基于GCN-DDPG的超密集物联网资源分配方法及系统
本发明涉及d2d辅助的超密集物联网,尤其涉及基于gcn-ddpg的超密集物联网资源分配方法及系统。
背景技术:
1、随着无线通信技术的发展,万物互联(ioe,internet of everything)迅速发展,万物互联的设备(ioed,internet ofeverything devices)数量激增,这意味着物联网在未来会演变为超密集物联网(ud-ioe,ultra-dense internet of everything),并会面临网络吞吐量和频谱资源利用率有限等挑战。设备到设备(d2d,device-to-device)通信方式可用于缓解ud-ioe中网络吞吐量和资源利用率有限等挑战。d2d通信支持两个ioed之间直接通信,并在两个设备之间共享资源。然而,当ioed间通信范围交叠且采用同一信道进行传输时,将会出现严重的干扰现象。因此,在d2d辅助的ud-ioe中,必须依靠有效的资源管理管理方法,既保障网络性能,又避免严重干扰。
2、针对d2d辅助的ud-ioe资源管理,现有研究多关注于网络吞吐量性能,且多采用最优化方法建立优化模型并求解。然而,上述方法高度依赖于优化模型的准确性且计算量随网络规模极速增长,难以适用于拥有海量ioe设备的超密集环境。
3、随着人工智能(ai,artificial intelligence)的发展,机器学习已经成为处理大量数据、高计算任务和数学上复杂的非线性非凸问题的非常有效的技术。目前,越来越多的研究人员将强化学习应用于无线通信系统的资源管理和分配。但是,现有研究并未考虑超密集物联网密集部署场景下的海量隐藏终端干扰的问题。在超密集物联网中,海量ioed密集部署使得终端间通信范围密集交叠覆盖,导致大量潜在隐藏终端干扰,极大提高了资源复用冲突可能性,严重增加了超密集物联网中资源管理的难度。
技术实现思路
1、本发明提供基于gcn-ddpg的超密集物联网资源分配方法及系统,解决的技术问题在于:如何有效地避免d2d辅助的ud-ioe中的通信链路之间的资源冲突。
2、为解决以上技术问题,本发明提供基于gcn-ddpg的超密集物联网资源分配方法,包括步骤:
3、s1、构建超密集物联网的通信模型;
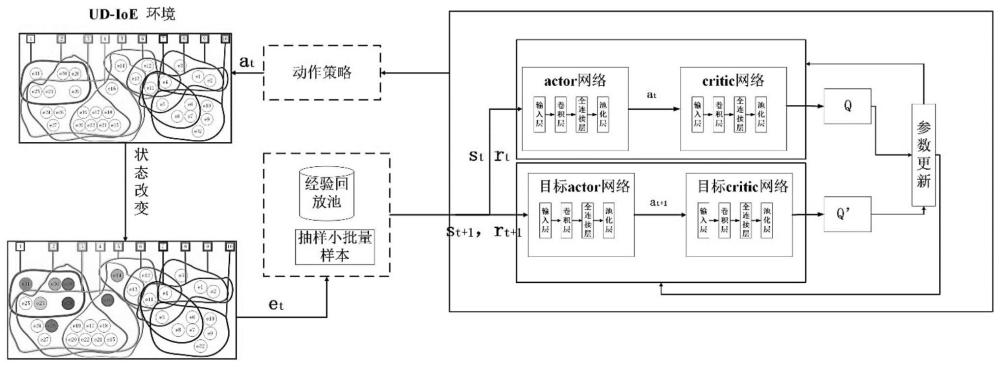
4、所述通信模型包括d2d辅助的ud-ioe层和bbu池,其中d2d表示端对端,ud-ioe表示超密集物联网,bbu表示基带单元,所述ud-ioe层包括n个ioed、m条通信链路和多个rrh,ioed表示物联网设备,rrh表示射频拉远头;每个rrh通过高速前传链路连接到bbu池,负责提供基本覆盖和辅助接入;ioed采用d2d通信模式,并且根据多跳通信链路扩大通信范围,最后通过ud-ioe层的rrh连接bbu池;由bbu和计算服务器组成的bbu池收集网络中的所有环境信息,并将资源分配给通信链路;
5、s2、根据所述通信模型建立冲突图;
6、s3、根据极大团生成定理以及贪心算法求出所述冲突图中所有的极大团,并根据超边与极大团的关系,在保持顶点相邻关系不变的情况下,将所述冲突图简化为冲突超图;
7、s4、基于所述冲突超图采用基于图卷积神经网络的深度强化学习模型即gcn-ddpg模型对所述超密集物联网进行资源分配;
8、所述gcn-ddpg模型包括行动者网络和批判者网络;
9、在所述行动者网络中,构建两层图卷积神经网络,输入所述冲突超图的邻接矩阵和特征矩阵,特征矩阵为资源分配矩阵即顶点染色矩阵,然后得到节点特征,根据节点特征选取合适的颜色,即进行资源分配,得到着色后的特征矩阵;
10、在所述批判者网络中,构建两层图卷积神经网络,输入所述冲突超图的邻接矩阵和所述着色后的特征矩阵,输出一个节点特征,即对选取动作的评价。
11、进一步地,在所述步骤s4中,所述gcn-ddpg模型还包括行动者目标网络和批判者目标网络;
12、在训练过程中,将bbu池作为智能体,智能体将当前状态st输入进所述行动者网络中,得到动作at,智能体在环境中执行at=μ(st|θμ),μ()表示所述行动者网络,θμ表示所述行动者网络的参数,然后得到及时奖励rt并获得下一个状态st+1,并将(st,at,rt,st+1)存储在经验重放缓冲区用于进一步训练;当经验池存满,智能体随机选择nc个数据组成小批量数据,其中第n个数据的状态-动作(sn,an)的估计值q(sn,an|θq)由所述批判者网络得到,θq表示所述批判者网络的参数;
13、状态-动作(sn,an)的目标值由下式计算:
