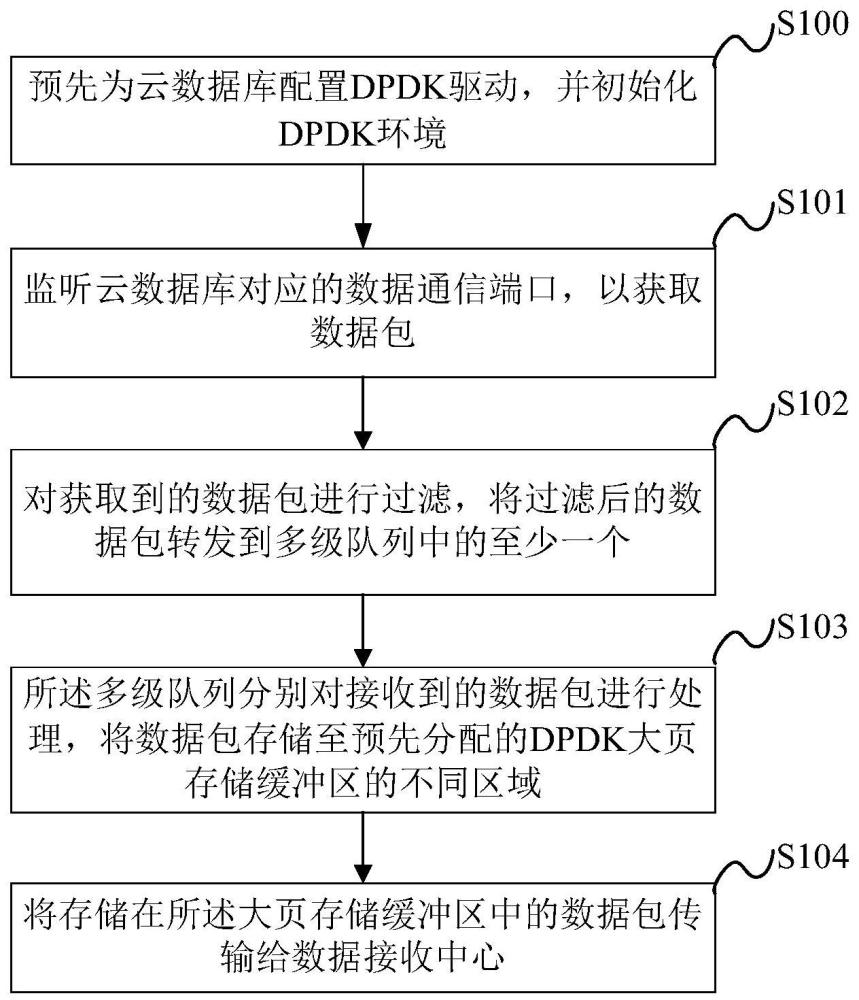
2、第一方面,本技术提供了一种全量sql数据采集方法,预先为云数据库配置dpdk驱动,并初始化dpdk环境;所述方法包括:
3、监听云数据库对应的数据通信端口,以获取数据包;
4、对获取到的数据包进行过滤,将过滤后的数据包转发到多级队列中的至少一个;
5、所述多级队列分别对接收到的数据包进行处理,将数据包存储至预先分配的dpdk大页存储缓冲区的不同区域;
6、将存储在所述大页存储缓冲区中的数据包传输给数据接收中心。
7、可选地,所述预先为云数据库配置dpdk驱动,并初始化dpdk环境包括:
8、在dpdk中配置rss分流策略,以依据所述rss分流策略将数据包转发到多级队列中的至少一个;
9、设置接收数据包的多级队列的数量,设置大页存储缓冲区的内存分配,将数据库的数据通信端口绑定dpdk的uio协议栈。
10、可选地,所述设置大页存储缓冲区的内存分配包括:
11、按照预设初始比例将所述大页存储缓冲区划分为普通缓冲区以及大sql缓冲区,其中所述大sql缓冲区的页大小大于所述普通缓冲区的页大小,并且所述普通缓冲区以及所述大sql缓冲区的内存分配支持动态调整。
12、可选地,所述多级队列至少包括一级接收队列以及二级处理队列;所述二级处理队列包括会话信息队列以及大sql处理队列;
13、所述对获取到的数据包进行过滤,将过滤后的数据包转发到多级队列中的至少一个包括:
14、根据协议类型进行判断,判断获取到的数据包是否为tcp协议的数据包,如果是则接收;如果否,则丢弃;
15、对于tcp协议的数据包,判断是否为tcp连接过程中产生的无效包;如果是无效包且不包含数据库会话信息,则丢弃;如果是无效包且包含数据库会话信息,则将数据包转发至二级处理队列的会话信息队列;
16、如果获取到的数据包是超过预设阈值的大sql数据包,则将数据包转发至二级处理队列的大sql处理队列;
17、对于不符合上述条件的其他数据包,则进入一级接收队列。
18、可选地,所述多级队列分别对接收到的数据包进行处理,将数据包存储至预先分配的dpdk大页存储缓冲区的不同区域包括:
19、所述会话信息队列对接收的会话信息数据除重复后存入普通缓冲区;
20、所述大sql处理队列将数据包存入大sql缓冲区;
21、所述一级接收队列将有效的普通数据包缓存至所述普通缓冲区。
22、可选地,在所述将存储在所述大页存储缓冲区中的数据包传输给数据接收中心之后还包括:
23、所述数据接收中心将接收到的数据包分发至分布式处理集群,以便所述分布式处理集群进行数据处理后,将处理后的数据存储至数据库。
