一种面向电子证照防伪的生成式隐写方法
本发明属于信息隐藏,涉及一种面向电子证照防伪的生成式隐写方法。
背景技术:
1、隐写术(steganography)又被称为信息隐藏技术,是指不让除预期的接收者之外的人知晓信息的传递事件或者信息的内容,生成式隐写技术是利用秘密信息直接生成含密载体的信息隐藏技术。为了在离线场景下进行电子证照的防伪鉴定,我们引入生成式隐写技术,为每份电子证照生成独一无二的防伪标识。通过专配套软件或设备来识读防伪标识,我们不仅可以轻松验证证件真伪,还能在无网络条件下直接获取可信的证照信息,提高电子证照管理和应用水平。当我们利用证照信息作为秘密数据、图像作为含密载体时,便可以利用生成式隐写技术产出的含密图像作为电子证照防伪标识。防伪标识可以附加于电子证照图像、纸质版证照、电子版式证照文件上,也可以单独使用。含密图像可以起到实体证件中芯片的作用,能够安全存储少量证照关键信息,供设备在离线状态下自动读取识别。
2、去噪扩散隐式模型(denoising diffusion implicit model, ddim)是扩散模型的一种,在图像生成领域得到广泛应用。通过对于训练集中的图片逐步添加高斯噪声,再学习去除噪声的过程,最终能够从纯高斯噪声出发,生成高质量的图像。ddim具有确定性,即对于每个确定的输入,其输出是唯一的。尽管还原的噪声存在误差,但人们总是可以通过反采样过程,还原出图像对应的噪声。
3、现有技术中,专利文献cn116456037b提供一种基于扩散模型的生成式图像隐写方法,使用ddim并提供了由二进制消息生成图像的方法,通过将不同的二进制序列映射到不同区间内的随机数形成从秘密消息到潜在噪音的映射;然而,由于ddim本身要求输入的潜变量是高斯噪声,所以不宜直接将秘密消息作为潜在噪声输入模型,存在生成图像质量下降的隐忧。此外,该方法还需要单独训练与生成与扩散模型相同架构的提取网络用于提取秘密消息,没有充分利用ddim本身的特性可逆性。
技术实现思路
1、鉴于此,为解决现有技术中存在的问题,本发明第一方面提供了一种面向电子证照防伪的生成式隐写方法,能够解决现有技术中经模型处理后的图像质量下降以及模型本身可逆性没有得到充分利用的技术问题。
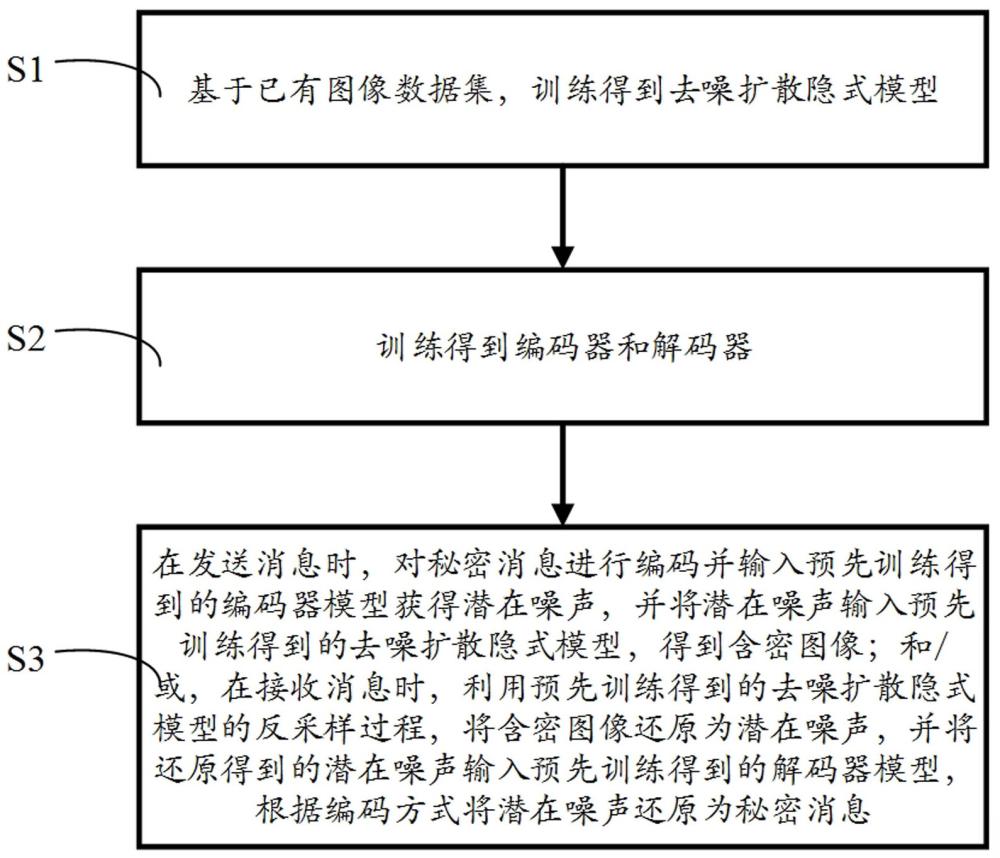
2、为实现上述效果,本发明提供一种面向电子证照防伪的生成式隐写方法,包括如下步骤:在发送消息时,对秘密消息进行编码并输入预先训练得到的编码器模型获得潜在噪声,并将潜在噪声输入预先训练得到的去噪扩散隐式模型,得到含密图像;和/或,在接收消息时,利用预先训练得到的去噪扩散隐式模型的反采样过程,将含密图像还原为潜在噪声,并将还原得到的潜在噪声输入预先训练得到的解码器模型,根据编码方式将潜在噪声还原为秘密消息。
3、可选地,预先训练得到的去噪扩散隐式模型包括基于已有数据集,训练得到去噪扩散隐式模型具体包括:准备足够数量的图像数据组成数据集;预先定义去噪扩散隐式模型和噪声数列;基于从所述数据集中选取的原图,以及预先定义的所述去噪扩散隐式模型和噪声数列,训练得到能够由输入的潜在噪声生成图像和/或能够将图像还原为潜在噪声并输出的去噪扩散隐式模型。
4、可选地,所述预先定义去噪扩散隐式模型和噪声数列具体包括:预先定义去噪扩散隐式模型,其中表示时间步时的图像,为神经网络参数;预先定义噪声数列,其中为向训练集中图像逐步添加噪声过程中时间步所添加噪声的方差,为最大时间步,满足;对于时间步,定义系数。
