一种基于双重深度强化学习的算力分发网络在线调度方法与流程
本发明属于算力分发调度的,具体涉及一种基于双重深度强化学习的算力分发网络在线调度方法。
背景技术:
1、随着云计算的快速发展,越来越多的用户选择使用云计算平台来满足自身的计算需求。云计算平台的资源利用率和用户体验是其运营过程中需要考虑的两个关键因素。在高峰期,云计算平台的资源利用率不高,用户等待时间长,影响用户体验。因此,如何高效地分配集群资源,降低用户等待时间,提高资源利用率成为云计算平台面临的重要问题。
2、传统的调度方法通常基于静态规则或简单的启发式算法,缺乏自适应性和动态性,难以适应不同的负载需求和应对复杂的环境变化。
3、强化学习作为一种免模型的决策算法,能更好的应对各种决策问题。此类方法将算力调度问题转化为数据驱动的序列决策问题,能够根据当下环境状态实现在线决策。深度强化学习将深度学习和强化学习相结合,使用深度神经网络来处理模型的输入和输出,可以更好地处理算力分发调度的各种复杂的环境和场景。双重深度强化学习是深度强化学习的扩展,用于解决其过度估计问题,提高模型性能。
4、如申请公开号为cn115129463a的专利公开了一种算力调度方法及装置、系统及存储介质,该方法包括:若当前的工作模式为推理模式,则执行以下操作:获取目标算力设备群中各算力设备的算力权重信息;根据所述各算力设备的算力权重信息确定任务分配顺序;以及根据所述任务分配顺序信息将任务流中各任务依次分配给所述目标算力设备群中相应算力设备。通过上述算力调度方法可以解决现有技术中存在的部分算力设备为等待另一部分算力设备计算完成而处于空闲状态导致计算资源浪费的问题,通过算力设备的实时算力属性动态分配任务,有效的利用每个设备的计算能力。
5、如申请公开号为cn114003370a的专利公开了一种算力调度方法以及相关装置,该方法包括:获取待创建任务的类型、以及算力卡集合中包含第一类型的任务的第一算力卡子集合;其中,待创建任务的类型为第一类型;响应于第一算力卡子集合中包括满足预设条件的目标算力卡,在目标算力卡上创建待创建任务。通过这种设计方式,相同类型的任务能够尽量创建在同一张算力卡上,不仅算力卡的内存利用率和cnn算力使用率能够得到提升,从而可以使得算力卡的剩余资源利用率得到提升,而且节省了首次创建任务需要的额外内存消耗。
6、以上专利都存在本背景技术提出的问题:调度准确率低、调度稳定性差、资源利用效率低等问题。
7、公开于该背景技术部分的信息仅仅旨在增加对本发明的总体背景的理解,而不应当被视为承认或以任何形式暗示该信息构成已为本领域普通技术人员所公知的现有技术。
技术实现思路
1、本发明所要解决的技术问题是克服现有技术的缺陷,提供一种基于双重深度强化学习的算力分发网络在线调度方法,通过自适应学习以满足不同网络环境的算力调度策略生成方法,实现更高效准确的资源分配和调度。
2、为解决上述技术问题,本发明提供如下技术方案:
3、一种基于双重深度强化学习的算力分发网络在线调度方法,包括以下步骤:
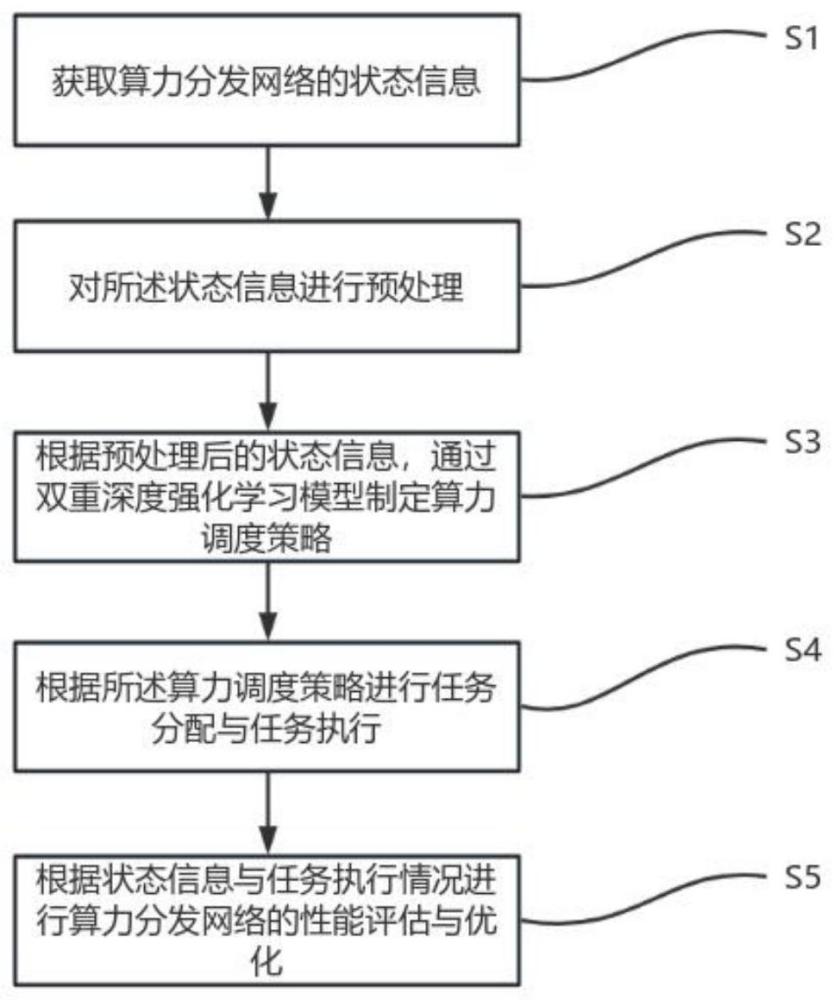
4、s1:获取算力分发网络的状态信息;
5、s2:对所述状态信息进行预处理;
6、s3:根据预处理后的状态信息,通过双重深度强化学习模型制定算力调度策略;
7、s4:根据所述算力调度策略进行任务分配与任务执行;
8、s5:根据状态信息与任务执行情况进行算力分发网络的性能评估与优化。
9、作为本发明所述基于双重深度强化学习的算力分发网络在线调度方法的一种优选方案,其中:所述状态信息包括任务状态信息、网络状态信息和节点状态信息;其中:
10、网络状态信息包括网络的带宽、延迟、丢包率、全局静态算力、网络拓扑结构;
11、节点状态信息包括节点的cpu使用率、内存使用率、硬盘使用率、运行任务数量;
12、任务状态信息包括任务队列信息、每个任务的类型、每个任务所需资源大小、每个任务的优先级。
13、作为本发明所述基于双重深度强化学习的算力分发网络在线调度方法的一种优选方案,其中:所述预处理包括数据清洗,以及将所述状态信息转换为特征向量。