24、可选地,所述数据接收中心将接收到的数据包分发至分布式处理集群包括:
25、针对大sql数据包,基于dpdk的分片功能对大sql数据包进行分片传输,由所述数据接收中心统一分发至预先指定的一组分布式处理集群进行重新组装、处理和/或压缩。
26、可选地,所述分布式处理集群进行数据处理后,将处理后的数据存储至数据库包括:
27、所述分布式处理集群对采集的数据包进行解析,获取sql执行语句、创建时间、执行耗时与来源信息,并进行结构化处理;
28、使用通配符对sql语句中的除sql关键字以外的用户数据进行替代,得到脱敏之后的数据;
29、将处理后的数据存储至数据库。
30、第二方面,本技术提供了一种全量sql数据采集装置,包括:
31、预设置模块,被配置为预先为云数据库配置dpdk驱动,并初始化dpdk环境;
32、监听模块,被配置为监听云数据库对应的数据通信端口,以获取数据包;
33、过滤模块,被配置为对获取到的数据包进行过滤,将过滤后的数据包转发到多级队列中的至少一个;
34、多级队列处理模块,所述多级队列分别对接收到的数据包进行处理,将数据包存储至预先分配的dpdk大页存储缓冲区的不同区域;
35、传输模块,被配置为将存储在所述大页存储缓冲区中的数据包传输给数据接收中心。
36、第三方面,本技术提供了一种全量sql数据采集系统,包括:
37、至少一个处理器;以及
38、存储有计算机程序的至少一个存储器;
39、其中,当所述计算机程序由所述至少一个处理器执行时,使得所述全量sql数据采集系统执行根据上述任一种所述的全量sql数据采集方法的步骤。
40、本发明有益效果如下:
41、本发明所述的全量sql数据采集方法,通过预先为云数据库配置dpdk驱动,并初始化dpdk环境;监听云数据库对应的数据通信端口,以获取数据包;对获取到的数据包进行过滤,将过滤后的数据包转发到多级队列中的至少一个;多级队列分别对接收到的数据包进行处理,将数据包存储至预先分配的dpdk大页存储缓冲区的不同区域;将存储在所述大页存储缓冲区中的数据包传输给数据接收中心。本技术利用dpdk提供的多队列抓包能力,可基于uio协议直接在用户态抓取数据,避免中断开销,具有极高的实时性,对实时数据治理意义重大,且dpdk依赖于cpu和内存,在前期资源合理分配的情况下,对数据库本身只有极低的性能损耗,从而提供高实时、低损耗、高效率的全量sql数据采集方案。
42、此外,本技术还提供了一种具有上述技术效果的全量sql数据采集装置及系统。