流量监控方法及装置与流程
本技术涉及互联网,具体涉及一种流量监控方法及装置。
背景技术:
1、大模型即大规模语言模型,能够学习到更细微的模式和规律,具有更强的泛化能力和表达能力,其拥有巨量的参数,训练和推理需要很强的基础设施建设能力,如chatgpt。由于单一机器无法容纳巨量参数的大模型,一般采用分布式机器集群来进行训练和推理,其中高性能网络和集合通信是至关重要的一环。
2、现有技术中高性能网络的通信可以采用如rdma(remote direct memory access,远端直接内存访问)技术来实现,绕过操作系统内核的远端内存访问,在延迟、吞吐和cpu消耗等方面均有明显优势。集合通信库采用如英伟达官方开源的nccl(nvidia collectivecommunications library,nvidia集合通信库)软件库,完成多个gpu之间的显存数据的交换。但nccl软件库中缺少对gpu集合通信的监控。当gpu之间会通过多张rdma网卡同时进行通信时,同一个通信域流量会分散到不同的rdma网卡上,无法通过rdma网卡流量来区分某个通信域的流量;或者当大模型训练使用并行技术,即单个gpu并发在不同通信域执行不同的数据处理时,无法对多个并行通信域进行流量区分,无法及时察觉训练的瓶颈点等。
技术实现思路
1、鉴于上述问题,提出了本技术实施例以便提供一种克服上述问题或者至少部分地解决上述问题的流量监控方法及装置。
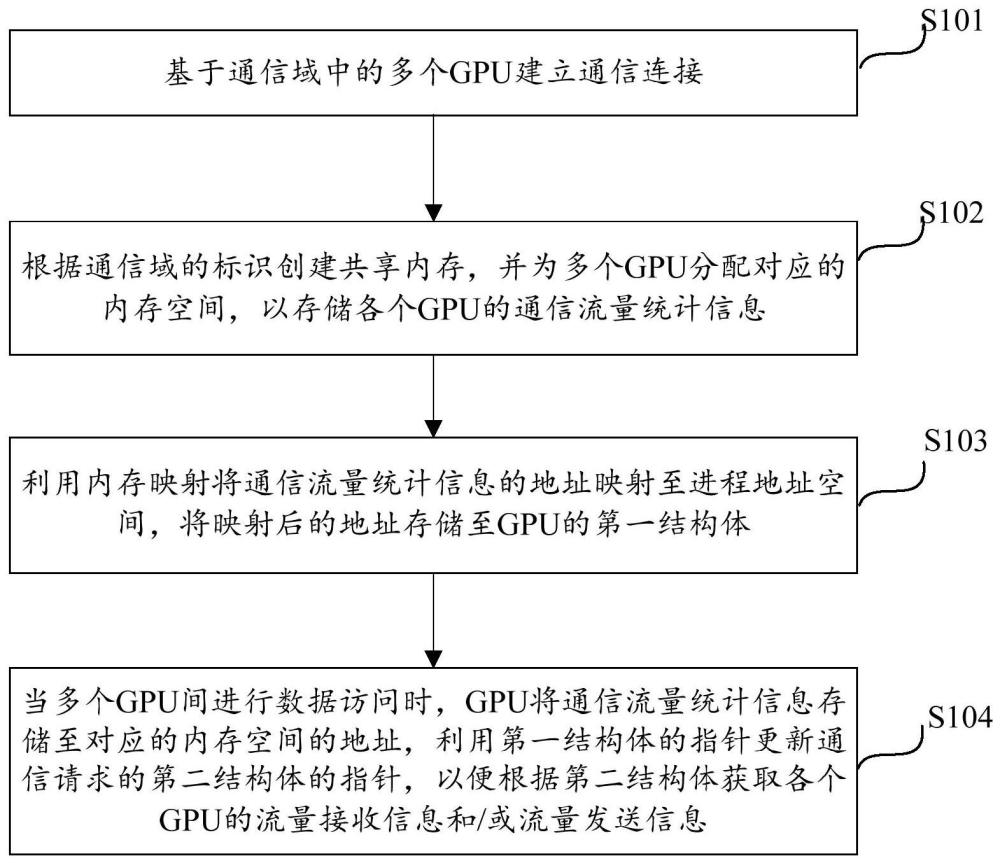
2、根据本技术实施例的第一方面,提供了一种流量监控方法,其包括:
3、基于通信域中的多个gpu建立通信连接;
4、根据通信域的标识创建共享内存,并为多个gpu分配对应的内存空间,以存储各个gpu的通信流量统计信息;通信流量统计信息包括流量接收信息和/或流量发送信息;
5、利用内存映射将通信流量统计信息的地址映射至进程地址空间,将映射后的地址存储至gpu的第一结构体;其中,第一结构体在通信连接时进行初始化,第一结构体以指针指向映射后的地址;
6、当多个gpu间进行数据访问时,gpu将通信流量统计信息存储至对应的内存空间的地址,利用第一结构体的指针更新通信请求的第二结构体的指针,以便根据第二结构体获取各个gpu的流量接收信息和/或流量发送信息。
7、可选地,多个gpu包括发送方gpu以及接收方gpu;第一结构体包括接收结构体和/或发送结构体;
8、基于通信域中的多个gpu建立通信连接进一步包括:
9、接收方gpu监听连接请求,当接收到发送方gpu发起的连接请求后,接收方gpu接受连接请求并建立通信连接,接收方gpu创建接收结构体,发送方gpu创建发送结构体;其中,发送方gpu及接收方gpu隶属同一通信域。
10、可选地,
11、内存空间的长度为预设字节长度;发送方gpu及接收方gpu的通信编号不同;
12、根据通信域的标识创建共享内存,并为多个gpu分配对应的内存空间,以存储各个gpu的通信流量统计信息进一步包括:
13、根据通信域的标识创建共享内存;
14、根据接收方gpu和发送方gpu的通信编号计算内存空间的偏移量,以确定为各个gpu分配内存空间的开始地址;
15、接收方gpu存储流量接收信息,发送方gpu存储流量发送信息。
16、可选地,利用内存映射将通信流量统计信息的地址映射至进程地址空间,将映射后的地址存储至gpu的第一结构体进一步包括:
17、利用内存映射将各个gpu的流量接收信息的地址映射至进程地址空间,将映射后的流量接收信息的地址存储至接收方gpu的接收结构体;
18、利用内存映射将各个gpu的流量发送信息的地址映射至进程地址空间,将映射后的流量发送信息的地址存储至发送方gpu的发送结构体。
