面向MEC的基于全景视频视口预测的缓存方案及系统
本发明属于边缘缓存、全景视频流,具体涉及一种面向mec的基于全景视频视口预测的缓存方案及系统。
背景技术:
1、随着流媒体技术的日益完善,视频流媒体应用占据了网络流量的大部分,逐渐成为互联网的主流应用。目前,网络视频服务已成为互联网行业增长最快的业务之一。同时,随着互联网用户对视频流服务的需求不断增加,用户大规模并发的用户访问请求和高质量的服务需求给流媒体服务系统带来了巨大挑战。传统的集中式云计算架构无法满足流媒体服务用户的需求。在网络边缘存储内容并实现应用功能的新架构边缘计算,可以为视频流服务需求的快速增长和用户对服务质量要求的不断提高提供解决方案。
2、在传统网络中,移动用户请求的内容通常由内容提供商提供的远程内容服务器提供服务。当用户从远程服务器检索相同的流行内容时,远程服务器需要重复发送相同的文件,这可能会出现大量重复的流量,在网络高峰时期可能出现网络拥塞问题。而在移动边缘缓存网络中,利用移动边缘计算服务器提供的存储服务。利用视口预测技术,将流行的内容,和可能会被观看的视频瓦片缓存在离用户更近的位置,可以降低从内容服务器到边缘缓存节点的重复内容传输,有效缓解网络拥塞问题,内容检索的延迟和传输能耗也会有效降低。
3、然而,当前基于视口预测的缓存方案中,大多基于已知内容流行度去预测视口,缺乏内容流行度先验知识会造成流行度预测缺乏真实性及时效性,同时,预测视口的方法往往过于单一造成预测精度不高,导致边缘缓存内容选择的误判困难。另外,主动缓存的需求对于如何进行视频瓦片选择和缓存内容替换等提出了更高要求。
4、因此,本发明提出一种面向mec的基于全景视频视口预测的缓存方案及系统,解决当前基于视口预测的缓存方案的缺陷。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种面向mec的基于全景视频视口预测的缓存方案及系统,其目的在于通过引入视口融合预测技术,将视频内容特征,跨用户特征,单用户轨迹特征相结合,由lstm模型进行视口预测,避免由于缺乏内容内容流行度先验知识和特征单一带来的时效性低预测精度不高等问题;同时,通过对瓦片合理的选择和基于流行度的缓存内容替换保证缓存命中率和边缘服务器负载均衡。
2、为达到上述目的,本发明提供如下技术方案:
3、一种面向mec的基于全景视频视口预测的缓存方案及系统,具体包括以下步骤:
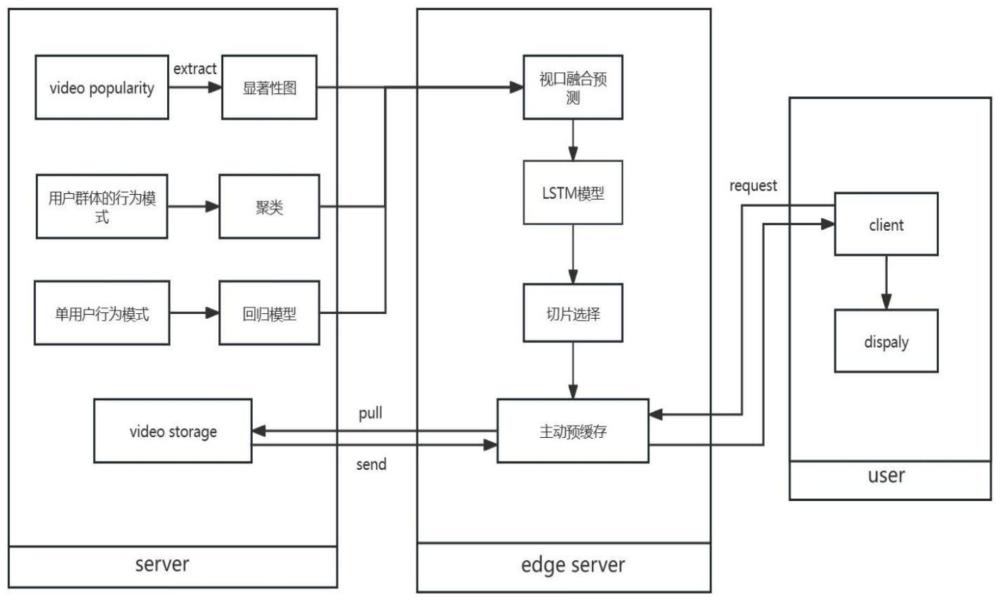
4、s1、由云存储服务器cs、边缘服务器es、数据请求者us共同构建缓存系统,并进行系统初始化;
5、s2、cs根据光流图和显著性图提取视频中感兴趣区域对应的内容特征,对用户群体的行为模式进行分组得到用户的观看特征,利用训练好的回归模型提取单用户历史轨迹特征,得到三方面输入特征;
6、s3、在es上基于lstm神经网络进行视口融合预测,得到每个瓦片的观看概率,并预测用户视口位置,从而选择观看概率较高的视频瓦片进行主动缓存;
7、s4、当es接收到us发来的视频数据请求时,通过es上的缓存机制来得到所请求视频瓦片;
8、进一步,所述步骤s1具体包括以下步骤:
9、s11、系统初始过程由cs将全景视频存储在缓存空间内,利用服务器资源对全景视频矩形投影(erp)到角度范围为180°×360°的二维视频平面中。并将其划分为n×m块;
10、s12、对es进行初始化,将es连接到网络,并确保其与其他设备的连接稳定,根据实际需求进行资源分配并设置缓存空间大小;
11、进一步,所述步骤s2具体包括以下步骤:
12、s21、在cs上提取视频中图像的内容特征,生成显著性图和光流图;
13、进一步,所述步骤s21具体包括以下步骤:
14、s211、利用视觉注意机制提取视频中各帧图像的感兴趣区域,得到显著性图;
15、显著性图通过观察w的大小来看出每个像素点对应的重要度的信息。设一个线性打分模型如下:
16、sc(i)≈wti+b
17、这个任务输入图像i0,类别为c,以及模型对该类的分数sc(i0),输出一个显著图w,也就是i0中每一个像素对于分数sc(i0)的影响力的排序。这里的w是打分函数sc在图像i0处对图像i的梯度:
18、
19、最后对整个网络进行方向传播可以计算得到w的值。
20、s212、利用光流法可以捕捉相邻两帧图像的运动特征,得到光流图;