5、可选地,所述基于从所述数据集中选取的原图,以及所述预先定义的去噪扩散隐式模型和噪声数列,训练得到能够由输入的潜在噪声生成图像和/或能够将图像还原为潜在噪声并输出的去噪扩散隐式模型,具体包括:s131:从数据集中选取一张原图,并随机生成一个高斯噪声,随机选取时间步;s132:计算时间步添加噪声后的图像,随后将和输入模型,得到对于高斯噪声的估计的去噪扩散隐式模型;s133:针对s132中的估计的去噪扩散隐式模型,计算损失 ,采用梯度下降法更新神经网络参数,将损失更新为 ,其中为学习率,为损失函数对于的梯度;s134:重复上述步骤s131-s133,直到损失足够小或达到设定迭代次数,获得训练完成的去噪扩散隐式模型。
6、可选地,所述将潜在噪声输入预先训练得到的去噪扩散隐式模型,得到含密图像具体包括:根据训练完成的去噪扩散隐式模型采样生成含密图像,过程为:
7、针对潜在噪声张量,使用下面的公式逐步生成含密图像:
8、
9、即为输出的含密图像,将上述过程定义为,其含义为潜在噪声张量借助模型生成的含密图像。
10、可选地,所述利用预先训练得到的去噪扩散隐式模型的反采样过程,将含密图像还原为潜在噪声具体包括:由训练完成的去噪扩散隐式模型将含密图像还原,过程为:对于含密图像,使用下面的公式逐步还原:
11、
12、最后的即为潜在噪声张量,将上述过程定义为,其含义为由含密图像借助模型还原的含密图像或潜在噪声张量。
13、可选地,所述预先训练得到的编码器模型和预先训练得到的解码器模型具体包括:预定义编码器模型和解码器模型,并对预定义的所述编码器模型和解码器模型进行训练;定义损失函数,并根据计算损失更新编码器模型和解码器模型参数。
14、可选地,预定义编码器模型和解码器模型,并对预定义的所述编码器模型和解码器模型进行训练具体包括:定义编码器为,解码器为,并分别确定其结构,其中代表二进制的秘密消息,代表潜在噪声,编码器和解码器采用适用于图像处理的神经网络结构;定义单个图像的二进制容量为,生成长度为的二进制序列或长度小于但不足部分用0填充的二进制序列,并将该二进制数列定义为秘密消息;将被定义的二进制秘密消息输入编码器获取潜在噪声,再将潜在噪声依次输入图像生成过程及噪声还原过程,得到提取出的秘密消息。可选地,定义损失函数,并根据计算损失更新编码器模型和解码器模型参数具体包括:定义损失函数为,其中编码误差用于衡量潜在噪声与高斯白噪声的相似程度,解码误差用于衡量提取出的秘密消息与原秘密消息的相似程度;根据损失函数计算结果,使用梯度下降法同步更新编码器模型和解码器模型参数。
15、可选地,所述编码误差、解码误差被定义为:
16、
17、
18、其中,是展开为向量后各个位置的分量,是展开为向量后的维度,是向量各分量的均值,这里的第一部分是shapiro-wilk检验的统计量,是shapiro-wilk检验中的常数;的第二部分是一阶的自相关系数。
19、本发明第二方面提供了一种虚拟装置,包括消息发送模块和消息接收模块;所述消息发送模块用于在发送消息时,对秘密消息进行编码并输入预先训练得到的编码器模型获得潜在噪声,并将潜在噪声输入预先训练得到的去噪扩散隐式模型,得到含密图像;和/或,所述消息接收模块用于在接收消息时,利用预先训练得到的去噪扩散隐式模型的反采样过程,将含密图像还原为潜在噪声,并将还原得到的潜在噪声输入预先训练得到的解码器模型,根据编码方式将潜在噪声还原为秘密消息。
20、可选地,所述装置还包括训练模块,用于基于已有数据集,训练得到去噪扩散隐式模型;具体包括:准备足够数量的图像数据组成数据集;预先定义去噪扩散隐式模型和噪声数列;基于从所述数据集中选取的原图,以及预先定义的所述去噪扩散隐式模型和噪声数列,训练得到能够由输入的潜在噪声生成图像和/或能够将图像还原为潜在噪声并输出的去噪扩散隐式模型。
21、可选地,所述训练模块,具体用于:预先定义去噪扩散隐式模型 ,其中表示时间步时的图像,为神经网络参数;预先定义噪声数列,其中为向训练集中图像逐步添加噪声过程中时间步所添加噪声的方差,为最大时间步,满足;对于时间步,定义系数。