19、可选地,方法还包括:
20、在第二结构体中增加接收指针以及发送指针。
21、可选地,当多个gpu间进行数据访问时,gpu将通信流量统计信息存储至对应的内存空间的地址,利用第一结构体的指针更新通信请求的第二结构体的指针,以便根据第二结构体获取各个gpu的流量接收信息和/或流量发送信息进一步包括:
22、当接收方gpu访问发送方gpu的数据时,发起接收请求并传递接收结构体,根据接收结构体的指针更新第二结构体中的接收指针;发送方gpu发起发送请求并传递发送结构体,根据发送结构体的指针更新第二结构体中的发送指针;
23、根据第二结构体的接收指针和/或发送指针确定各个gpu的流量接收信息和/或流量发送信息。
24、可选地,根据第二结构体获取各个gpu的流量接收信息和/或流量发送信息进一步包括:
25、根据第二结构体的接收指针和/或发送指针确定通信域中不同gpu的流量接收信息和/或流量发送信息;
26、或者,根据第二结构体的接收指针和/或发送指针,统计同一分布式节点下多个gpu的总流量接收信息和/或总流量发送信息;
27、或者,根据不同第二结构体的接收指针和/或发送指针,统计同一gpu中隶属不同通信域的流量接收信息和/或流量发送信息。
28、可选地,方法还包括:
29、预先配置通信域中的多个gpu的通信链路,以便多个gpu根据通信链路执行;通信链路包括建立通信连接、创建共享内存、分配内存空间、存储通信流量统计信息、映射地址存储至gpu的第一结构体。
30、根据本技术实施例的第二方面,提供了一种流量监控装置,其包括:
31、建立连接模块,适于基于通信域中的多个gpu建立通信连接;
32、共享内存模块,适于根据通信域的标识创建共享内存,并为多个gpu分配对应的内存空间,以存储各个gpu的通信流量统计信息;通信流量统计信息包括流量接收信息和/或流量发送信息;
33、地址存储模块,适于利用内存映射将通信流量统计信息的地址映射至进程地址空间,将映射后的地址存储至gpu的第一结构体;其中,第一结构体在通信连接时进行初始化,第一结构体以指针指向映射后的地址;
34、流量获取模块,适于当多个gpu间进行数据访问时,gpu将通信流量统计信息存储至对应的内存空间的地址,利用第一结构体的指针更新通信请求的第二结构体的指针,以便根据第二结构体获取各个gpu的流量接收信息和/或流量发送信息。
35、根据本技术实施例的第三方面,提供了一种计算设备,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
36、所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行上述流量监控方法对应的操作。
37、根据本技术实施例的第四方面,提供了一种计算机存储介质,所述存储介质中存储有至少一可执行指令,所述可执行指令使处理器执行如上述流量监控方法对应的操作。
38、根据本技术的提供的流量监控方法及装置,基于共享内存存储通信域中gpu的通信流量统计信息,将存储通信流量统计信息的地址映射后存储至第一结构体的指针,数据访问时根据第一结构体将其更新至第二结构体中,基于第二结构体可以从通信域粒度出发,实现对通信域进行流量监控,实现多任务并行时的流量监控,也进一步帮助监控、评估分布式集群用于如大模型训练时的网络性能、健康度等。
39、上述说明仅是本技术技术方案的概述,为了能够更清楚了解本技术的技术手段,而可依照说明书的内容予以实施,并且为了让本技术的上述和其它目的、特征和优点能够更明显易懂,以下特举本技术的具体实施方式。
- 还没有人留言评论。精彩留言会获得点赞!