21、基本约束方程如下,考虑一个像素i(x,y,t)在第一帧的光强度,它移动了(dx,dy)的距离到下一帧,用了dt时间,即:
22、i(x,y,t)=i(x+dx,y+dy,t+dt)
23、将上述公式右端进行泰勒展开,得:
24、
25、其中ε代表二阶无穷小项,可忽略不计,将泰勒展开后的代入约束方程消除dt得:
26、
27、设u,ν分别为光流分别为沿x轴与y轴的速度矢量,得:
28、
29、
30、令分别表示图像中像素点的灰度沿x,y,t方向的偏导数,综上可得:
31、ixu+iyν+it=0
32、其中,ix,iy,it均可由图像数据求得,而(u,v)即为所求光流矢量。
33、s213、对显著性图和光流图进行归一化处理后,计算视频每个瓦片内部像素值的均值,作为该瓦片在仅考虑视频内容情况下的观看概率,从而获得内容特征
34、s22、在cs上将视口中心点距离在阈值内的用户进行分组;
35、进一步,所述步骤s22具体包括以下步骤:
36、s221、通过kmeans进行用户中心聚类,如果用户视口中心点与聚类中心点的距离小于30°,则将该用户化归为这一组;
37、具体地,步骤二中通过kmeans进行用户中心聚类;定义用户u在t时刻的视口中心点为iu,t=(x,y),x、y分别横向偏航值和纵向俯仰值;考虑到视口的偏航值可以越过等距形投影的边界,需要将中心点的偏航值建模为连续的序列,计算两个用户视口中心点的欧式距离:
38、
39、其中i1,t,i2,t为两个用户t时刻的视口中心点;对于第i个组,其聚类中心为mt0,i若iu满足:
40、
41、即如果用户视口中心点与聚类中心点的距离小于30°,并持续△t的时间,则将该用户化归为这一组。
42、s222、为步骤s221得到的每一个用户分组计算其观看概率;
43、具体的,分组后得到每个用户所属组别、各组用户数和各组用户视口中心点。每组用户视口中心点对应一个区域,任意一组用户的观看概率为该组用户数除以总用户数;
44、具体的,在上述步骤中,如果多组用户对应的区域重叠,则重叠区域的观看概率为该多组用户对应区域的观看概率之和,进而计算视频每个瓦片的归一化观看概率,得到跨用户观看特征
45、s23、在cs上利用训练好的的回归模型预测单个用户的视口中心点得到用户历史轨迹特征,并计算出每个瓦片的观看概率;
46、进一步,所述步骤s23具体包括以下步骤:
47、s231、首先,需要对回归模型进行预训练。使用用户头部运动轨迹作为输入,预测出用户下一时刻的头部运动轨迹。在预测过程中,我们根据预测结果和实际观看结果对模型进行实时训练和更新,以获得用户历史轨迹特征
48、具体的,先获取视频中用户的位置信息,选择k个样本点作为训练数据。将每个样本点中每一帧的索引作为时间戳,模型以前m个采样点的坐标为输入,预测第m+1个采样点的坐标。将时间戳向后移动一位,重复以上步骤,直到预测出第k个采样点,完成一个epoch的训练。;
49、s232、在划分瓦片后,根据视频每块瓦片与预测得到用户视口中心点的距离计算每个瓦片的归一化观看概率;
50、进一步,所述步骤s3具体包括以下步骤:
51、s31、将步骤s2得到的特征输入到lstm网络,并设置lstm网络隐状态函数输出用户视点位置和瓦片观看概率分别表示为
52、进一步,所诉s31具体包括以下步骤:
53、s312、设置lstm网络隐状态函数输出用户视点位置和瓦片观看概率分别表示为
54、s313、设置lstm单元其中f为lstm单元的计算公式;
55、s314、输出层表达为其中g和k为输出层的激活函数;
56、s315、es根据输出结果,确定下一时刻可能会观看的视口位置并选择其观看概率较高的瓦片,进行主动预缓存;
57、进一步,所述步骤s4具体包括以下步骤:
58、s41、首先在其缓存查找所请求视频瓦片,如果存在就返回瓦片给us;
59、s42、否则,es将发送请求到cs,在cs中拉取被请求瓦片并发送给us,同时,返回的瓦片放置在es的缓存中;
60、s43、当es缓存空间满时,es根据视频瓦片的流行度(观看概率)来触发响应式缓存替换,以返回新的请求瓦片;
61、s44、当缓存满且需要将新瓦片放置在es上时,es先计算新瓦片及其缓存内容的本地流行度;
62、s45、es根据瓦片观看概率进行判断,如果新瓦片的本地流行度大于所有已缓存的瓦片本地流行度,则es将淘汰本地流行度最小的已缓存瓦片,以缓存新瓦片;
63、s46、否则,es将放弃缓存新瓦片;
- 还没有人留言评论。精彩留言会获得点赞!