14、
15、其中,γ为折扣因子,表示所述批判者目标网络,表示所述批判者目标网络的参数,表示所述行动者目标网络,表示所述行动者目标网络的参数。
16、进一步地,通过最小化均方误差训练所述批判者网络,均方误差l(θq)由下式计算:
17、
18、通过梯度下降法更新所述批判者网络的参数;通过对l(θq)中θq求微分得到l(θq)的梯度。
19、进一步地,通过最大化环境状态初始分布的预期收益训练所述行动者网络,环境状态初始分布的预期收益j(θμ)由下式计算:
20、
21、通过梯度下降法更新所述行动者网络的参数;通过微分的链式法则计算得到j(θμ)的梯度;
22、更新所述批判者目标网络的参数和所述行动者目标网络的参数分别为更新后的所述批判者网络的参数和所述行动者网络的参数。
23、进一步地,在所述行动者网络或所述批判者网络中,所述图卷积神经网络的操作表示为:
24、f(x,a)=σ(arelu(axw0)w1)
25、其中,为简化形式自定义的矩阵a=a+i,a表示所述冲突超图的邻接矩阵,i表示单位矩阵,d=σjaij表示一个对角矩阵,aij表示a第i行第j列的元素,wk表示第k+1层的权值矩阵,k=0,1,σ(·)是一个激活函数,relu()表示relu激活函数,x表示特征矩阵。
26、进一步地,根据下式更新每一层中的节点hk:
27、
28、进一步地,所述冲突超图表示为gh={vh,eh},其中vh是顶点集,顶点表示通信链路,eh是超边集,超边表示通信链路之间的冲突关系,eh中的任一超边是vh的子集,超边中的顶点与其它顶点具有相同的关系,gh用关联矩阵h表示任一顶点v与任一超边e的关系,h的任一行任一列的元素h(v,e)取值如下:
29、
30、其中h(v,e)=1表示顶点v与超边e是关联的,即超边e包含顶点v。
31、进一步地,所述步骤s2具体包括步骤:
32、s21、建立所述通信模型的冲突图,所述冲突图表示为:
33、gc=(vc,ec)
34、其中vc={e1,e2,...,em}是表示通信链路的顶点的集合,ec是表示通信链路之间的资源冲突关系的边的集合,vc中的顶点和ec中的边之间的关系由邻接矩阵gc表示:
35、
36、其中邻接矩阵gc中第n行第m列的元素bnm=(en,em),取值如下:
37、
38、s22、简化邻接矩阵gc为:
39、
40、其中,表示将gc1的主对角线元素设置为0所得矩阵,gc1表示记录直接冲突的冲突图的邻接矩阵,i是单位矩阵,表示将gc2的主对角线元素设置为0,gc2表示记录隐藏终端冲突的冲突图的邻接矩阵;直接冲突是指两个通信链路同时使用相同的信道,并且具有相同的发送或接收ioed;隐藏终端冲突是指两个通信链路同时使用相同的信道,并且一个ioed对的发送或接收ioed在其他ioed对中的ioed的通信范围内。
41、本发明还提供一种基于gcn-ddpg的超密集物联网资源分配方法,其关键在于:包括处理模块,所述处理模块用于执行上述方法中所述的步骤s1~s4。
42、本发明提供的基于gcn-ddpg的超密集物联网资源分配方法及系统,通过构建冲突图模型来分析资源复用冲突关系,将冲突图模型转化为冲突超图模型同时分析多个传输链路(transmission link,tl)之间的冲突关系,并将资源分配问题转化到超图的顶点强着色问题。最后提出了基于图卷积强化学习算法的无冲突资源分配策略。具体而言,其有益效果在于:
43、1)针对d2d辅助的ud-ioe中的隐藏终端干扰问题,分析了tl之间的资源复用冲突关系并对tl之间的冲突类型进行分类。然后,基于ud-ioe层之间的资源冲突关系,建立了冲突图模型,并设计了一种矩阵变换的方法来构造冲突图,直观地反映了逻辑层之间的冲突关系。
44、2)针对冲突图模型不能同时分析多个tl之间的资源冲突,通过极大团和超图理论将冲突图模型转化为冲突超图,将无冲突资源分配问题转化为超图的顶点着色问题,并设计了一种计算超图着色的方法。
45、3)针对超图顶点着色问题,提出了一种基于图卷积的深度确定性策略梯度(gcn-ddpg)算法/模型。该算法采用了actor(行动者)-critic(批判者)网络学习d2d辅助的ud-ioe中资源分配过程,并根据经验回放池中的样本数据动态调整资源分配方案。在保证ud-ioe无冲突的情况下,实现了资源复用率的提高。仿真结果表明,该算法提高了ud-ioe的网络吞吐量。
46、4)仿真结果表明,gcn-ddpg具有较高的资源复用率和网络吞吐量。
- 还没有人留言评论。精彩留言会获得点赞!