14、作为本发明所述基于双重深度强化学习的算力分发网络在线调度方法的一种优选方案,其中:所述算力调度策略的内容是为任务队列中每个任务分配执行节点和执行顺序;制定算力调度策略的方法为马尔科夫决策,方法如下:
15、定义网络状态集、未执行动作集、奖励函数和状态转移函数;其中,所述网络状态集中的任一网络状态为所述状态信息组成的矩阵;任一节点执行任一任务为所述未执行动作集合中的一个动作;每执行一个动作后,通过所述状态转移函数更新网络状态,并通过所述奖励函数计算累计奖励,然后从未执行动作集中移除已执行的动作;
16、将任一时刻的网络状态、未执行动作集合、累计奖励作为一个样本,存储到经验回放内存中,通过双重深度强化学习模型来制定累计奖励最大的算力调度策略。
17、作为本发明所述基于双重深度强化学习的算力分发网络在线调度方法的一种优选方案,其中:所述双重深度强化学习模型包括主网络和目标网络,其中,主网络和目标网络的输入均为网络状态;主网络的输出为当前网络状态下未执行动作集合中每个动作的动作价值函数;目标网络的输出为下一网络状态下未执行动作集合中每个动作的动作价值函数;所述动作价值函数为累计奖励的预测值。
18、作为本发明所述基于双重深度强化学习的算力分发网络在线调度方法的一种优选方案,其中:所述双重深度强化学习模型的训练方法如下:
19、s100:从经验回放内存中随机抽取n个样本,依次将每个样本输入主网络;
20、s200:通过主网络计算每个样本的动作价值;
21、s300:通过目标网络计算每个样本的目标动作价值;
22、s400:根据每个样本的动作价值和目标动作价值计算损失函数;
23、公式如下:
24、
25、其中,l表示损失函数;n为样本的数量;qt表示第t个样本的动作价值,表示第t个样本的目标动作价值;
26、s500:根据损失函数,通过反向传播算法更新主网络的参数;
27、s600:重复s100~s500,直至达到最大迭代次数;
28、每进行一次迭代,对主网络参数进行测试评估,并保存主网络参数和评估结果;当达到最大迭代次数后,将评估结果最优的主网络部署应用于算力分发调度网络;
29、目标网络的参数更新方式为:主网络每进行m次迭代,将参数复制给目标网络。
30、作为本发明所述基于双重深度强化学习的算力分发网络在线调度方法的一种优选方案,其中:所述动作价值的计算方法如下:令任一样本当前的网络状态为st,计算当前网络状态下未执行动作集中每个动作的动作价值函数;选择最大的动作价值函数,记作qr,表示当前的动作价值;
31、将最大动作价值函数对应的动作,记作at;将执行at后更新的网络状态记作st+1。
32、作为本发明所述基于双重深度强化学习的算力分发网络在线调度方法的一种优选方案,其中:所述目标动作价值的计算方法如下:将更新后的网络状态st+1输入目标网络,目标网络计算st+1状态下的未执行动作集中每个动作的动作价值函数;选择最大的动作价值函数,记作qt+1;计算目标动作价值,公式如下:
33、
34、其中,表示目标动作价值;rt表示执行动作at的实际奖励,由奖励函数计算得到;α为定义好的折扣因子。
35、作为本发明所述基于双重深度强化学习的算力分发网络在线调度方法的一种优选方案,其中:所述节点在执行分配的任务时,监控并记录任务执行情况,包括任务进度、资源利用率、完成时间、异常情况、事件记录、任务结果。
36、作为本发明所述基于双重深度强化学习的算力分发网络在线调度方法的一种优选方案,其中:所述性能评估包括评价算力资源的充裕程度、算力分发网络的调度能力和算力分发网络的稳定性。
37、与现有技术相比,本发明所达到的有益效果如下:
38、通过双重深度强化学习的算力在线调度方法,可以实现对集群资源的智能分配,提高算力利用率,降低用户等待时间。与传统的启发式算法或者静态调度算法相比,本发明提出的方法更加适应复杂多变的网络环境和任务需求,提供了一种在线决策的调度策略生成方法,提高了算力分发网络的可靠性和精确性。实现了算力资源的均衡分配,避免因为某个节点的负载过高而出现瓶颈;现任务的动态调度和节点的适应性调整,提高了算力调度网络的可靠性。
- 还没有人留言评论。精彩留言会获得点赞!