22、可选地,所述训练模块,具体用于:从数据集中选取一张原图,并随机生成一个高斯噪声,随机选取时间步;计算时间步添加噪声后的图像,随后将和输入模型,得到对于高斯噪声的估计的去噪扩散隐式模型;针对所述估计的去噪扩散隐式模型,计算损失 ,采用梯度下降法更新神经网络参数,将损失更新为 ,其中为学习率,为损失函数对于的梯度;重复上述过程,直到损失足够小或达到设定迭代次数,获得训练完成的去噪扩散隐式模型。
23、可选地,所述消息发送模块具体用于:
24、根据训练完成的去噪扩散隐式模型采样生成含密图像,过程为:
25、针对潜在噪声张量,使用下面的公式逐步生成含密图像:
26、
27、即为输出的含密图像,将上述过程定义为,其含义为潜在噪声张量借助模型生成的含密图像。
28、可选地,所述消息接收模块具体用于:
29、由训练完成的去噪扩散隐式模型将含密图像还原,过程为:
30、对于含密图像,使用下面的公式逐步还原:
31、
32、最后的即为潜在噪声张量,将上述过程定义为,其含义为由含密图像借助模型还原的含密图像或潜在噪声张量。
33、可选地,所述训练模块,还用于:预定义编码器模型和解码器模型,并对预定义的所述编码器模型和解码器模型进行训练;定义损失函数,并根据计算损失更新编码器模型和解码器模型参数。
34、可选地,所述训练模块,具体用于:
35、定义编码器为,解码器为,并分别确定其结构,其中代表二进制的秘密消息,代表潜在噪声,编码器和解码器采用适用于图像处理的神经网络结构;
36、定义单个图像的二进制容量为,生成长度为的二进制序列或长度小于但不足部分用0填充的二进制序列,并将该二进制数列定义为秘密消息;
37、将被定义的二进制秘密消息输入编码器获取潜在噪声,再将潜在噪声依次输入图像生成过程及噪声还原过程,得到提取出的秘密消息。
38、可选地,所述训练模块,具体用于:
39、定义损失函数为,其中编码误差用于衡量潜在噪声与高斯白噪声的相似程度,解码误差用于衡量提取出的秘密消息与原秘密消息的相似程度;
40、根据损失函数计算结果,使用梯度下降法同步更新编码器模型和解码器模型参数。
41、可选地,所述训练模块,具体用于:
42、所述编码误差、解码误差被定义为:
43、
44、
45、其中,是展开为向量后各个位置的分量,是展开为向量后的维度,是向量各分量的均值,这里的第一部分是shapiro-wilk检验的统计量,是shapiro-wilk检验中的常数;的第二部分是一阶的自相关系数。
46、本发明第三方面提供了一种电子设备,包括存储器和处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时,实现上述面向电子证照防伪的生成式隐写方法。
47、本发明第四方面提供了一种计算机存储介质,所述计算机存储介质上存储计算机程序,所述计算机程序被处理器执行时,实现上述面向电子证照防伪的生成式隐写方法。
48、本发明地有益效果为:通过分别训练得到可以利用高斯噪声生成图像的ddim模型,以及基于深度神经网络的编码器和解码器模型,利用ddim模型的可逆性(反采样),在简化训练模型的同时,实现了秘密消息的准确提取。
49、此外,本发明的附加优点、目的,以及特征将在下面的描述中部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本发明的实践而获知。本发明的目的和其它优点可以通过在书面说明及其权利要求书以及附图中具体指出的结构及方法步骤实现并获得。
50、本领域技术人员将会理解的是,能够用本发明实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本发明能够实现的上述和其他目的。
- 还没有人留言评论。精彩留言会获得点赞!